OpenSearch
What is OpenSearch
OpenSearch is a distributed search and analytics engine that supports a variety of use cases, such as website search and security data analysis. Being distributed, it runs across multiple machines for scalability and high availability. It allows you to ingest, store, search, and analyze data of any type efficiently, making it ideal for use cases like logging, monitoring, and observability.
Key Features
Document
Document is a unit that stores data in JSON format. A document can be considered as a row in a table in a database.
For Example, a row in a student database might represent one student.
| ID | Name | Age | CGPA |
|---|---|---|---|
| 1 | John Doe | 24 | 3.57 |
{
"id": 1,
"name" : "John Doe",
"age" : 24,
"CGPA" : 3.57
}
Index
An index is a collection of documents. This is just like the table in a database. Like a table is a collection of rows, an index is a collection of related documents. Open Search allows you to enforce strict mappings to ensure data consistency and prevent unexpected field additions or type mismatches. When strict mapping is enabled, Open Search will reject any document that contains fields not defined in the mapping. It will also reject documents where the data type of field doesn't match the defined mapping.
{
"mappings": {
"dynamic": "strict",
"properties": {
"title": { "type": "text" },
"content": { "type": "text" },
"date": { "type": "date" }
}
}
}
Strict mapping prevents index pollution with unexpected fields, ensures data consistency across documents and helps maintain a clean and predictable index structure, but while strict mapping provides better control, it can be less flexible for evolving data structures. You may need to update your mapping if your data model changes.
Other alternatives in Open Search are :
dynamic: true (default): Automatically adds new fields to the mapping.dynamic: false: Ignores new fields but doesn't reject the document.dynamic: runtime: Accepts new fields as runtime fields without indexing them.
Shards
Open Search splits indexes into shards. Each shard stores a subset of all documents in an index. Key points about shards:
-
Definition: A shard is a subset of an index's data. It's a self-contained Lucene index that holds a portion of the documents belonging to an Open Search index.
-
Full Lucene Indexes: Each shard is actually a complete Lucene index in its own right, capable of indexing and searching documents independently.
-
Data Distribution: When you create an index in Open Search, the data is automatically divided into shards. This allows the data to be distributed across multiple nodes in a cluster.
-
Types of Shards:
-
Primary Shards: The main shards that hold the original set of data.
-
Replica Shards: Copies of primary shards for redundancy and improved read performance.
-
Scalability: Shards enable horizontal scalability. You can add more nodes to a cluster and redistribute shards across them to handle larger data volumes.
-
Parallelism: Queries can be executed in parallel across multiple shards, improving search performance.
How Shards Work with Documents
-
Document Integrity: A document is always stored in its entirety within a single shard. It's never split across multiple shards.
-
Shard Assignment: When a document is indexed, Open Search determines which shard it should be stored in, typically using a hash of the document's ID.
-
Document Location: A document will exist in full in one primary shard, and potentially in one or more replica shards (if replicas are configured).
The number of shards can impact performance and should be carefully planned based on your data volume and query patterns. While more shards can improve parallelism, too many shards can increase overhead and potentially degrade performance.
Types of Shards: Primary and Replica
Open Search uses two types of shards: primary shards and replica shards. Primary can only be set while creating index, and after that we cannot the primary shard value.
Primary Shards
-
Definition: Primary shards are the original shards of an index. They are the main shards that hold the original set of data.
-
Purpose: They are responsible for indexing new documents and handling update or delete operations.
-
Uniqueness: Each document in an index belongs to one and only one primary shard.
-
Configuration: The number of primary shards is set when an index is created and cannot be changed without reindexing.
Replica Shards
-
Definition: Replica shards are exact copies of primary shards.
-
Purpose: They serve two main purposes:
-
Provide high availability in case a primary shard fails.
-
Increase read throughput, as searches can be executed on replica shards in parallel.
-
Flexibility: The number of replica shards can be changed at any time without reindexing.
-
Distribution: Replica shards are never allocated to the same node as their corresponding primary shard.
How Primary and Replica Shards Work Together
-
Write Operations: All write operations (index, update, delete) go to the primary shard first, then are synchronized to replica shards.
-
Read Operations: Read operations can be served by either primary or replica shards, which helps in load balancing.
-
Failover: If a primary shard fails, one of its replicas is promoted to become the new primary shard.
-
Rebalancing: Open Search automatically rebalance shards across nodes to maintain even distribution.
How to create OpenSearch DBaaS
To proceed, click the "Get Started" button or the "Add" icon located in the upper-right corner of the screen, as illustrated in the following images:

After that, select the OpenSearch cluster and click on "Select Plan" to continue.
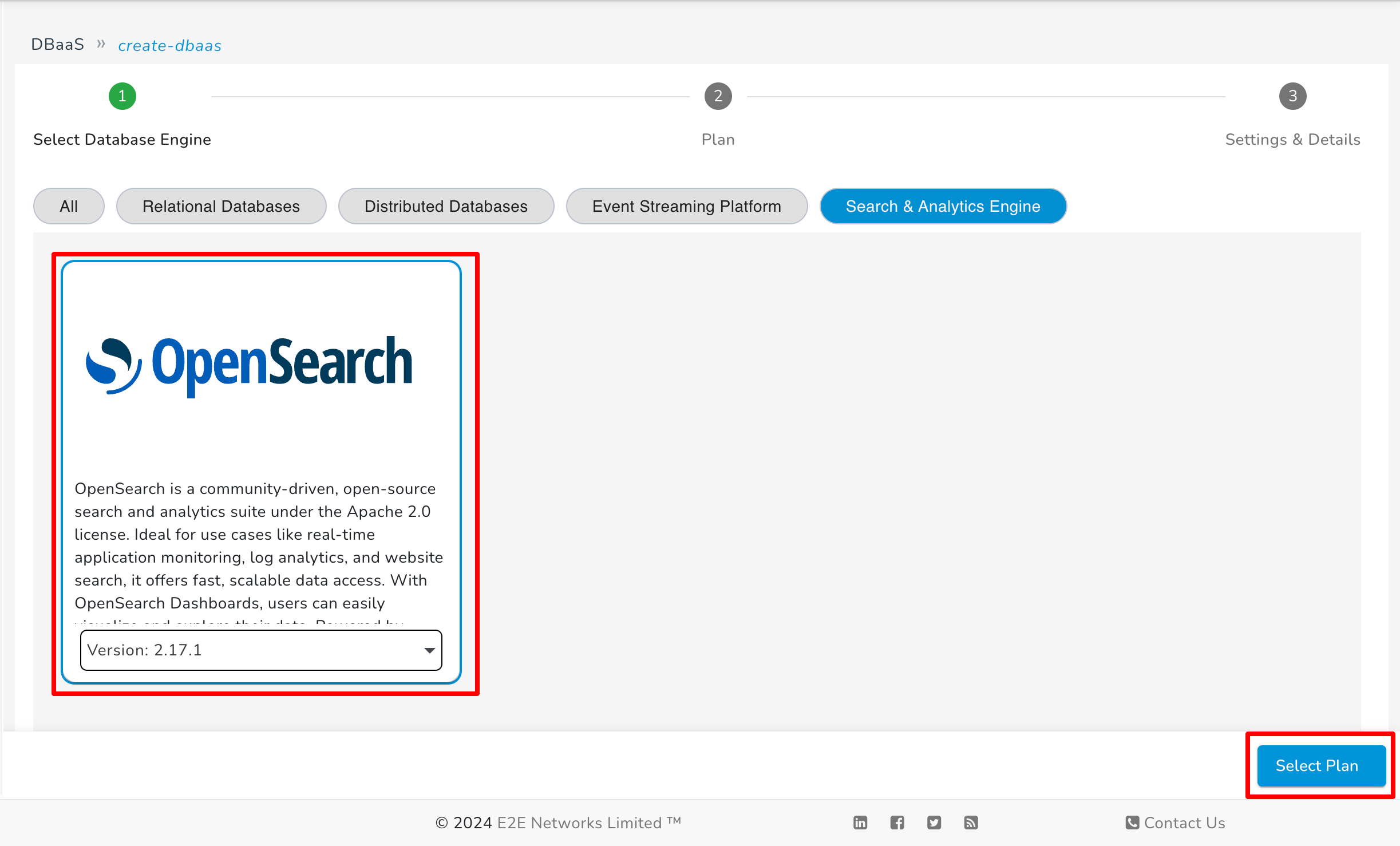
Now select the plan according to your requirement.
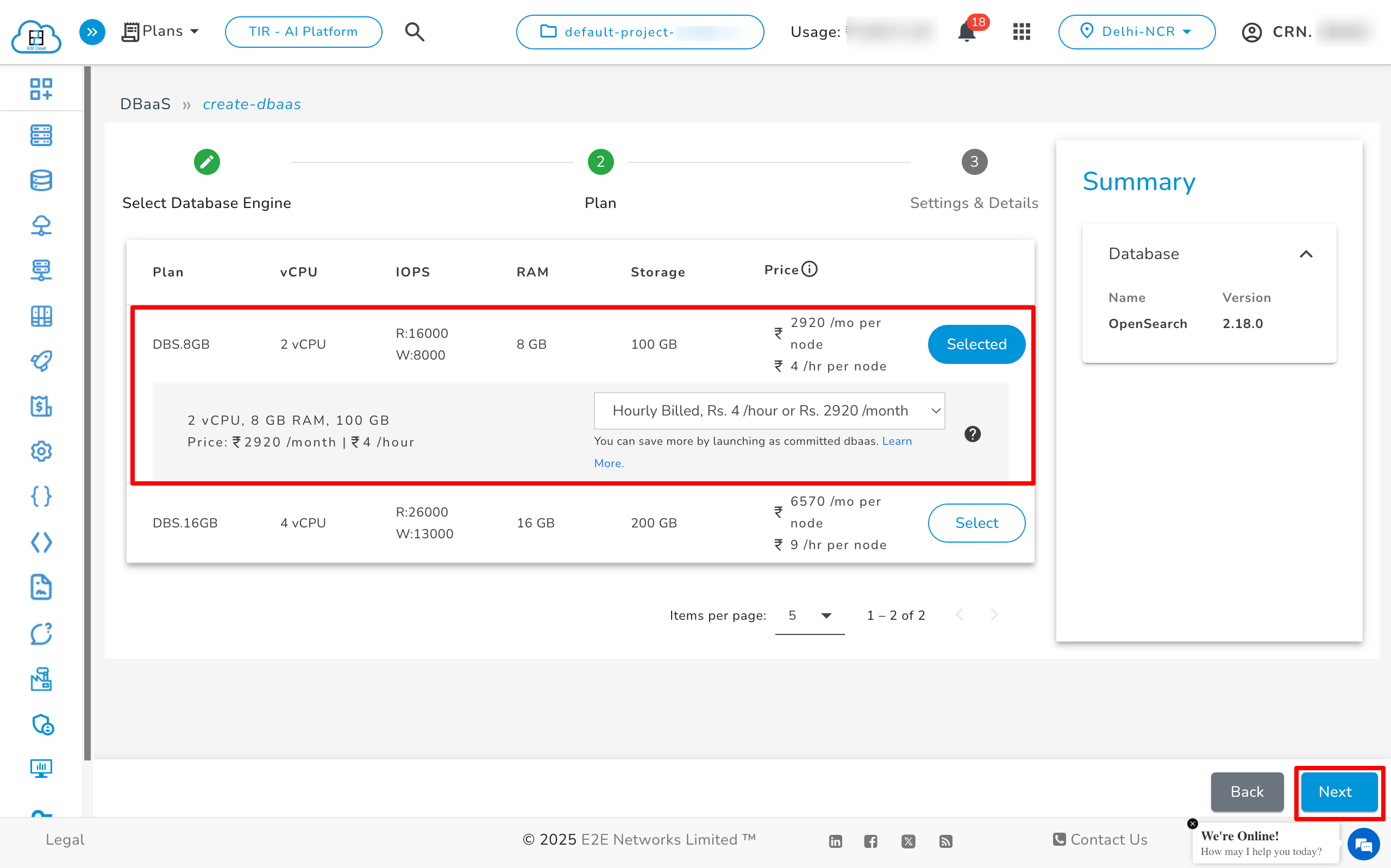
Now fill all the details and click on the "Launch Cluster" button.
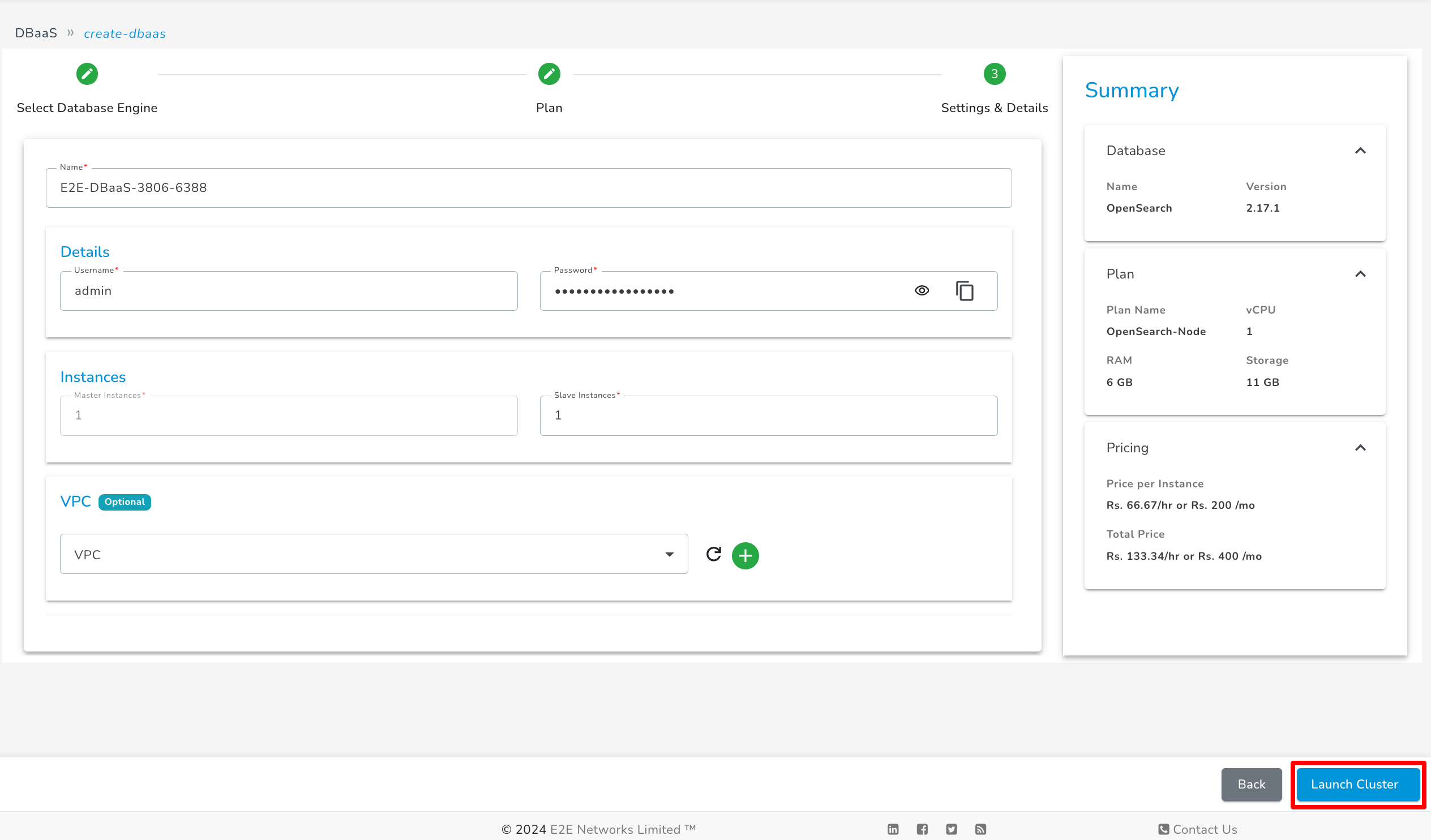
After the cluster is created, you can see its details on the DBaaS listing page.
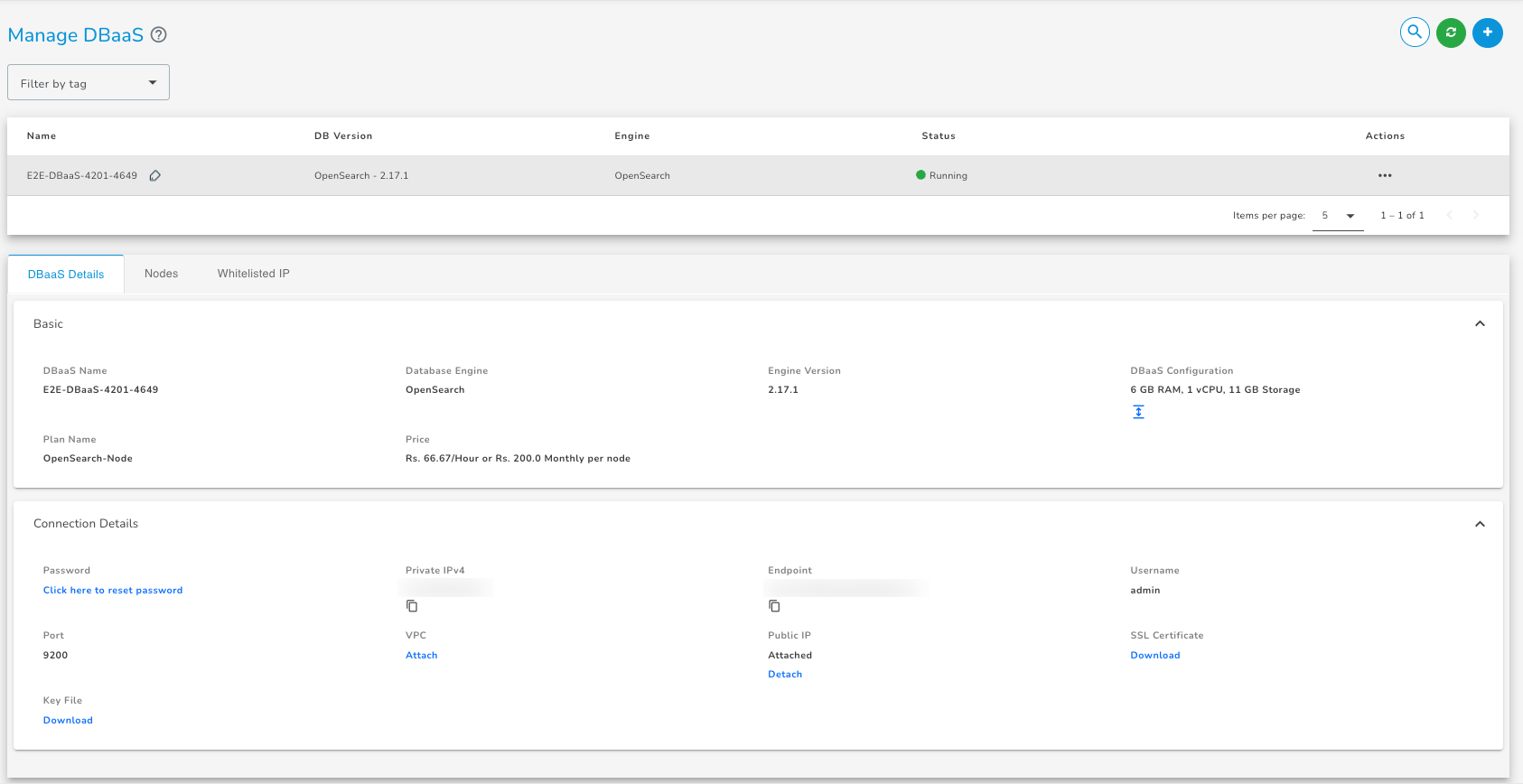
How to connect to a OpenSearch DbaaS
Once your database has been provisioned and is in running status, you can get the database connectivity information on the dashboard under the connection details.
- Endpoint
- Port
- Username
- Password
- Admin Certificate
- Admin Key Certificate
- Root ca Certificate
Enter the following command at a command prompt on your local or client desktop to connect to a OpenSearch database:
curl -X GET "https://<DBAAS_ENDPOINT>:9200" \
-u "<USERNAME>:<PASSWORD>" \
-E /path/to/admin-certificate.cer \
--key /path/to/admin-key.cer \
--cacert /path/to/root-ca-certificate.cer
Different Types of Nodes in OpenSearch
Cluster Manager
Manages cluster operations by creating and deleting indexes, monitoring node health, and allocating shards. It tracks nodes joining or leaving the cluster and ensures overall system stability.
Coordinator Node
Forwards requests to the data nodes that hold the data and reduce each node's results into a single global result set.
The Cluster Manager and Coordinator Node are automatically created when you launch the DBaaS and cannot be deleted.
Data Node
Stores and searches data, handling all operations like indexing, searching, and aggregating on local shards. These worker nodes require more disk space than other node types in the cluster.
A Data node is automatically created when you launch the OpenSearch DBaaS. Additionally, the last Data node cannot be deleted, as OpenSearch DBaaS requires at least one Data node to function.
Ingest Node
Pre-processes data before storing it in the cluster. Runs an ingest pipeline that transforms your data before adding it to an index.
Dynamic Node
Delegates specific nodes for custom tasks like machine learning (ML), ensuring data nodes remain unaffected and preserving overall OpenSearch functionality.
API for Upscaling and Downscaling Opensearch Cluster
Upscale OpenSearch Cluster
Endpoint - https://api.e2enetworks.com/myaccount/api/v1/rds/cluster/<cluster-id>/opensearch-node/?apikey=<api-key>&project_id=<project-id>&location=<location>
Payload — {"node_role":"<type_of_node>","num_instances": <no_of_instances>}
Method - POST
Response - {
"code" : 200,
"data" : {"cluster_id": <cluster-id>, "name": <cluster-name>},
"error": {},
"message" : "Success"
}
DownScale OpenSearch Cluster
Endpoint - https://api.e2enetworks.com/myaccount/api/v1/rds/cluster/<cluster-id>/opensearch-node/?apikey=<api-key>&project_id=<project-id>&location=<location>&node_id=<node_id>
Method — DELETE
Cluster Status
Cluster Status indicates the overall health of the cluster using numeric codes. Each code maps to a specific status color and meaning.
| Code | Status | Meaning |
|---|---|---|
| 0 | Green | The cluster is healthy. All nodes and services are functioning normally. |
| 1 | Yellow | The cluster is in a warning state. Some components may be degraded, but the cluster remains operational. |
| 2 | Red | The cluster is in a critical state. One or more components have failed, requiring immediate attention. |
To learn more about OpenSearch click here