RAG (Retrieval-Augmented Generation)
Introduction
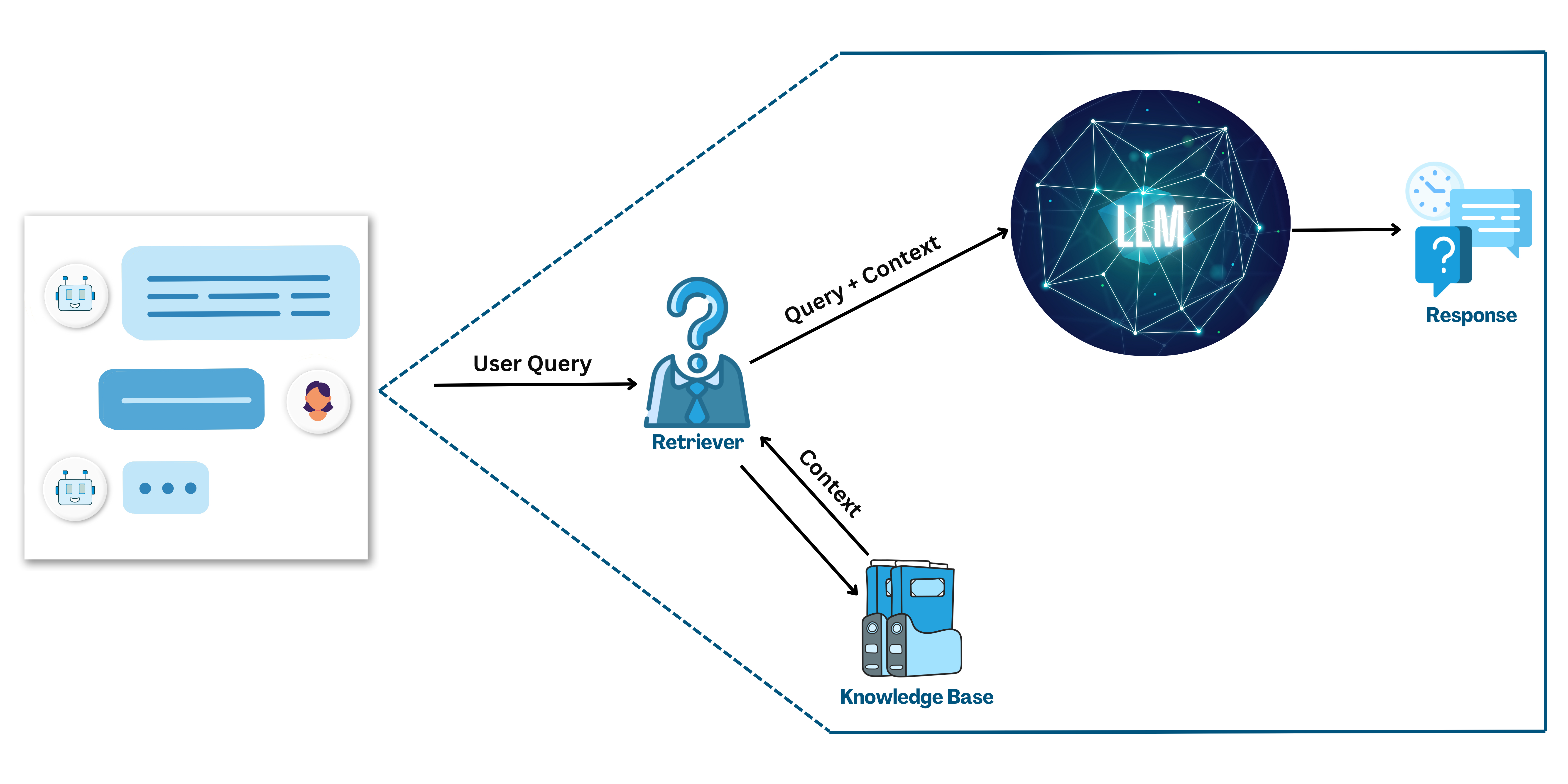
Retrieval-Augmented Generation (RAG) enhances the performance of large language models (LLMs) by enabling them to access a specific knowledge base, rather than relying solely on their general training data. LLMs, which are trained on extensive datasets and contain billions of parameters, excel at generating responses for tasks like Q&A, translation, and text completion. RAG further refines this capability by allowing LLMs to retrieve information from a trusted external knowledge source—such as an organization’s internal data—before generating responses. This approach enables accurate, context-specific, and up-to-date answers without requiring model retraining, making it an efficient and cost-effective way to tailor LLM responses for specialized domains.
Retrieval
This refers to the process of fetching or retrieving information from an external source, usually a database, knowledge base, or document repository. In the context of RAG, retrieval is the process of searching for relevant data (such as text or documents) based on a query or input provided by the user or system.
Augmented
Augmentation refers to the enhancement or improvement of something. In the case of RAG, it means enhancing the generation process of a model by supplementing it with additional, relevant information retrieved during the retrieval step. Rather than relying solely on the model's internal knowledge (which can be limited), the model is "augmented" with external data, making it more accurate and context-aware.
Generation
Generation refers to the process of creating or producing content, such as text, based on an input or prompt. In the context of RAG, it refers to the generation of text or responses by the large language model (LLM). After retrieving relevant data, the LLM generates an output, typically by using both the retrieved information and its own internal knowledge.
Use Case which RAG Supports
RAG (Retrieval-Augmented Generation) supports a range of specific use cases, making it a powerful framework for applications that require the synthesis of contextually relevant information. Here are some notable use cases:
1. Creating Chat Assistants
- Customer Support Bots: RAG enables the development of chatbot that can answer customer inquiries using a company's internal knowledge base or FAQ repository, providing detailed, context-aware responses.
- Virtual Assistants: Personal assistants powered by RAG can access external knowledge bases to provide informative responses that go beyond their training data, making them capable of more personalized interactions.
- Technical Support Assistants: Assistants designed for IT or technical domains can retrieve documentation, troubleshooting guides, or step-by-step instructions from a relevant database to help users with complex queries.
2. Handling FAQs and Knowledge Management
- FAQ Automation: RAG can be used to create intelligent FAQ systems that retrieve specific answers from company documentation, ensuring that responses are always current and accurate.
- Dynamic Knowledge Base Queries: Organizations can leverage RAG to allow employees or users to search and receive comprehensive, generated responses from extensive knowledge bases that span different topics or departments.
- Internal Document Search Tools: Tools powered by RAG can facilitate document search within an enterprise, where users input queries and receive synthesized answers extracted from various internal documents or policies.
3. Content Generation
- Article Summarization: RAG can pull relevant information from multiple sources and generate cohesive summaries or articles.
- Report Compilation: It can compile data from various reports and generate a consolidated document or response.
- Educational Tools: RAG can help create interactive learning tools that provide informative and precise responses from educational databases or textbooks.
4. Research and Analysis
- Data-Driven Research Assistants: Researchers can use RAG to query large academic databases or datasets, retrieving relevant studies and generating summaries or insights.
- Legal and Compliance Analysis: In legal or regulatory fields, RAG-powered tools can search through large collections of legal documents, case studies, and compliance requirements, delivering detailed, contextually enriched responses.
5. Personalized Recommendations
- Content Curation: RAG can tailor recommendations for articles, videos, or other resources based on a user's queries and preferences by pulling related content from knowledge bases.
- Product Support: Assistants powered by RAG can offer troubleshooting or how-to recommendations specific to the user's products or issues.
RAG (Retrieval-Augmented Generation) enhances standard LLMs by integrating a retrieval mechanism that accesses external, up-to-date data sources. This approach improves the accuracy, relevance, and contextuality of responses, addressing limitations such as outdated knowledge and hallucination. RAG allows models to provide domain-specific and real-time information without needing retraining, making it ideal for applications requiring precise and current data.