Billing
RAG Billing
This is a breakdown of the RAG components to give you an idea of how you can use the RAG functionality on TIR and the corresponding billing process. The billing process in RAG on TIR consists of three key components. Below is an overview of each component:
RAG BILLING COMPONENTS
| Component | Storage | Retrieval (Search & Indexing) | GenAI API (or Model Endpoints) |
|---|---|---|---|
| Description | Storage of Knowledge Base Documents and Vector Embeddings | Retrieving relevant chunks from the Vector storage based on user query | API Calls made to the different models (Embedding / Re-rank / LLM) during the different stages of RAG |
| Price | Rs 8/- Per GB Per Month | Rs 10/- Per 1 Million Token (Input+Output) | Based on the GenAI pricing of specific models. No Additional cost in case of Model Endpoints |
Note: The values, prices, and other figures in the example below are for illustration purposes only and may differ in actual scenarios.
Adding Files to the Knowledge Base
The first step in RAG is to populate the Knowledge Base with relevant documents. Here’s how the document insertion process works:
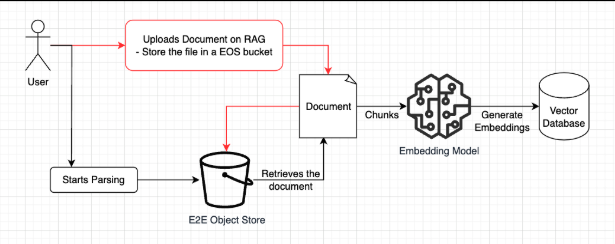
You can start by creating a knowledge base and uploading your file to it. Once uploaded, the file is stored in an internal bucket. The storage cost for the file over a month will be:
Billing Component: Storage
Rate: Rs 8/- Per GB Per Month
Time: 10 Days
Size: 1.2 GB
Price: 8 * 10 * 1.2 / (30 * 1) = Rs 3.2/-
During the parsing process, our service extracts the file's contents, chunks it into smaller sections, generates embeddings for each chunk, and inserts these embeddings into the vector database.
In this step, the only cost incurred by the user is for the tokens processed by the embedding model. Currently, we utilize GenAI to generate embeddings. For instance, if the file contains 1 million tokens, the cost will be calculated as follows:
Billing Component: GenAI API
Model: BAAI/bge-large-en-v1_5
Tokens: 1 Million
Rate: Rs 0.05/- Per 100 Tokens
Price: (0.05 * 1000000) / 100 = Rs 500/-
The above process is a one-time billing component, unlike the storage component, which is billed monthly. It applies only when the user parses the file, simply uploading the file will incur storage charges only.
Thus, the cost of storing the file for one month will be ₹3.2, while parsing the file will incur a total charge of ₹503.2 (₹500 for parsing + ₹3.2 for storage).
With this, your knowledge base is fully prepared and ready to be utilized by a Chat Assistant.
Using the Chat Assistant
To integrate the newly created Knowledge Base with an LLM, the next step is to create a Chat Assistant that can effectively leverage the Knowledge Base for generating responses.
Case 1 (Simple Retrieval)
In the simplest scenario, the Chat Assistant retrieves relevant chunks from the Knowledge Base and combines them with the user’s prompt and the system prompt (User-provided instructions guide the LLM in generating responses, including aspects like character design, answer length, language, and other formatting preferences) to provide context to the LLM. The LLM then generates a response based on this enriched input. The flow is as follows:
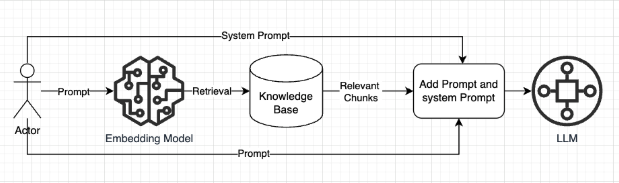
If you use a custom inference for any of the models (Embedding, LLM or Re-rank), you will not incur charges for the respective tokens processed.
First, the user’s prompt is converted into vector embeddings. If the prompt contains 10 tokens, the cost for this step will be:
Billing Component: GenAI API
Model: BAAI/bge-large-en-v1_5
Tokens: 10
Rate: Rs 0.05/- Per 100 Tokens
Price: (0.05 * 10) / 100 = Rs 0.005/-
Next, the Knowledge Base is searched using the generated embeddings. Suppose your Top N parameter is set to 3 (configured during the assistant's creation), and 3 chunks are retrieved, each containing 100 tokens. The cost for the retrieval process will then be calculated as follows:
Billing Component: Retrieval
Tokens: 10 (prompt) + 3*100 (Retrieved Chunks) = 310
Rate: Rs 10/- Per 1 Million Tokens
Price: (10*310)/1000000 = Rs 0.003/-
Finally, the retrieved chunks, along with the user prompt and the system prompt, are passed to the LLM for processing. If the system prompt contains 50 tokens, and you use Mistral-7B-Instruct-v0.3 as your LLM, which generates a response of 150 tokens, the cost for response generation will be calculated as follows:
Billing Component: GenAI API
Model: Mistral-7B-Instruct-v0.3
Input Tokens: 10 (prompt) + 3*100 (Retrieved Chunks) + 50 (System Prompt)= 360
Output Tokens: 150
Rate (Input): Rs 54.6/- Per 1 Million Tokens
Rate (Output): Rs 231/- Per 1 Million Tokens
Price: ((54.6*360)+(231*150))/1000000 = Rs 0.054/-
Case 2 (Chat History Enabled)
If you wish to enable chat history, you can activate this feature during the Assistant creation process. Additionally, you can specify the last N messages you want the assistant to consider when generating a response. The flow will then proceed as follows:
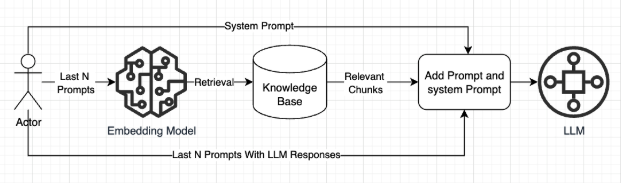
Let’s assume you’ve already had a conversation with the Assistant consisting of 3 prompts, where the last 2 messages are considered in the next prompt (Chat history = 2). The prompts were 10, 20, and 30 tokens long, and the responses were 100, 110, and 120 tokens, respectively. Now, if you provide the assistant with a new prompt of 25 tokens, the billing for embeddings will be calculated as follows:
Billing Component: GenAI API
Model: BAAI/bge-large-en-v1_5
Tokens: 20 + 30 + 25 = 75
Rate: Rs 0.05/- Per 100 Tokens
Price: (0.05 * 75) / 100 = Rs 0.038/-
Retrieval will also be performed based on these prompts.
Assuming the Top N parameter is set to 3 (as configured during the assistant’s creation), and 3 chunks are retrieved, each containing 100 tokens, the billing for the retrieval process will be calculated as follows:
Billing Component: Retrieval
Tokens: 75 (prompt) + 3*100 (Retrieved Chunks) = 375
Rate: Rs 10/- Per 1 Million Tokens
Price: (10 * 375) / 1000000 = Rs 0.004/-
Finally, the entire chat history, along with the system prompt (50 tokens) and the retrieved chunks, will be provided to the LLM to generate a response (200 tokens). The total cost for the response generation will be calculated as follows:
Billing Component: GenAI API
Model: Mistral-7B-Instruct-v0.3
Input Tokens: {20 + 30 + 110 + 120} (history) + 25 (prompt) + 3*100 (Retrieved Chunks) + 50 (System Prompt) = 655
Output Tokens: 200
Rate (Input): Rs 54.6/- Per 1 Million Tokens
Rate (Output): Rs 231/- Per 1 Million Tokens
Price: ((54.6 * 655) + (231 * 200)) / 1000000 = Rs 0.083/-
Case 3 (Chat History with Query Optimizer)
Enabling chat history significantly increases the length of the prompt. When all chat history is considered, it can lead to context length issues for the embedding model. To address this and improve the language quality, we use the chat-history and prompts to generate a new refined prompt using your LLM. Since the Chat Assistant LLM is used for query optimization, charges are applicable for GenAI models.
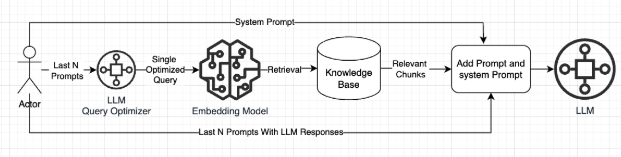
If the chat history consideration is set to 0, the Query Optimizer will not be triggered, and you will not incur any charges for that process.
Let’s assume you’ve had a conversation with the assistant consisting of 3 prompts, with the last 2 messages considered in the next prompt (Chat history = 2). The prompts were 10, 20, and 30 tokens long, and the corresponding responses were 100, 110, and 120 tokens. Now, you provide a new prompt of 25 tokens, which goes through the query optimizer along with a default prompt (A prompt that is provided to the query optimizer model to transform the chat history and user input into a simplified and concise query.) of 5 tokens (this value is hypothetical and may vary). The query optimizer generates a combined prompt of 50 tokens.
The billing for the query optimizer will be calculated as follows:
Billing Component: GenAI API
Model: Mistral-7B-Instruct-v0.3
Input Tokens: {20 + 30 + 110 + 120} (chat history) + 25 (user prompt) + 5 (default-prompt) = 310
Output Tokens: 50
Rate (Input): Rs 54.6/- Per 1 Million Tokens
Rate (Output): Rs 231/- Per 1 Million Tokens
Price: {(54.6*310) + (231*50)}/1000000 = Rs 0.03/-
Next, retrieval will occur based on the optimized query (50 tokens). Assuming the Top N parameter is set to 3 (as configured during the assistant’s creation), and 3 chunks are retrieved, each containing 100 tokens, the billing for the retrieval process will be calculated as follows:
Billing Component: Retrieval
Tokens: 50 (optimized prompt) + 3*100 (Retrieved Chunks) = 350
Rate: Rs 10/- Per 1 Million Tokens
Price: (10*350)/1000000 = Rs 0.004/-
Finally, the input provided to the LLM will be the same as in the previous case. This means the entire chat history, along with the system prompt (50 tokens) and the retrieved chunks, will be fed into the LLM to generate a response of 200 tokens. The billing for this step will be calculated as follows:
Billing Component: GenAI API
Model: Mistral-7B-Instruct-v0.3
Input Tokens: {20 + 30 + 110 + 120} (chat history) + 25 (user prompt) + 3*100 (Retrieved Chunks) + 50 (System Prompt) = 655
Output Tokens: 200
Rate (Input): Rs 54.6/- Per 1 Million Tokens
Rate (Output): Rs 231/- Per 1 Million Tokens
Price: {(54.6*655) + (231*200)}/1000000 = Rs 0.083/-
Case 4 (Re-ranker)
In RAG, a re-ranker can also be used to improve the quality and relevance of the documents retrieved by the retrieval system before passing them to the generative model for final output. It is used after the retrieval process to reorder the retrieved documents based on their relevance to the query. The flow will be as follows:
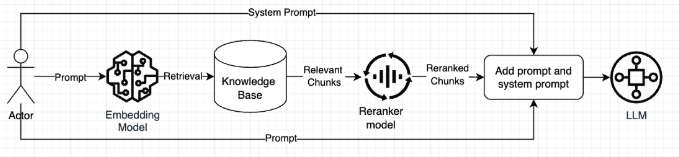
Summary
The billing in RAG on TIR is influenced by multiple factors across different stages of the retrieval and generation process. Below are the key parameters impacting the cost:
Storage Costs
- Parameter: File size (GB)
- Applicable When: Uploading files to the knowledge base
Parsing & Embedding Costs
- Parameter: Number of tokens in the file
- Applicable When: Parsing files to generate vector embeddings
Retrieval Costs
- Parameter: Number of tokens in the user prompt + retrieved chunks
- Applicable When: Searching and retrieving relevant chunks from the knowledge base
During retrieval, parameters like Top N and Chunk size can impact your costs, as pricing is based on the number of input and output tokens.
LLM Processing Costs
- Parameters:
- Number of input tokens (prompt + retrieved chunks + system prompt)
- Number of output tokens (LLM-generated response)
- Applicable When: Generating responses using the LLM
Chat History Consideration
- Parameter: Number of previous messages included in the prompt
- Impacts: Increases token count for embeddings, retrieval, and LLM processing
Query Optimizer Usage
- Parameter: Default prompt + chat history tokens
- Impacts: Additional LLM processing cost for refining the query
Re-ranker
- Parameter: Number of retrieved chunks passed to the re-ranker model
- Impacts: Additional cost for re-ranking relevant results before passing to the LLM
Model-Specific Pricing
- Parameter: Different models for embedding, retrieval, ranking, and generation have varying costs
- Impacts: Costs may vary based on the selected model