Guide to Fine-tune Llama 3 Vision
Introduction
The LLaMA 3.2 11B Vision Model is a state-of-the-art, multimodal AI model with 11 billion parameters, designed to process and understand both text and images. Developed as part of the LLaMA (Large Language Model Meta AI) family, this model builds on the strengths of its predecessors while introducing advanced vision capabilities for more comprehensive and context-aware interactions. LLaMA 3.2 Vision is engineered to excel in tasks that require an understanding of visual content alongside textual context. It utilizes a vision transformer (ViT) to convert images into embeddings that can be processed by the language model, enabling applications like image captioning, visual question answering (VQA), and multimodal content generation.
Fine-tuning the LLaMA 3.2 11B Vision Model involves adapting its parameters to specific tasks or datasets, leveraging its extensive pretraining on diverse text and image data. This process uses transfer learning principles, where the model's broad, foundational knowledge is specialized to enhance performance in targeted domains, such as medical imaging, autonomous driving, or e-commerce applications. The name LLaMA reflects Meta's ongoing commitment to advancing open-source, large-scale language models, with the 3.2 Vision variant pushing the boundaries of multimodal understanding by seamlessly bridging the gap between textual and visual data.
How to Create a Fine-tuning Job?
-
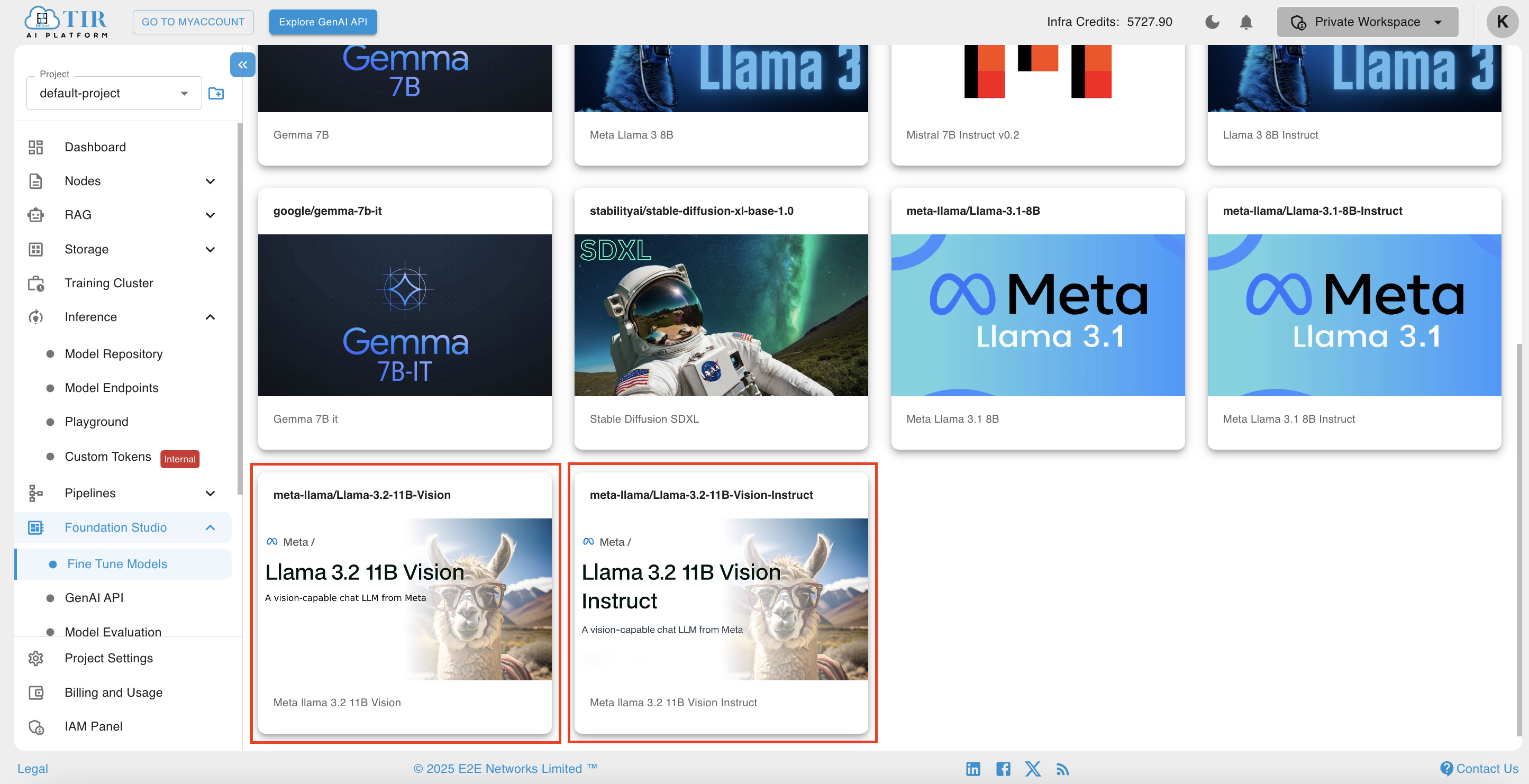
On the Create Fine-tuning Job page will open, there are several fine-tune model available to select. Select your preferred Llama Vision Model.
-
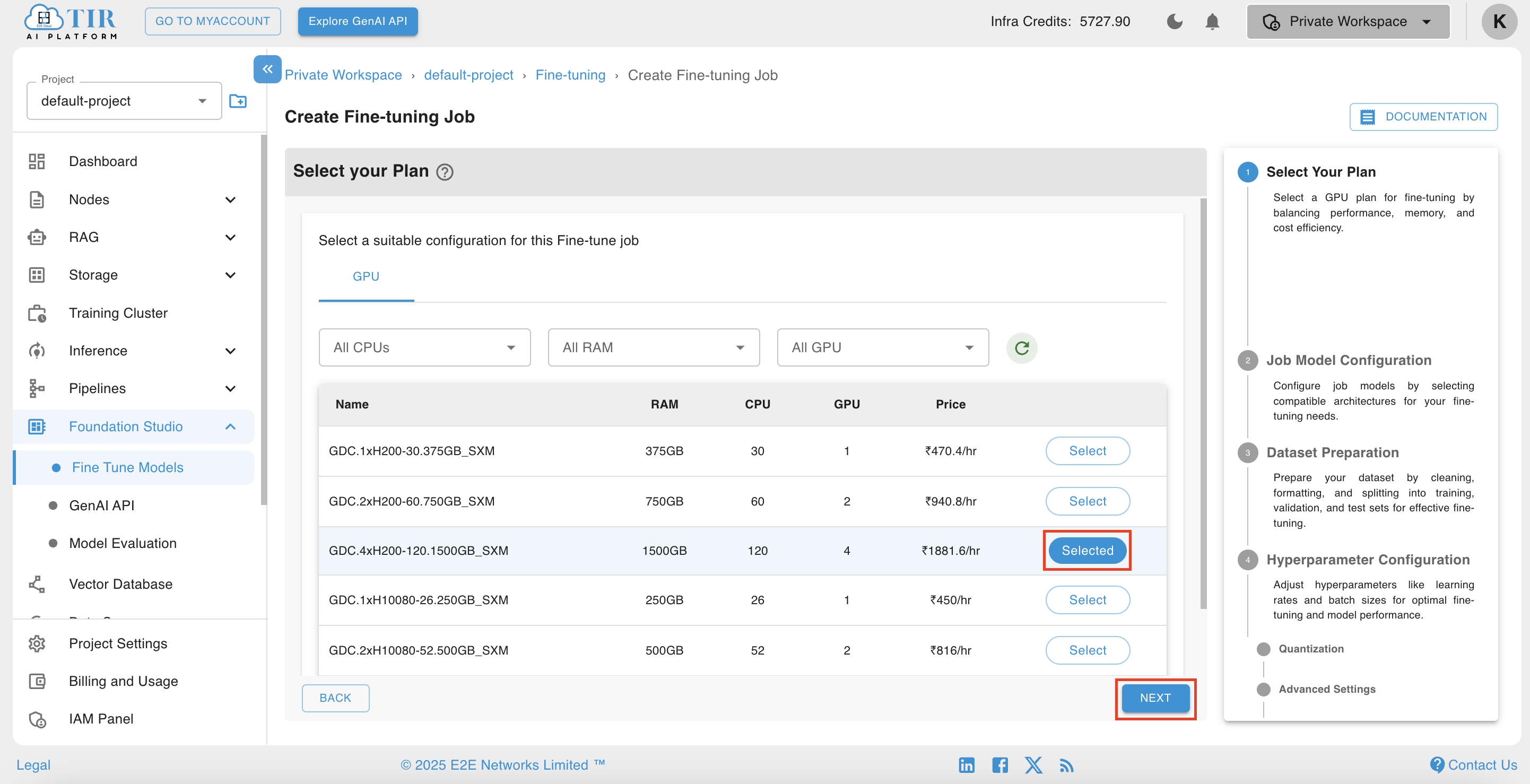
After selecting the model, the select plan page will open. On this page user can select from the available GPUs based on his requirements. After selecting plan click on Next.
-
Select your HuggingFace Token Integrations, if no integration is available create one. After selecting the token check for access. If the token has access to the fine-tune mode click on Next.
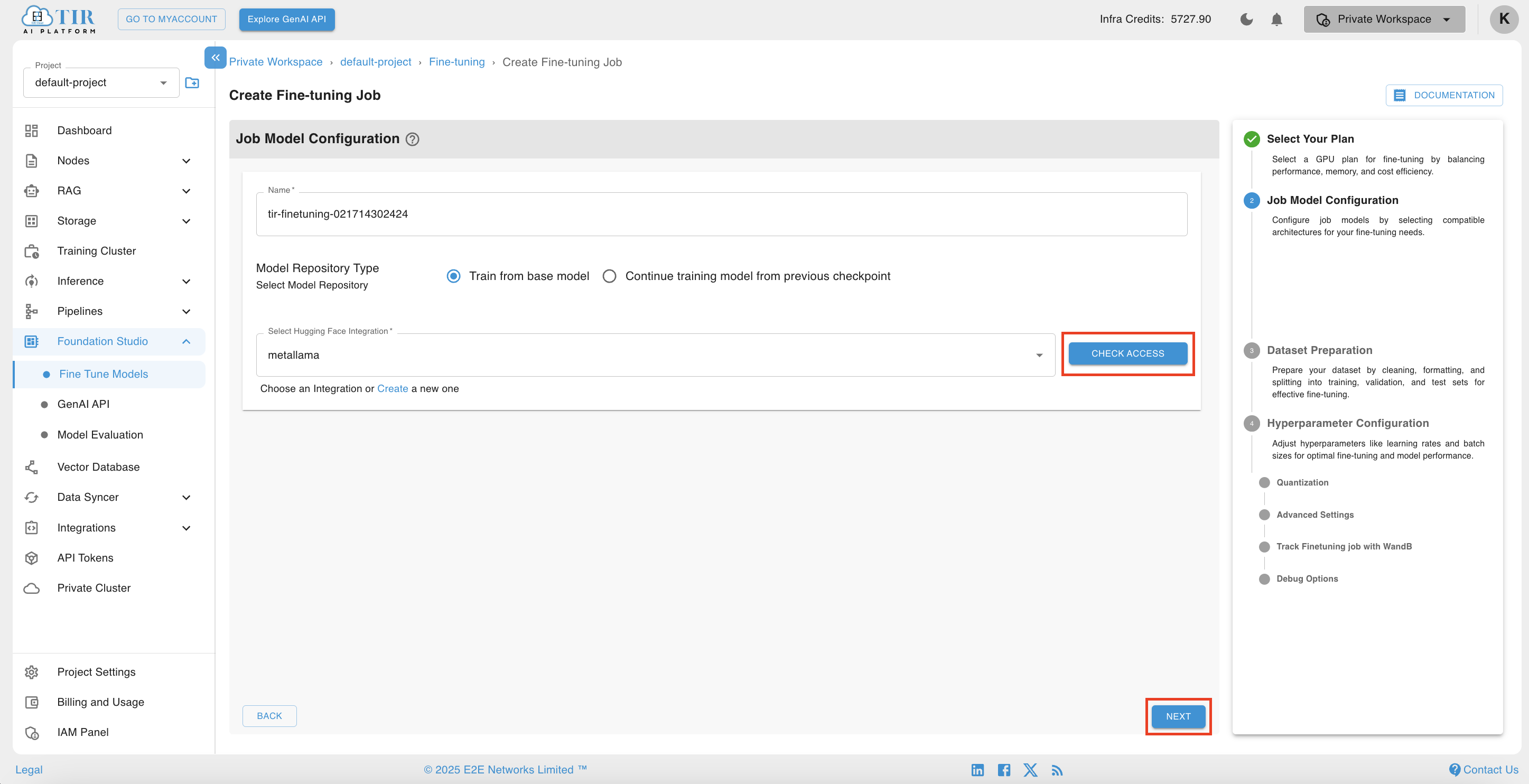
Some model are available for commercial use but requires access granted by their Custodian/Administrator (creator/maintainer of this model). You can visit the model card on huggingface to initiate the process.
Dataset Preparation
After defining the Job Model configuration, users can move on to the next section for Dataset Preparation. The Dataset page will open, providing several options such as Select Task, Dataset Type, Choose a Dataset, Image Column, Caption Column, Image Type, Fine-tuning Instruction and Instruction. Once these options are filled, the dataset preparation configuration will be set, and the user can move to the next section.
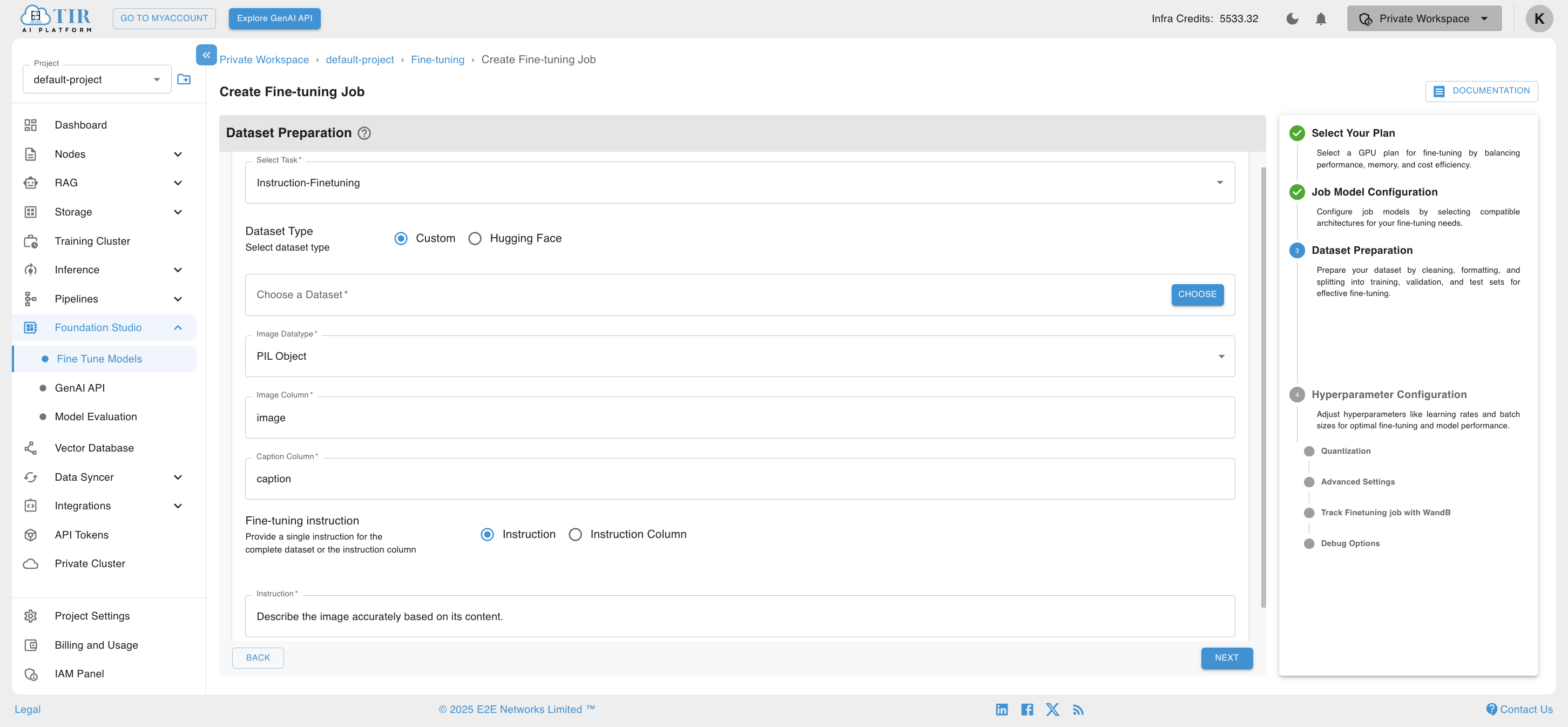
Custom Dataset
-
After selecting the custom dataset, you can upload objects in a particular dataset by selecting the dataset and clicking on the UPLOAD DATASET button.
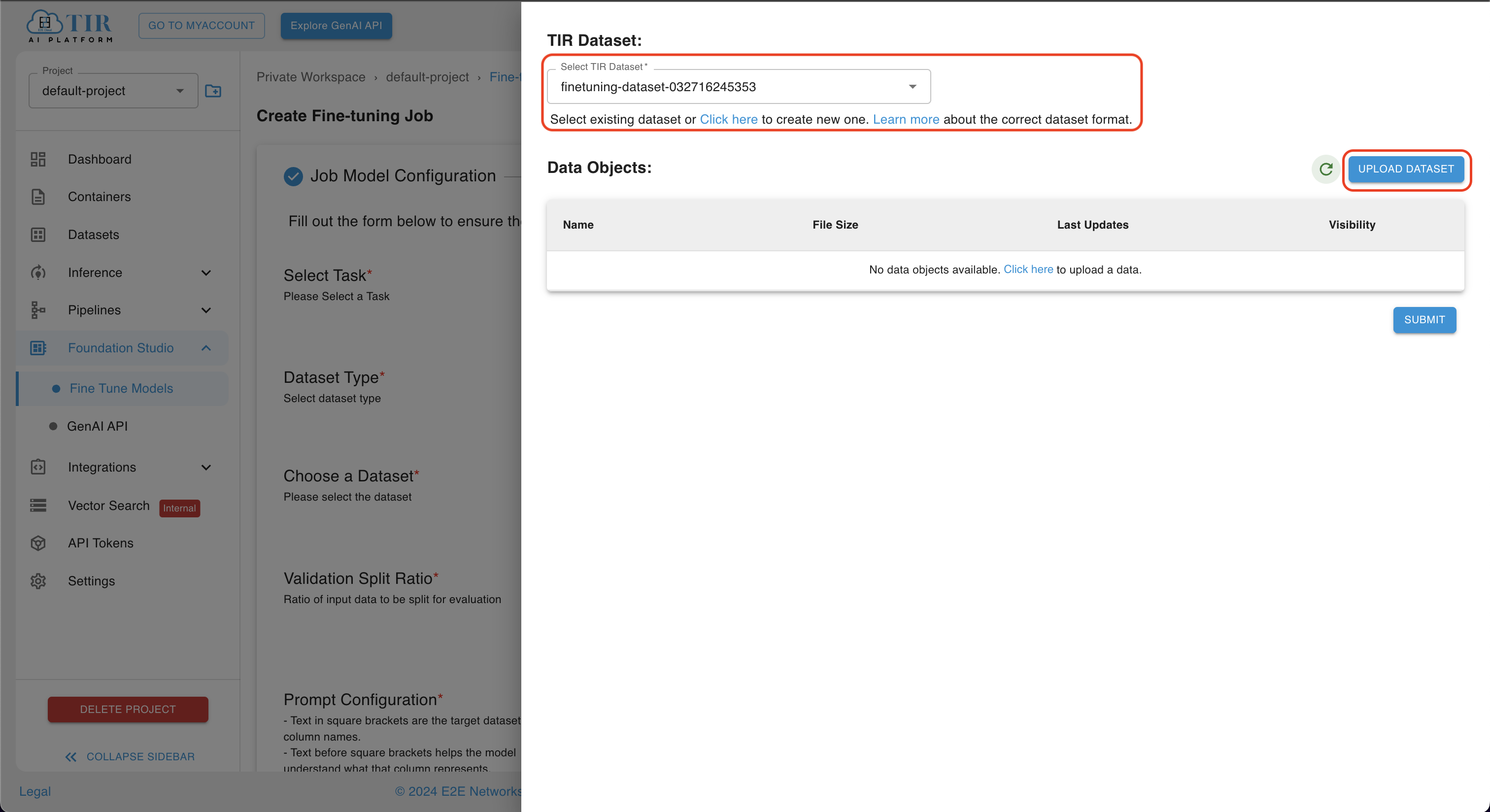
-
Click on the UPLOAD DATASET button, upload objects, and then click on the UPLOAD button.
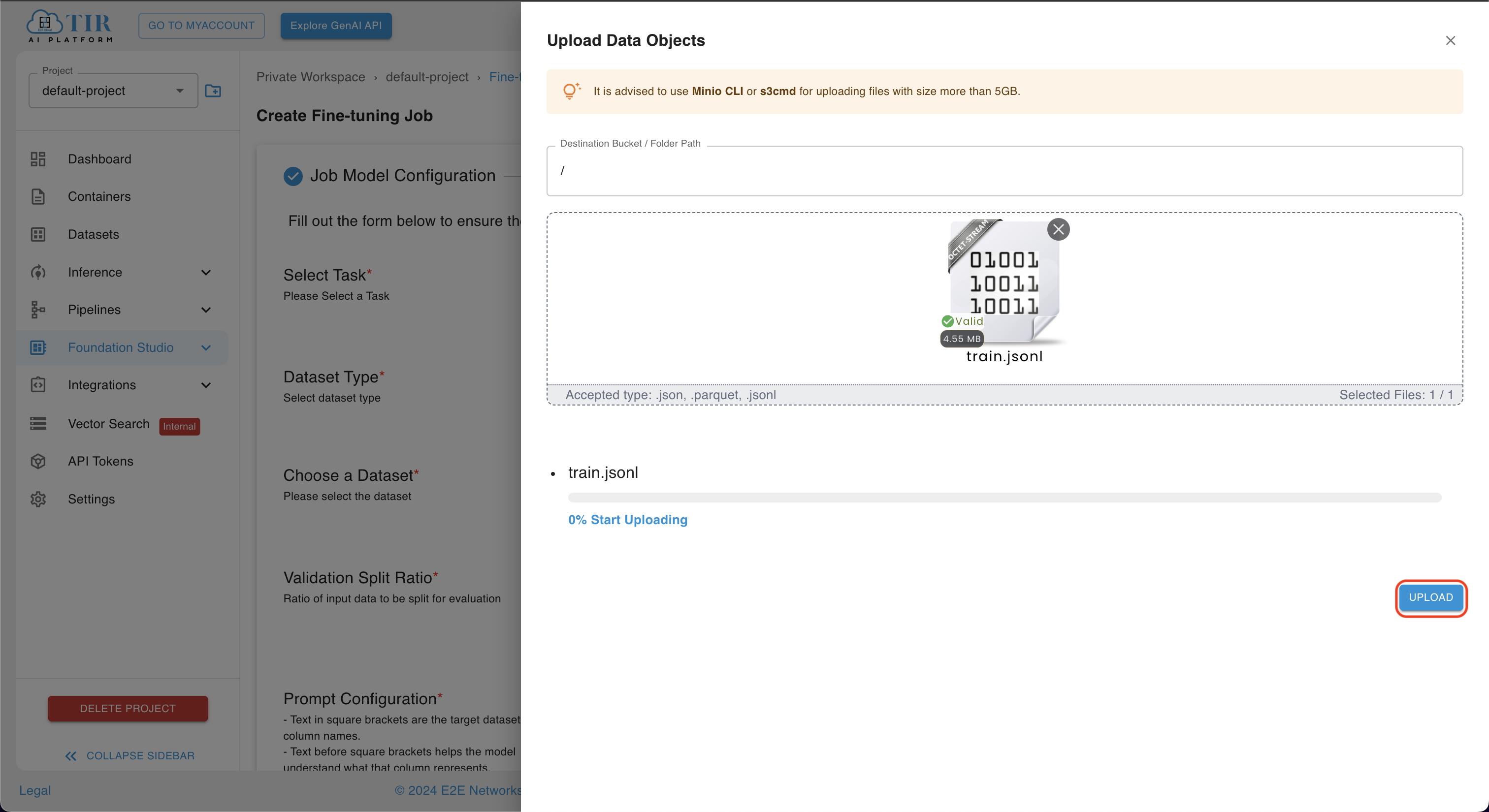
-
After uploading objects to a specific dataset, choose a particular file to continue and then click on the SUBMIT button.
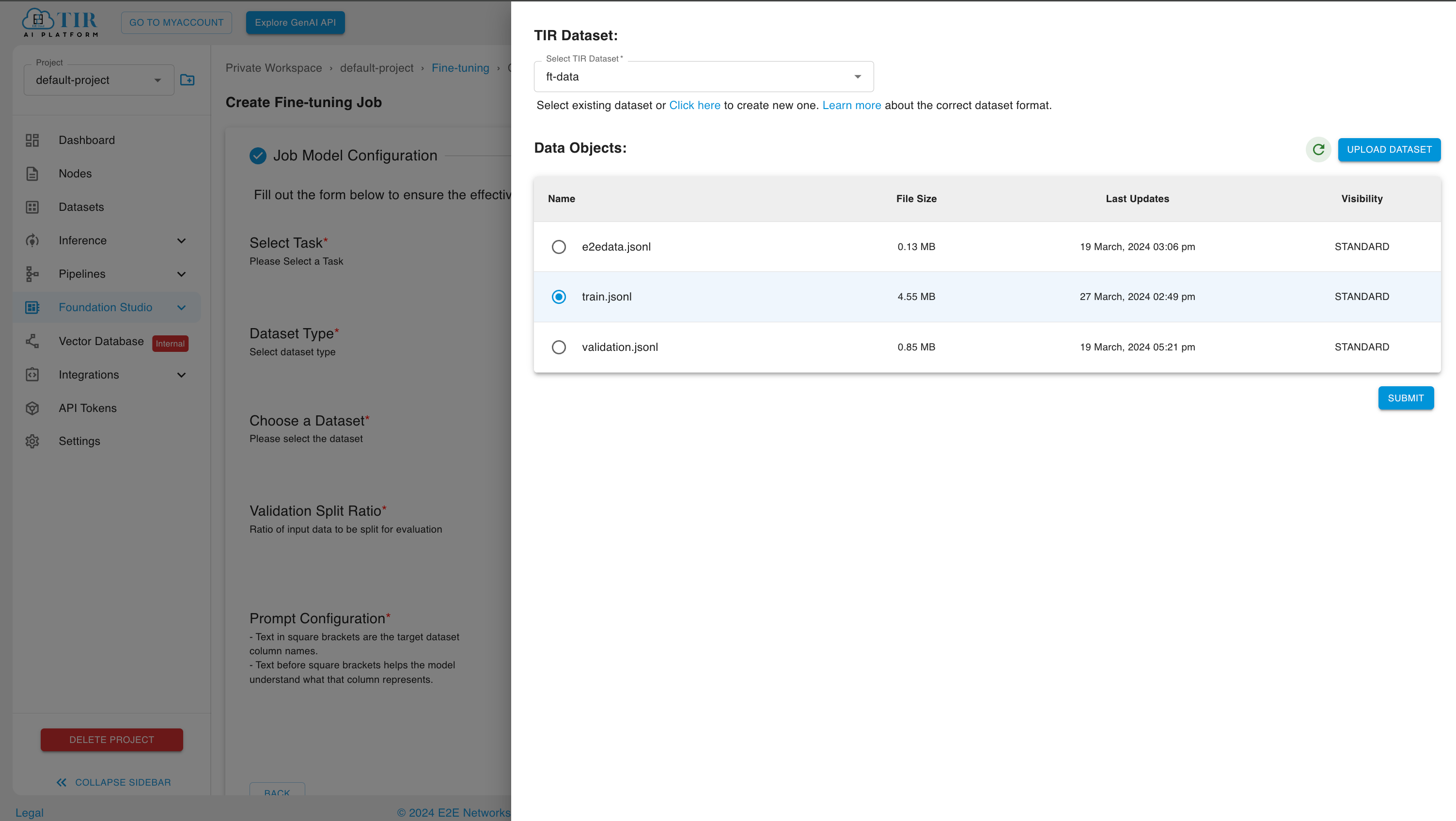
How to define a Hyperparameter Configuration?
-
Upon providing the dataset preparation details, users are directed to the Hyperparameter Configuration page. This interface allows users to customize the training process by specifying desired hyperparameters, thereby facilitating effective hyperparameter tuning. The form provided enables the selection of various hyperparameters, including but not limited to training type, epoch, learning rate, and max steps. Please fill out the form meticulously to optimize the model training process.
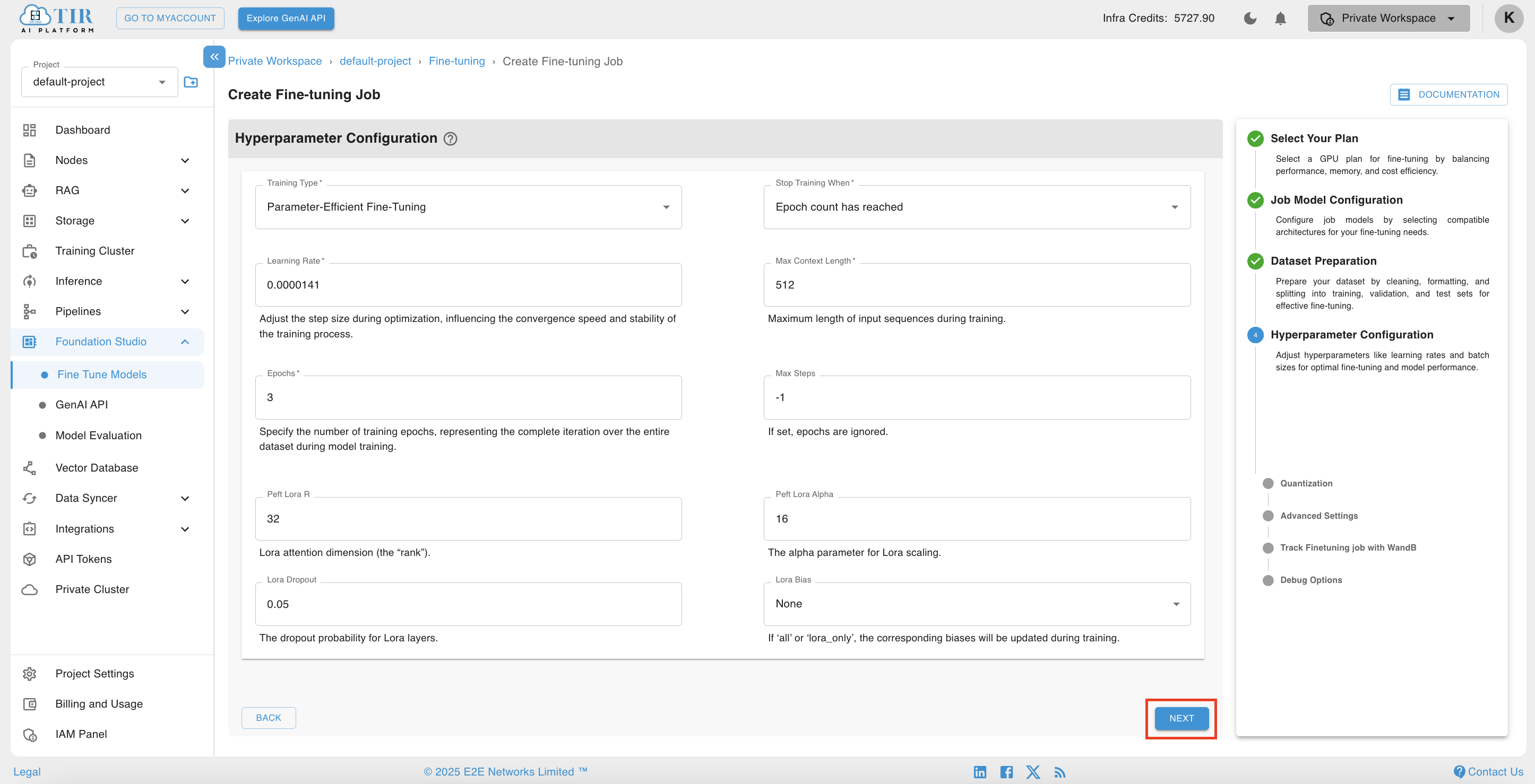
-
Next step would be quantization, the configuration page offers advanced options such as Load In 4 Bit and Use DoubleQuant. These settings can be utilized to reduce memory usage and improve inference speed.
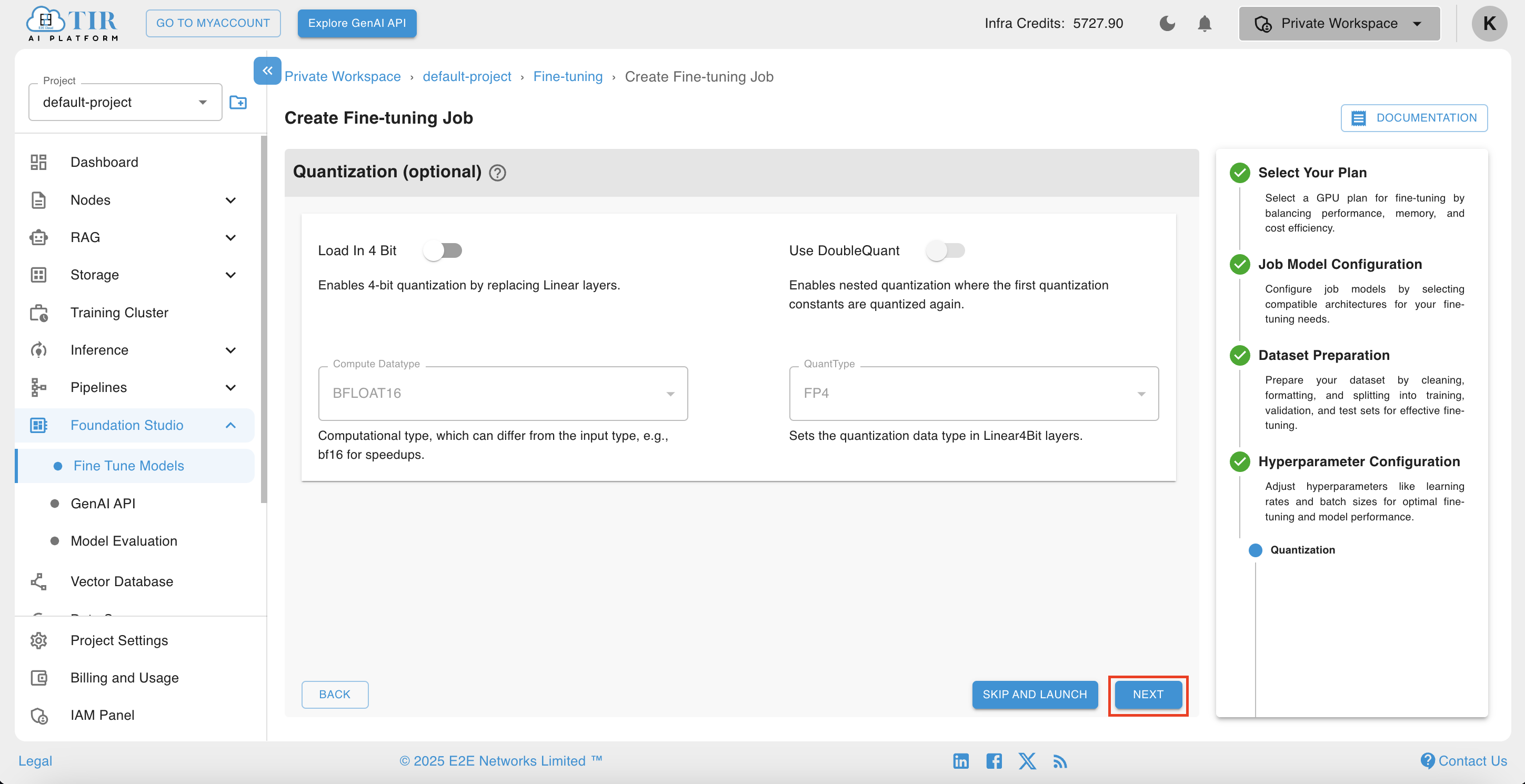
-
In addition to the standard hyperparameters, the configuration page offers advanced options such as batch size and gradient accumulation steps. These settings can be utilized to further refine the training process. Users are encouraged to explore and employ these advanced options as needed to achieve optimal model performance.
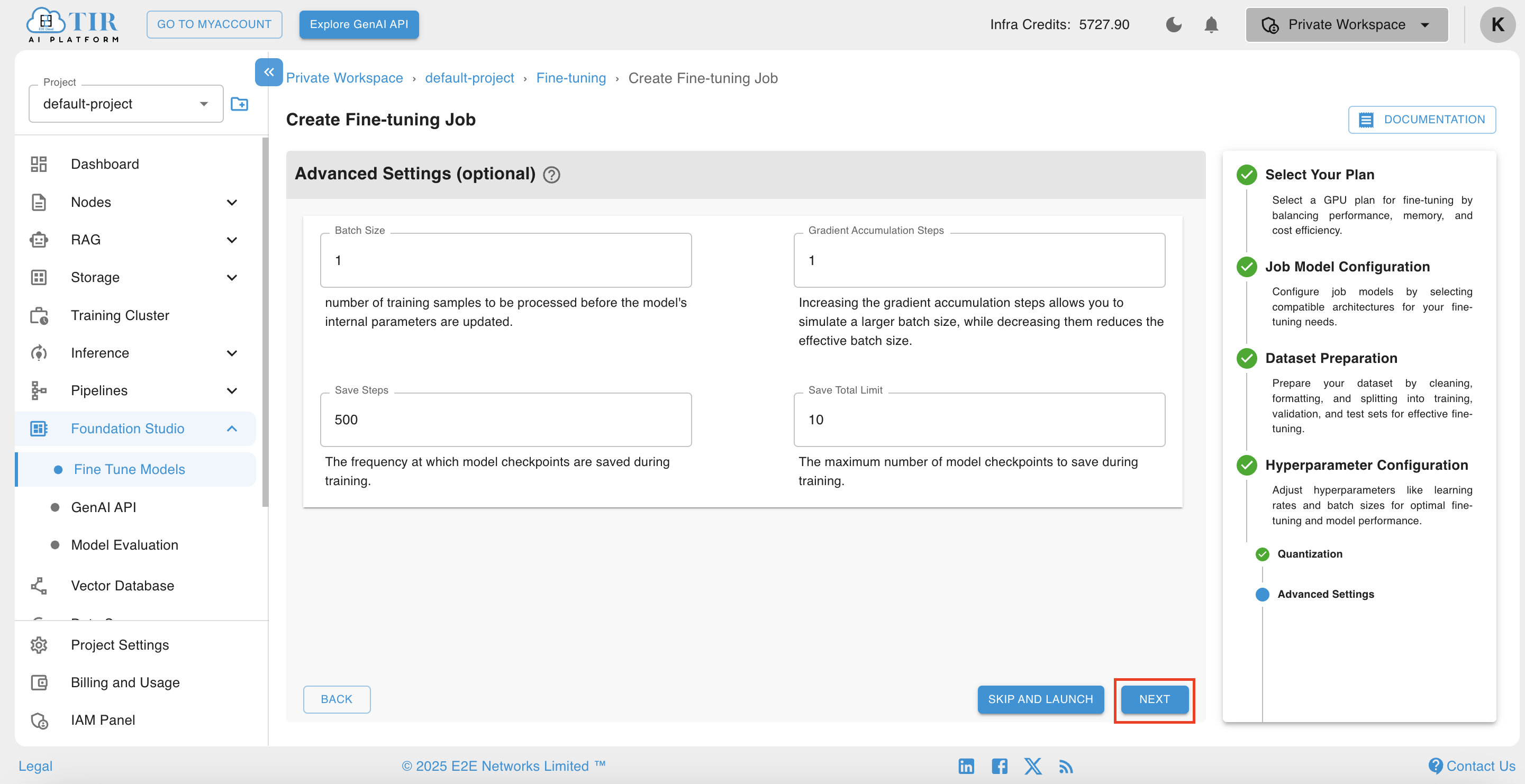
-
Integrate WanDB or tracking experiments, visualizing model performance, and collaborating on machine learning projects. Integrating it into your fine-tuning process helps you monitor loss, learning rates, model performance, and more.
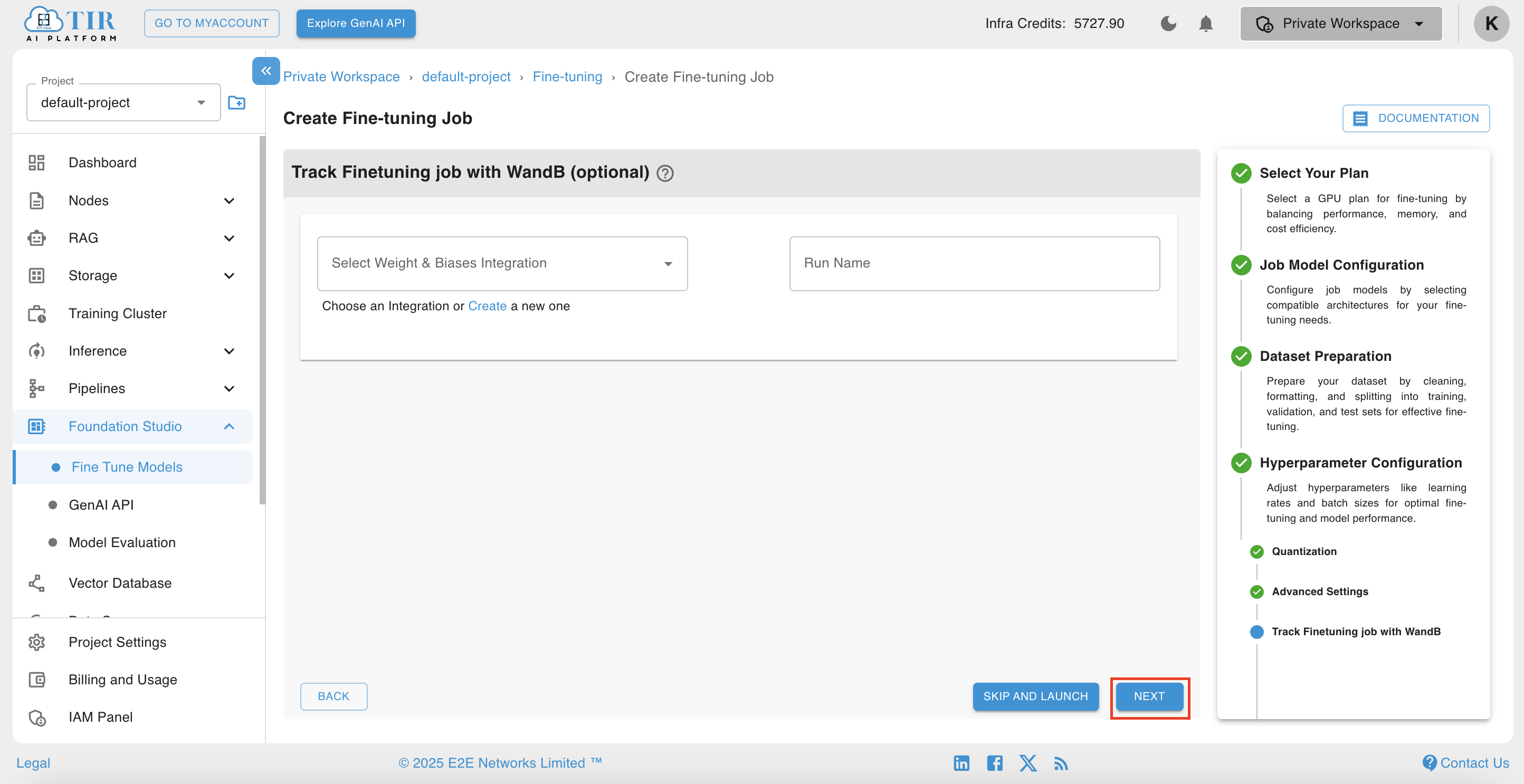
-
Users can also describe the debug option as desired for debugging purposes or quicker training.
Launch
Once the debug option has been thoroughly addressed, clicking on the LAUNCH button will initiate or schedule the job, depending on the chosen settings. To ensure fast and precise training, a variety of high-performance GPUs, such as Nvidia H100 and A100, are available for selection. This allows users to optimize their resources and accelerate the model training process.
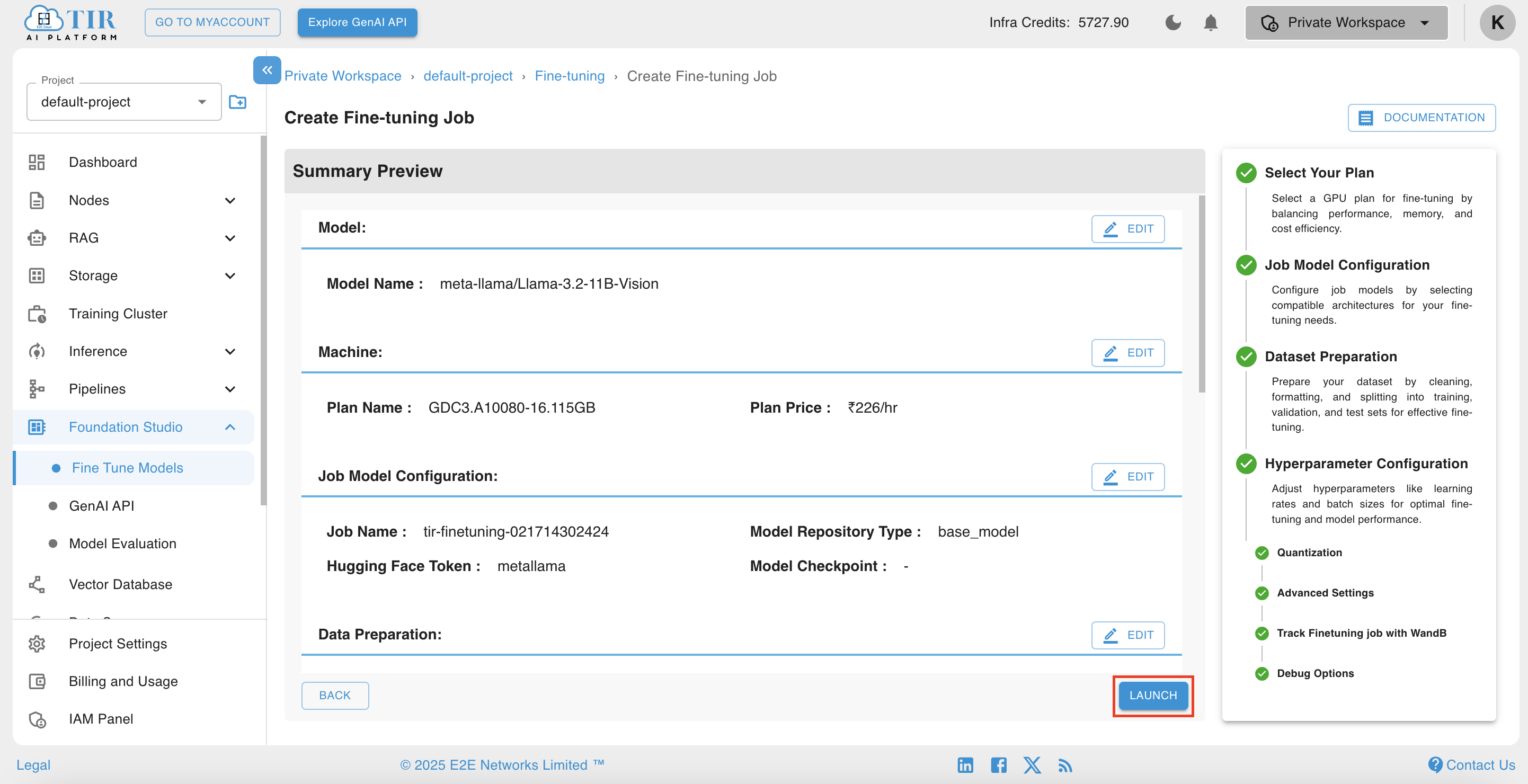
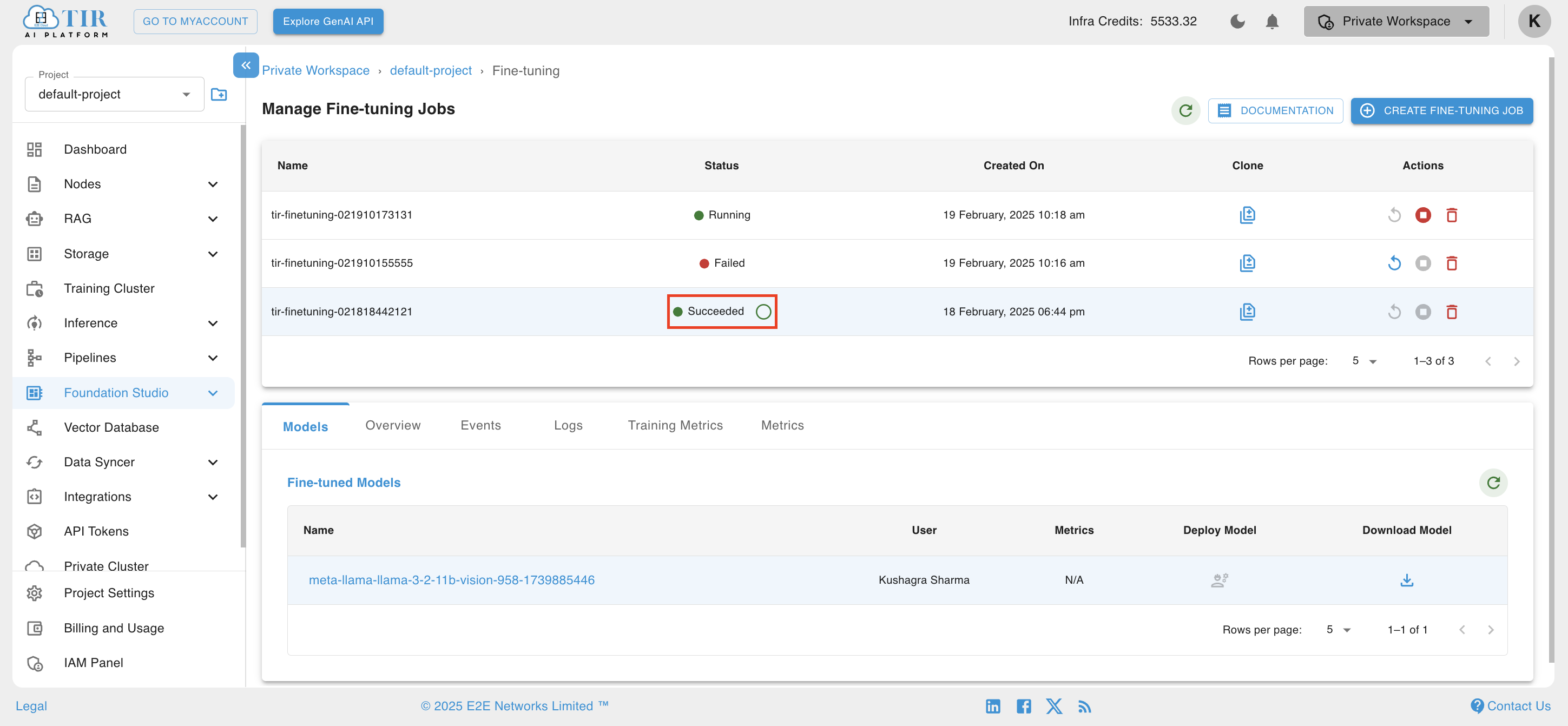
Viewing your Job Parameters and Fine-tuned Models
-
Upon completion of the job, a Fine-tuned model will be created and shown in the models section in the lower part of the page. This fine-tuned model repo will contain all checkpoints of model training as well as adapters built during training. Users can directly go to the model repo page under inference to view it.
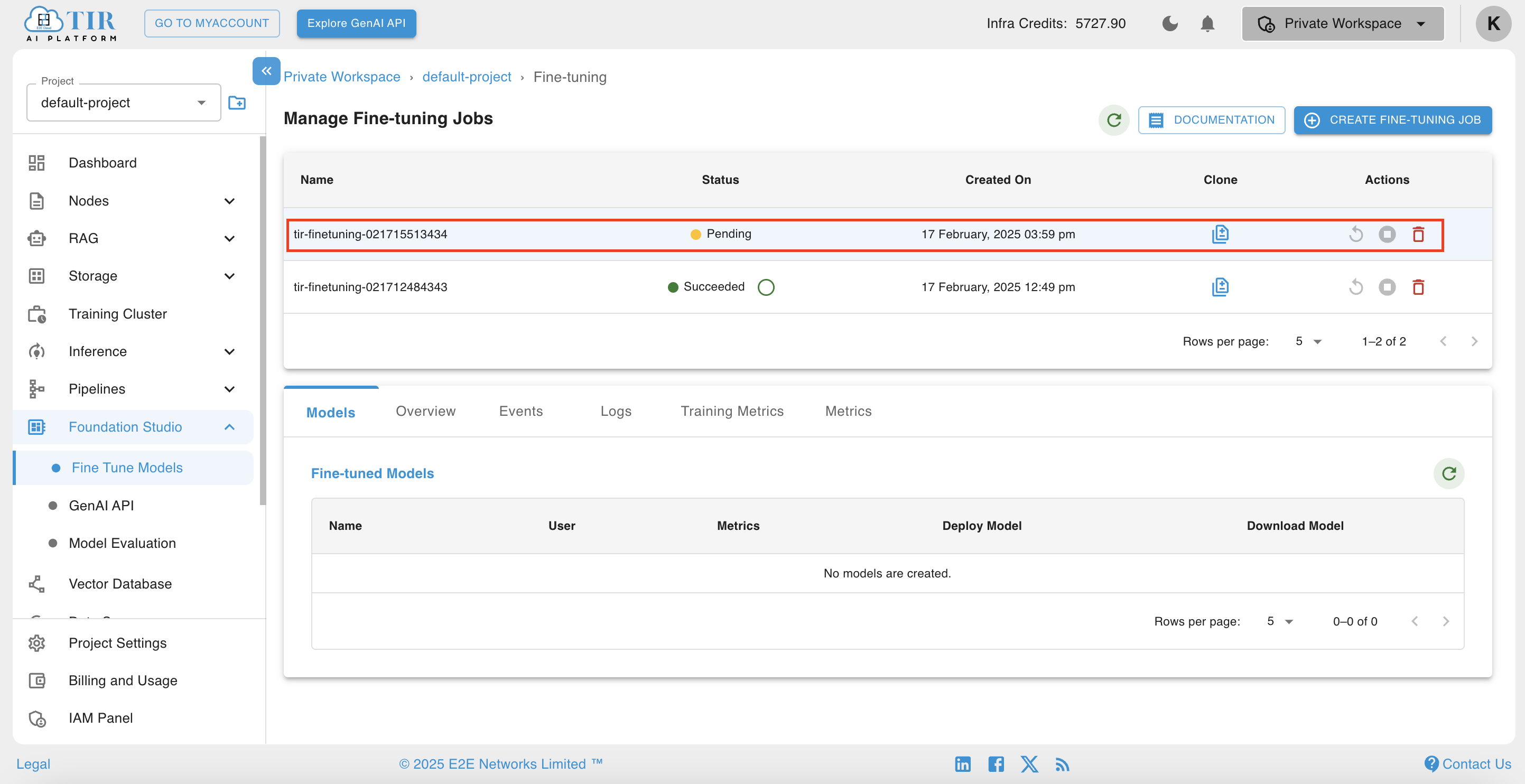
-
If desired, the user can view job parameter details in the overview section of the job as shown below.
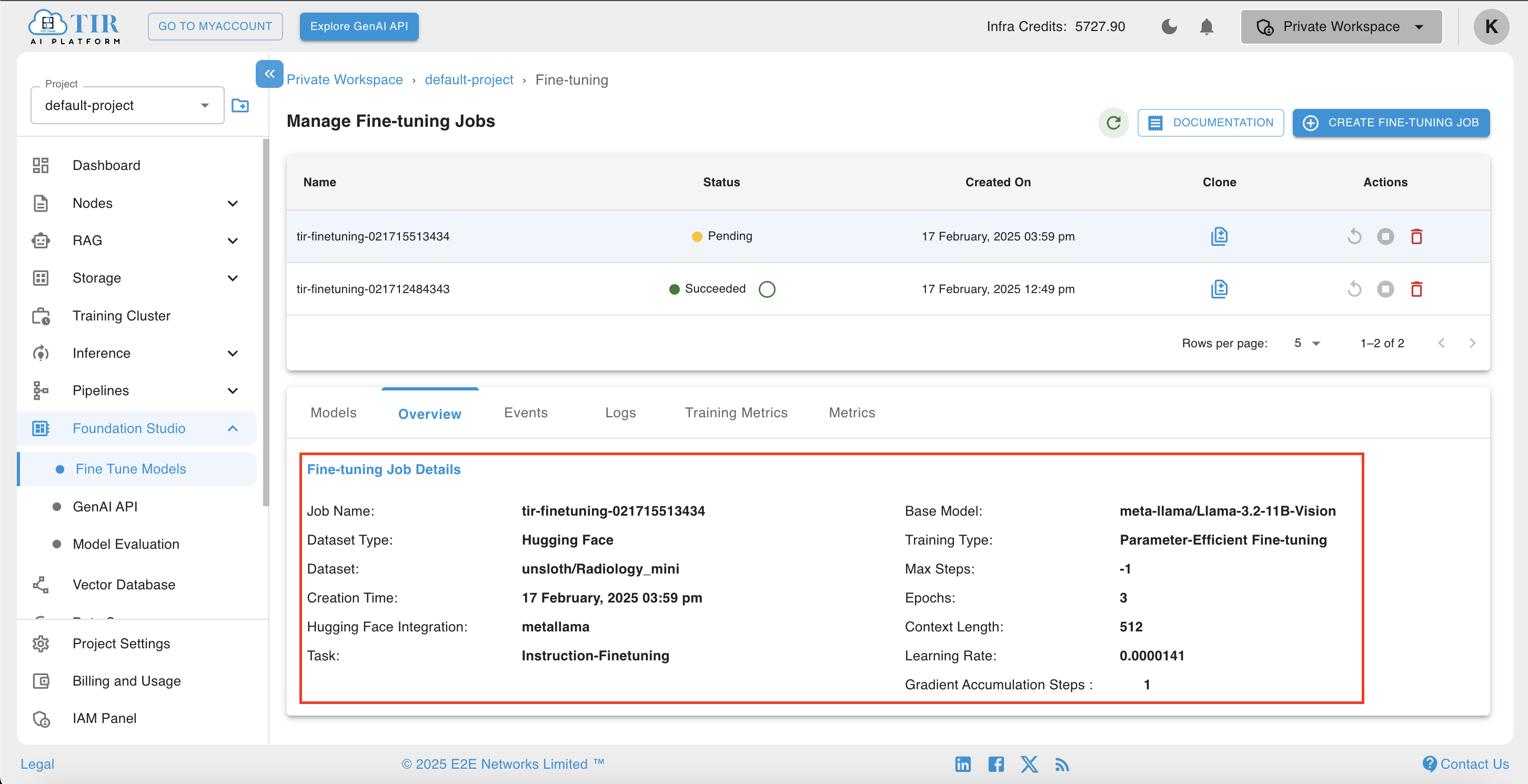
-
Users can effortlessly access the logs of the model training by clicking on the run of the fine-tuning job they've created. These logs serve as a valuable resource, aiding users in debugging the training process and identifying any potential errors that could impede the model's progress.
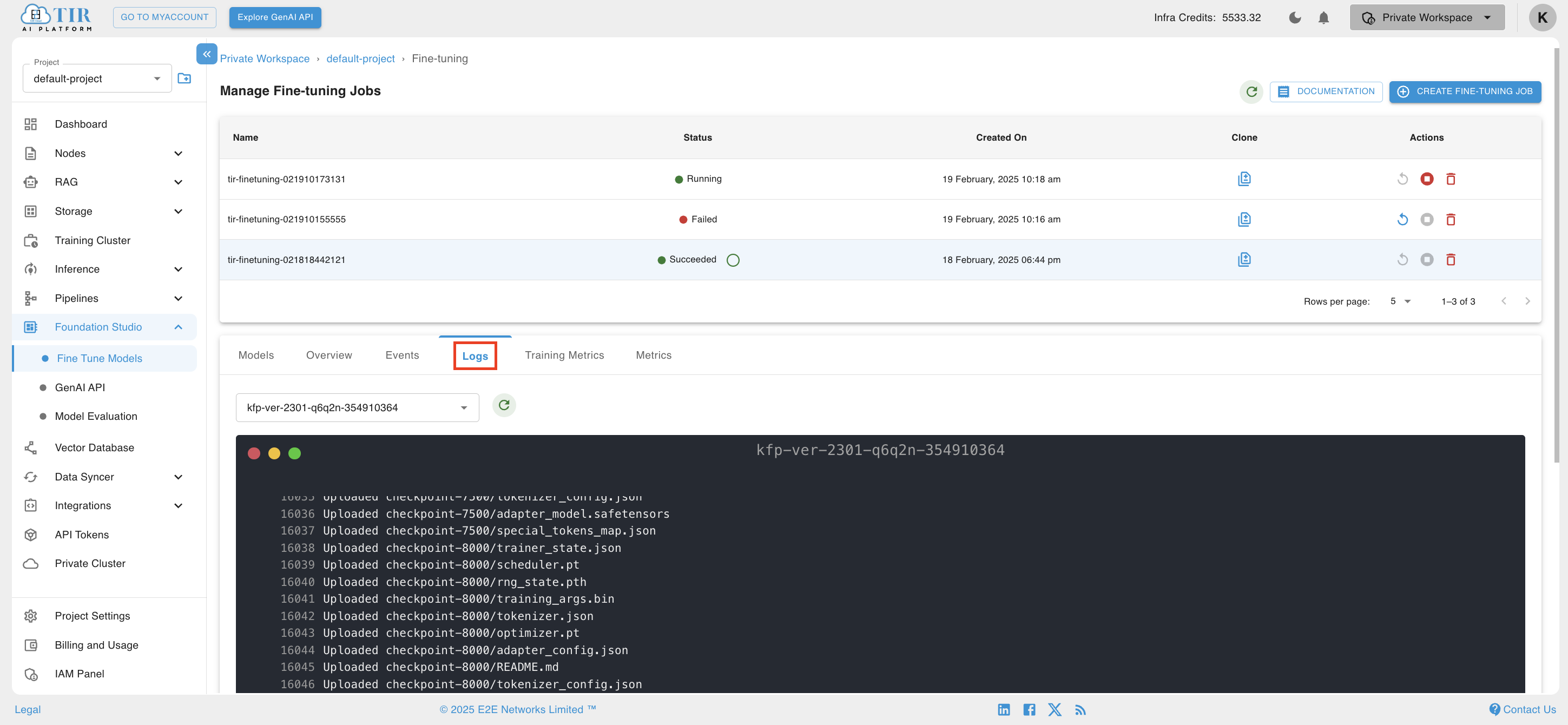
-
Upon successful completion of training, the model will be seamlessly pushed, ensuring smooth integration with the existing model infrastructure.