Guide to Fine Tune Mistral-7B
Introduction
The Mistral-7B-v0.1 Large Language Model (LLM) is a pretrained generative text model with 7 billion parameters. Mistral-7B-v0.1 outperforms Llama 2 13B on all benchmarks we tested.
Fine-tuning the Mistral-7B model involves the process of refining its parameters and optimizing its performance for a particular task or dataset. This method leverages the pre-existing knowledge encoded within the model through prior training on a diverse dataset, then tailors it to better suit the nuances and intricacies of a specific domain or task. In essence, fine-tuning serves as a form of transfer learning, where the model's existing understanding is adapted and enhanced to excel in a targeted area of application.
What is Fine-Tuning?
Fine-tuning refers to the process of modifying a pre-existing, pre-trained model to cater to a new, specific task by training it on a smaller dataset related to the new task. This approach leverages the existing knowledge gained from the pre-training phase, thereby reducing the need for extensive data and resources.
In the Context of Neural Networks and Deep Learning:
In the specific context of neural networks and deep learning, fine-tuning is typically executed by adjusting the parameters of a pre-trained model. This adjustment is made using a smaller, task-specific dataset. The pre-trained model, having already learned a set of features from a large dataset, is further trained on the new dataset to adapt these features to the new task.
How to Create a Fine-Tuning Job?
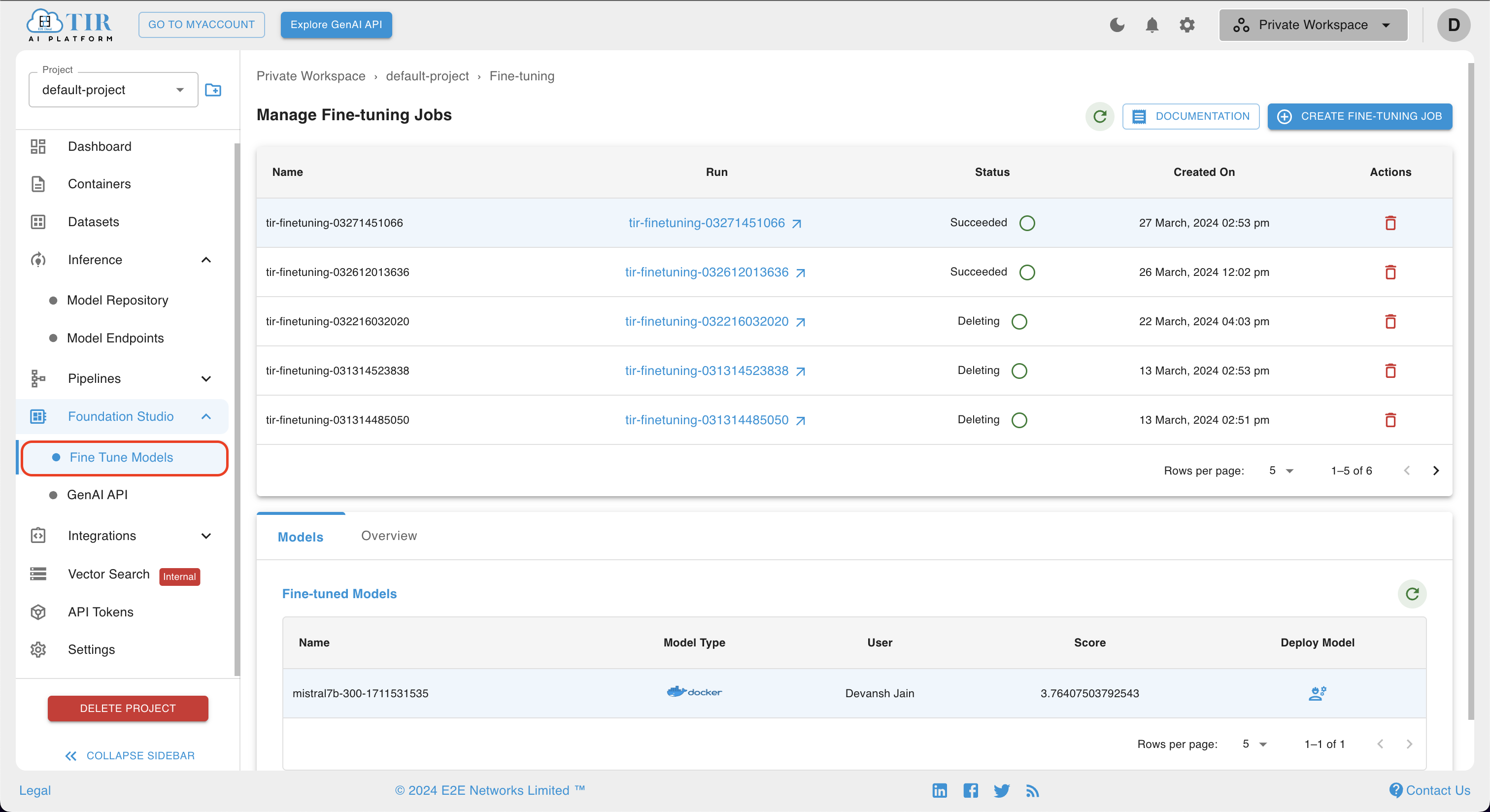
To initiate the Fine-Tuning Job process, first, the user should navigate to the sidebar section and select Foundation Studio. Upon selecting Foundation Studio, a dropdown menu will appear, featuring an option labeled Fine-Tune Models.
-
Upon clicking the Fine-Tune Models option, the user will be directed to the "Manage Fine-Tuning Jobs" page.
-
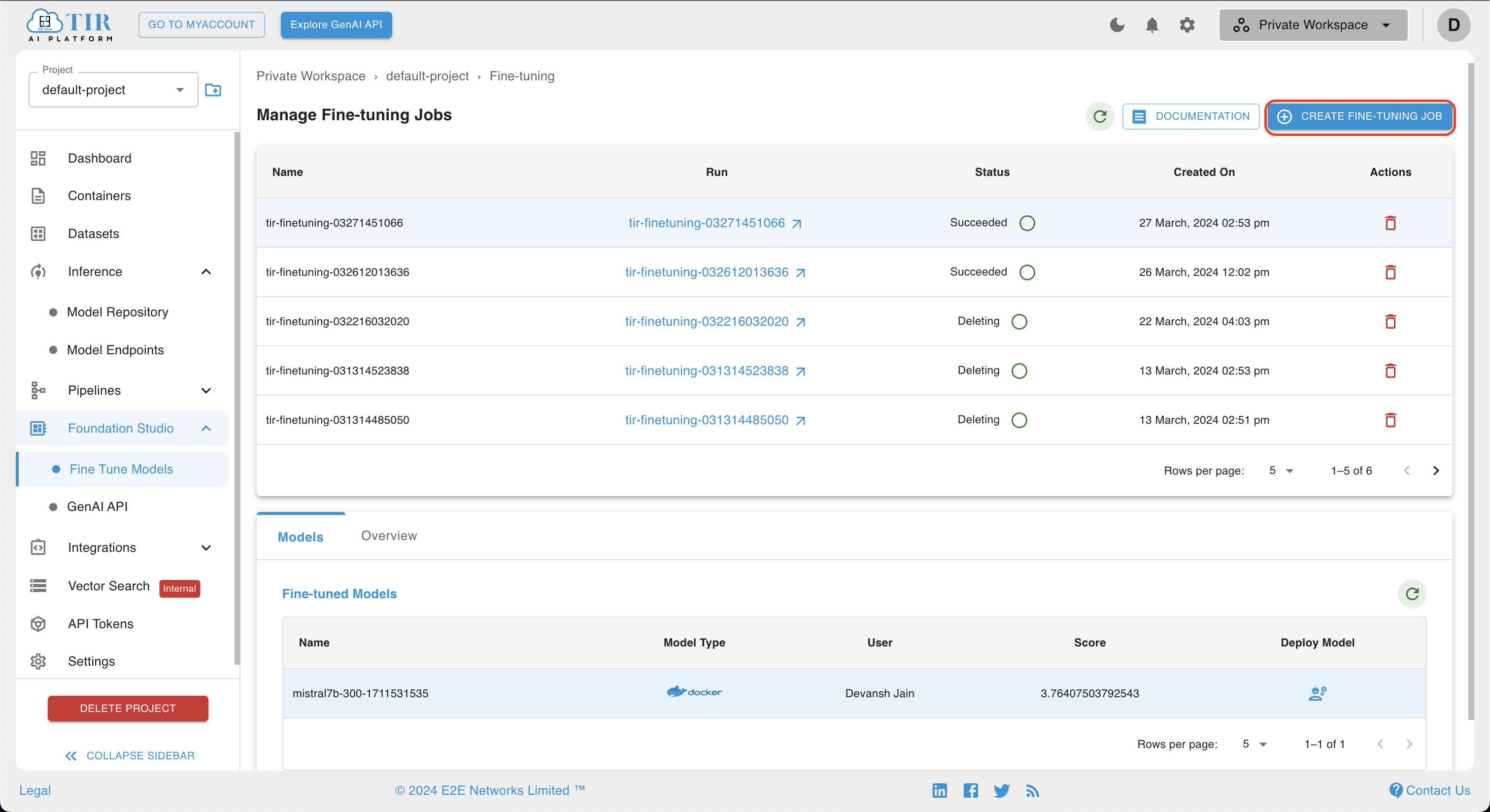
After redirecting to the Manage Fine-Tuning Jobs, users can locate and click on the Create Fine-Tuning Job button or Click-here button to create Fine-Tune models.
-
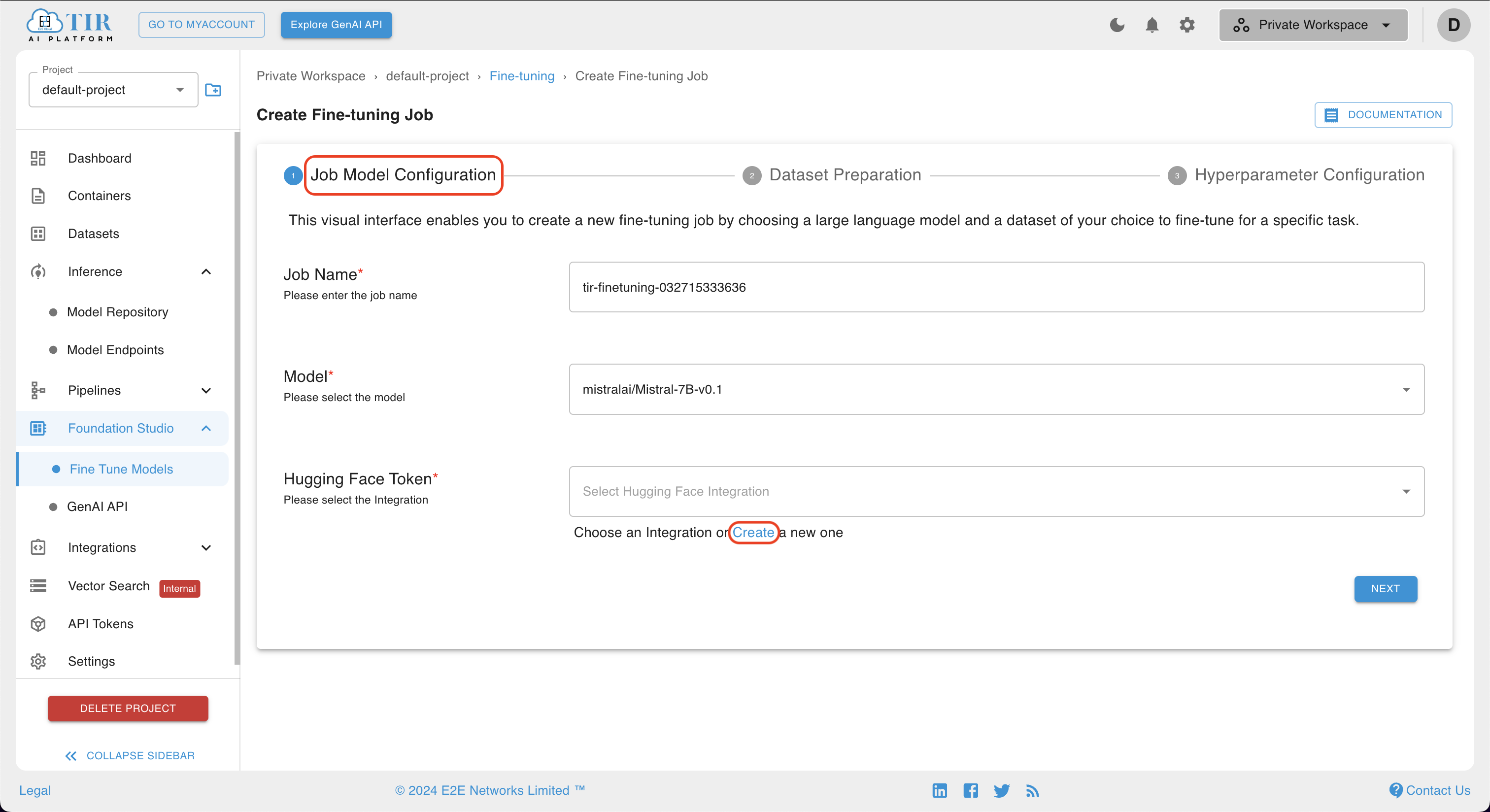
After clicking the Create Fine-Tuning Job button, the Create Fine-Tuning Job page will open. On this page, there are several options such as Job-Name, Model, and Hugging Face Token.
-
If the user already has an integration with Hugging Face token, they can select it from the dropdown options. If the user does not have any integration setup with Hugging Face, they can click on Create a new one, and the Create Integration page will open. After adding a token, the user can move to the next stage by clicking on the Create button.
If the user doesn't have a Hugging Face token, they would not be able to access certain services. In this case, you need to sign up for an account on Hugging Face and obtain an HF token to use their services.
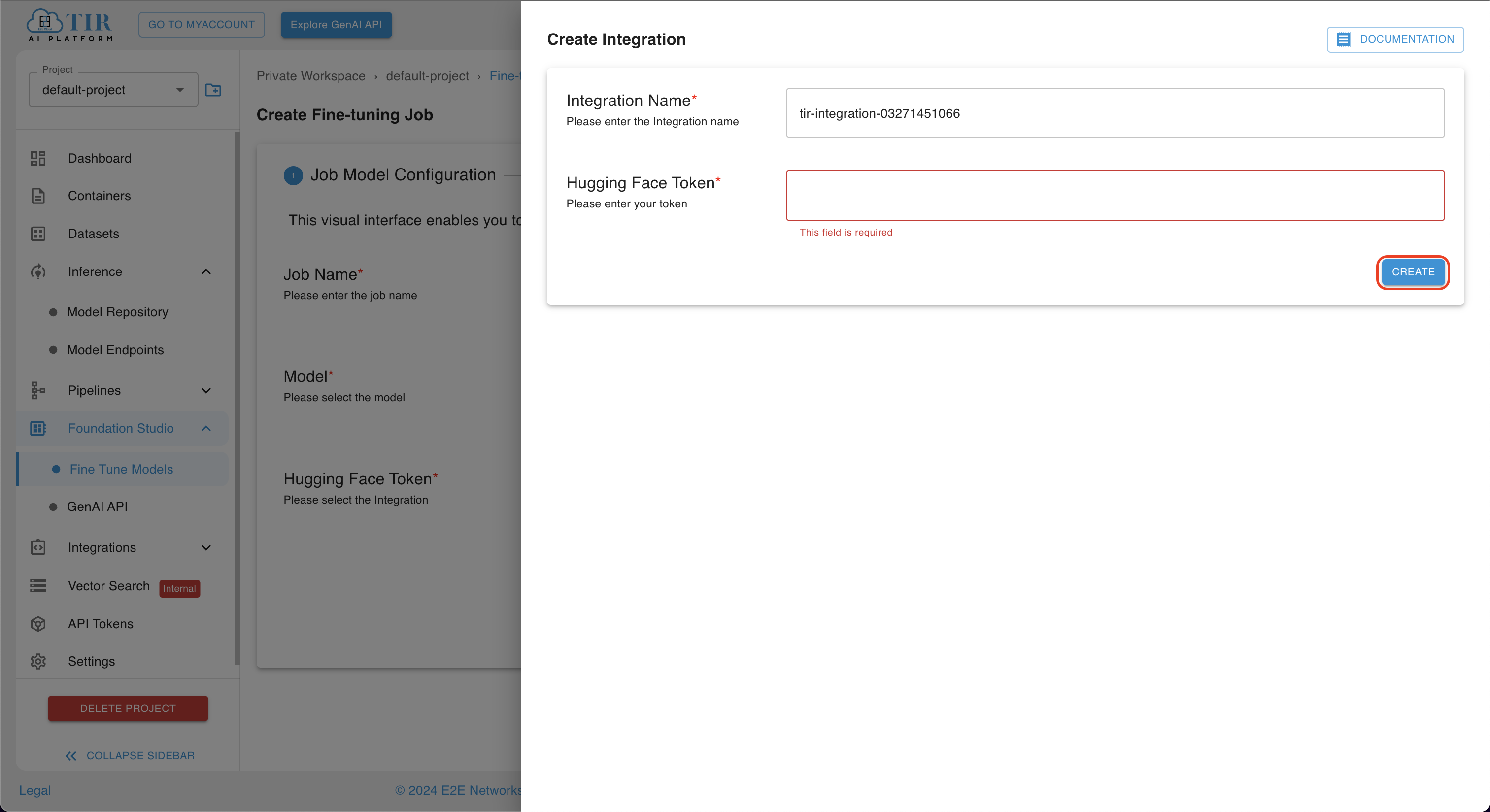
Some model are available for commercial use but requires access granted by their Custodian/Administrator (creator/maintainer of this model). You can visit the model card on huggingface to initiate the process.
How to Define Dataset Preparation?
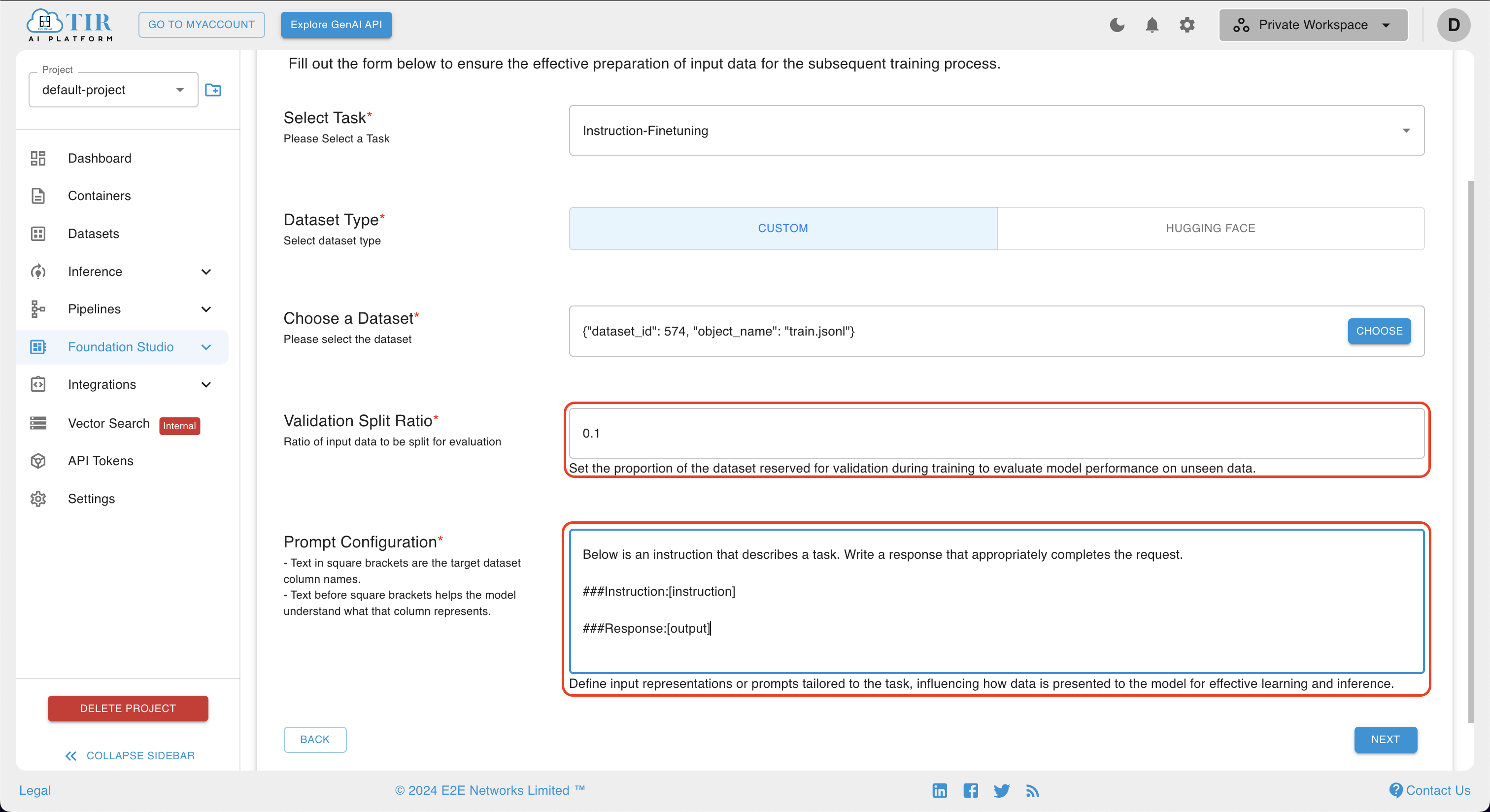
After defining the Job Model configuration, users can move on to the next section for Dataset Preparation. The Dataset page will open, providing several options such as Select Task, Dataset Type, Choose a Dataset, Validation Split Ratio, and Prompt Configuration. Once these options are filled, the dataset preparation configuration will be set, and the user can move to the next section.
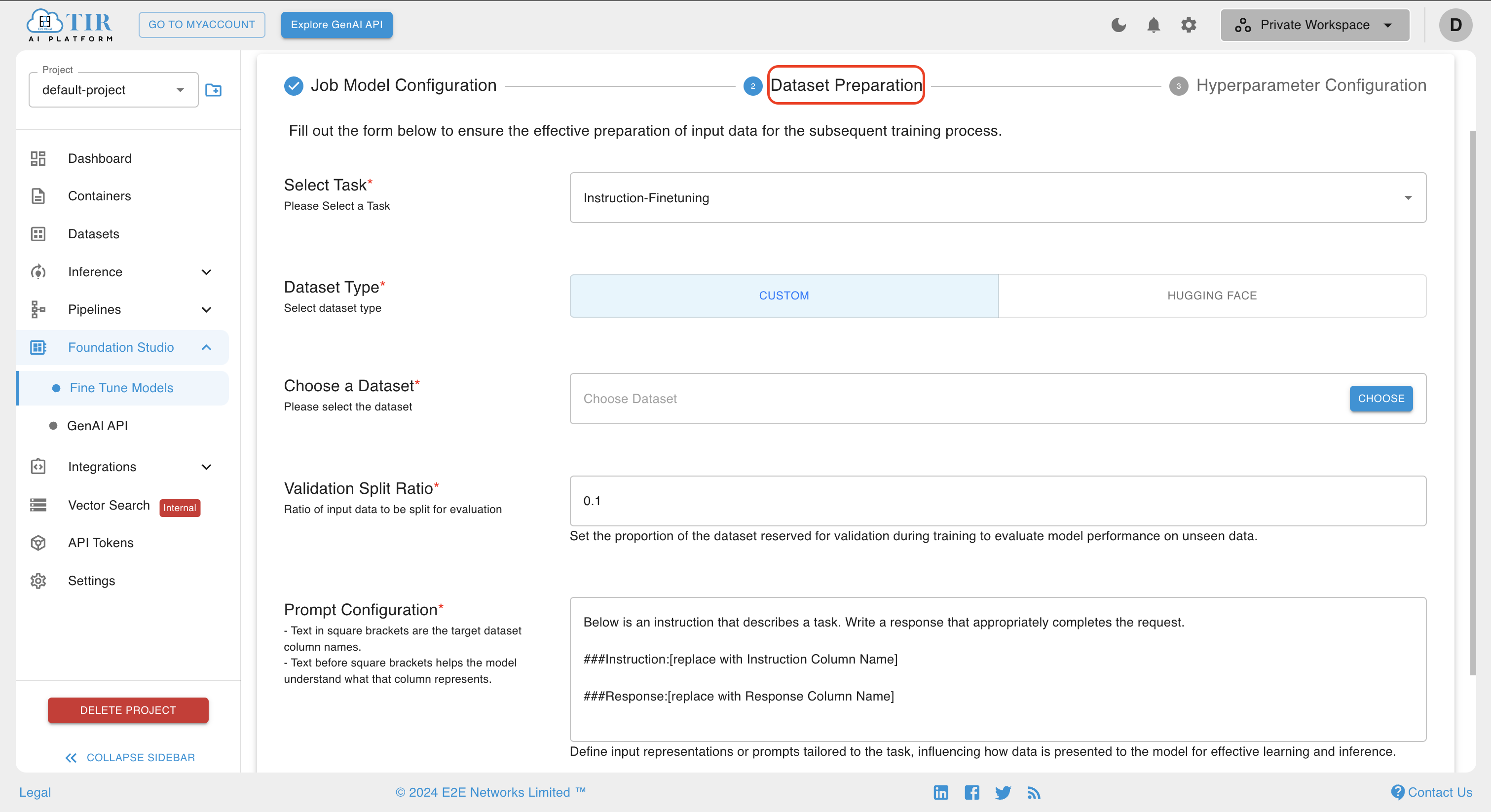
Dataset Type
In the Dataset Type, you can select either CUSTOM or HUGGING FACE as the dataset type. The CUSTOM Dataset Type allows training models with user-provided data, offering flexibility for unique tasks. Alternatively, the Hugging Face option provides a variety of pre-existing datasets, enabling convenient selection and utilization for model training.
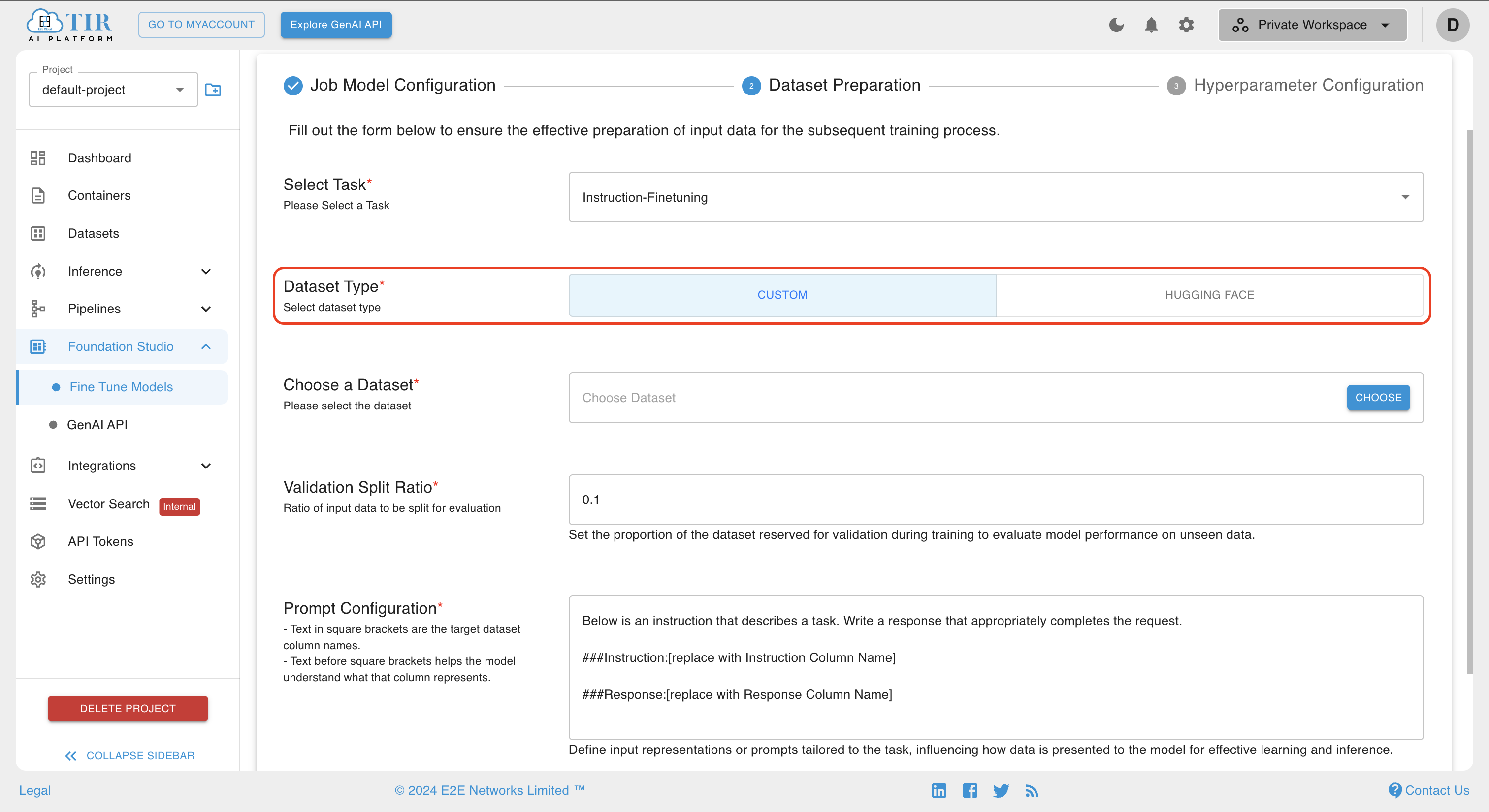
Choosing a Custom Dataset
If you select the dataset type as CUSTOM, you have to choose a user-defined dataset by clicking the CHOOSE button.
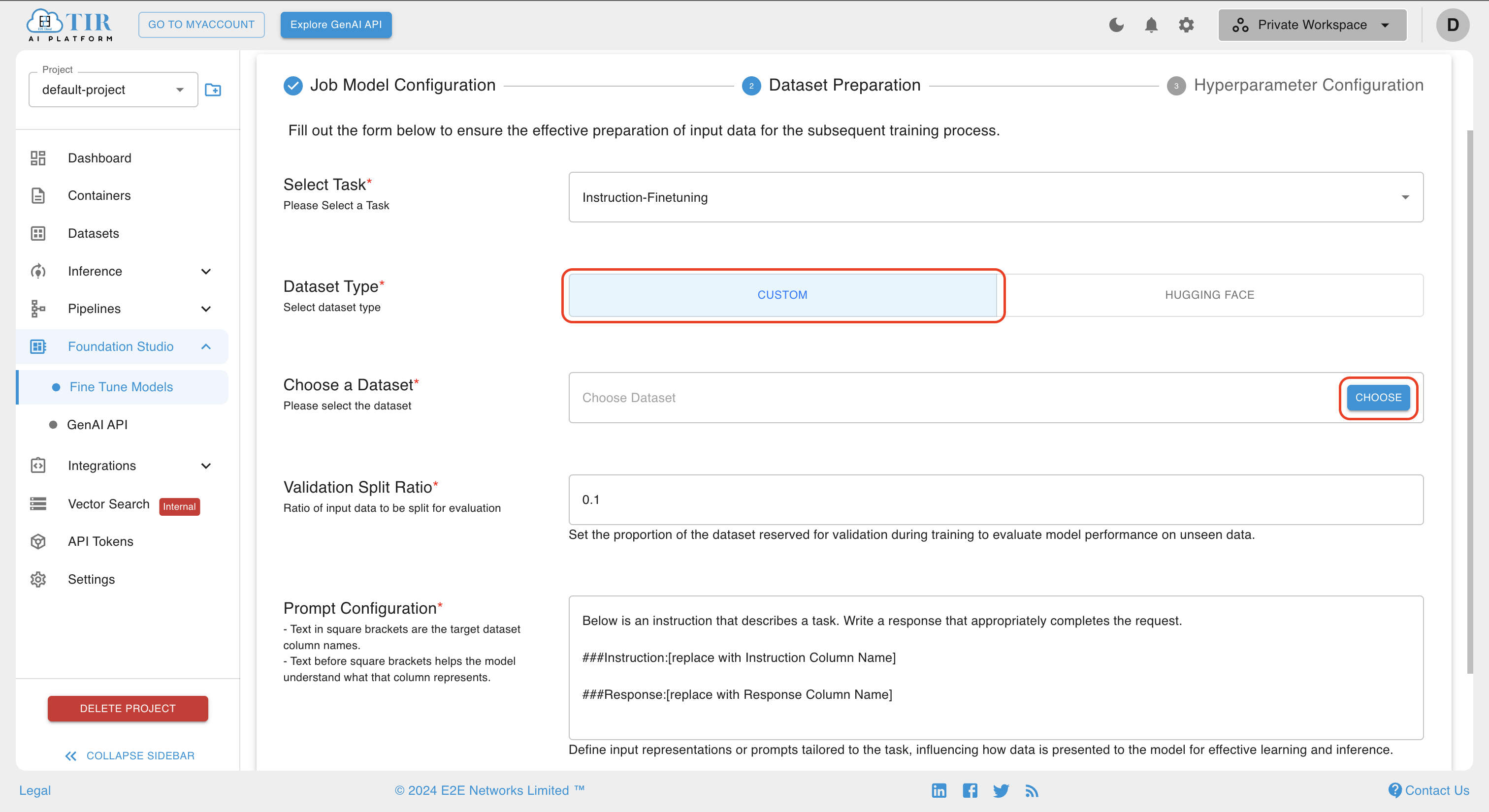
After clicking on the CHOOSE button, you will see the screen below if you have already objects in the selected dataset.
To ensure dataset compatibility, it is recommended to maintain your data in the .json, .jsonl, or parquet file format. Please verify and convert your dataset to these extensions prior to model training.
You can use this dataset containing Python code for testing purposes: Mistral_dataset
You can create a new dataset by clicking the click here link.
The listed datasets here use in EOS Bucket for data storage.
For Text Models like Mistral-7B, the dataset provided should be of the following format: one metadata file mapping inputs with the context text and a list of images in PNG format.
Example Dataset Format
{"input": "What color is the sky?", "output": "The sky is blue."}
{"input": "Where is the best place to get cloud GPUs?", "output": "E2E Networks"}
Uploading incorrect dataset format will result into finetuning run failure.
Here, labels "input" and "output" will be provided in prompt configuration.
You can provide the prompt configuration by specifying in the dialog box in the following format:
Example Prompt Configuration
Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Field_Description: [Name_of_the_field]
We have taken a custom dataset that has two fields: instruction and output. So the prompt configuration will look like this:
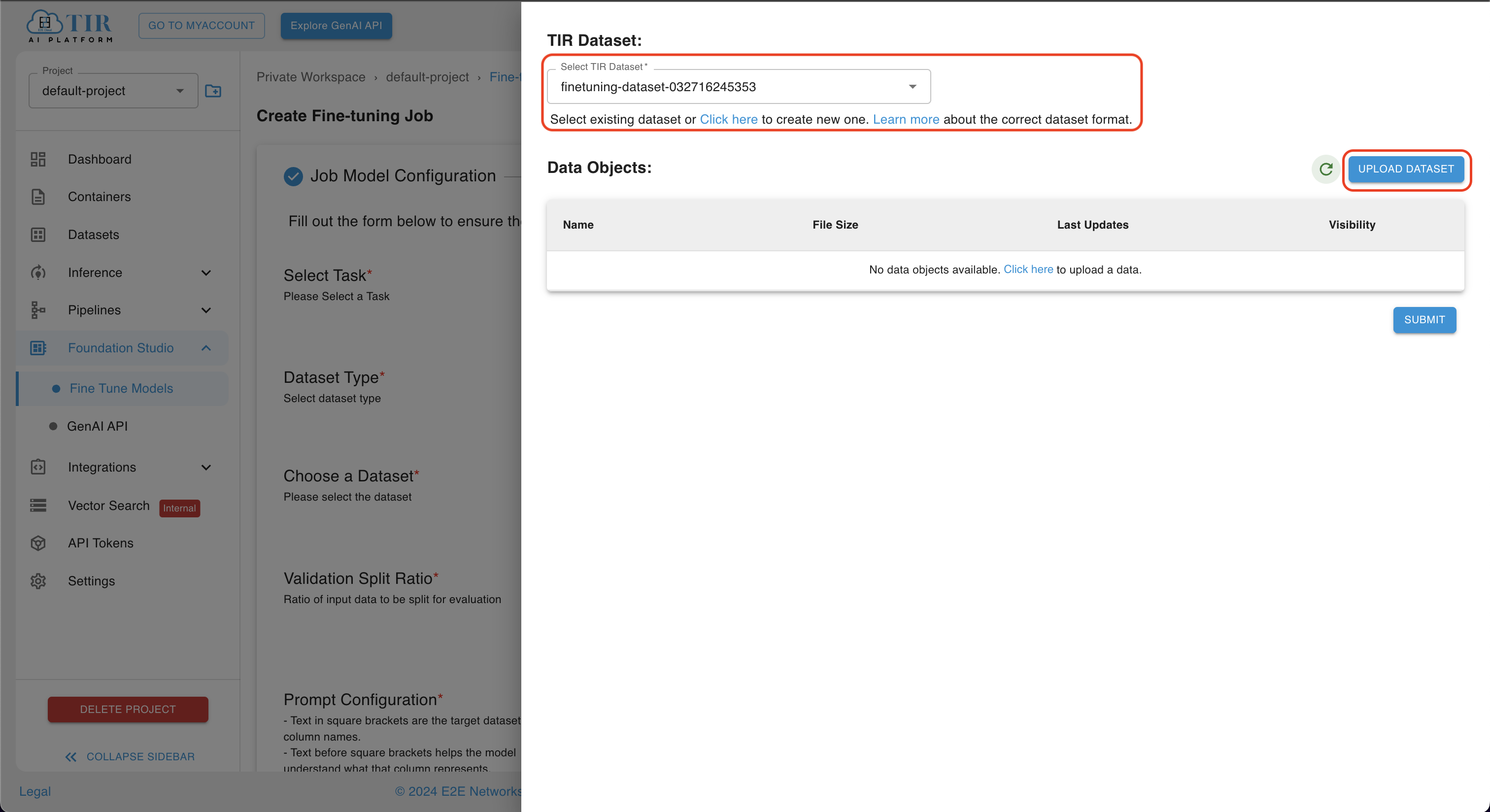
UPLOAD DATASET
- After selecting the dataset, you can upload objects in a particular dataset by selecting the dataset and clicking on the
UPLOAD DATASETbutton.
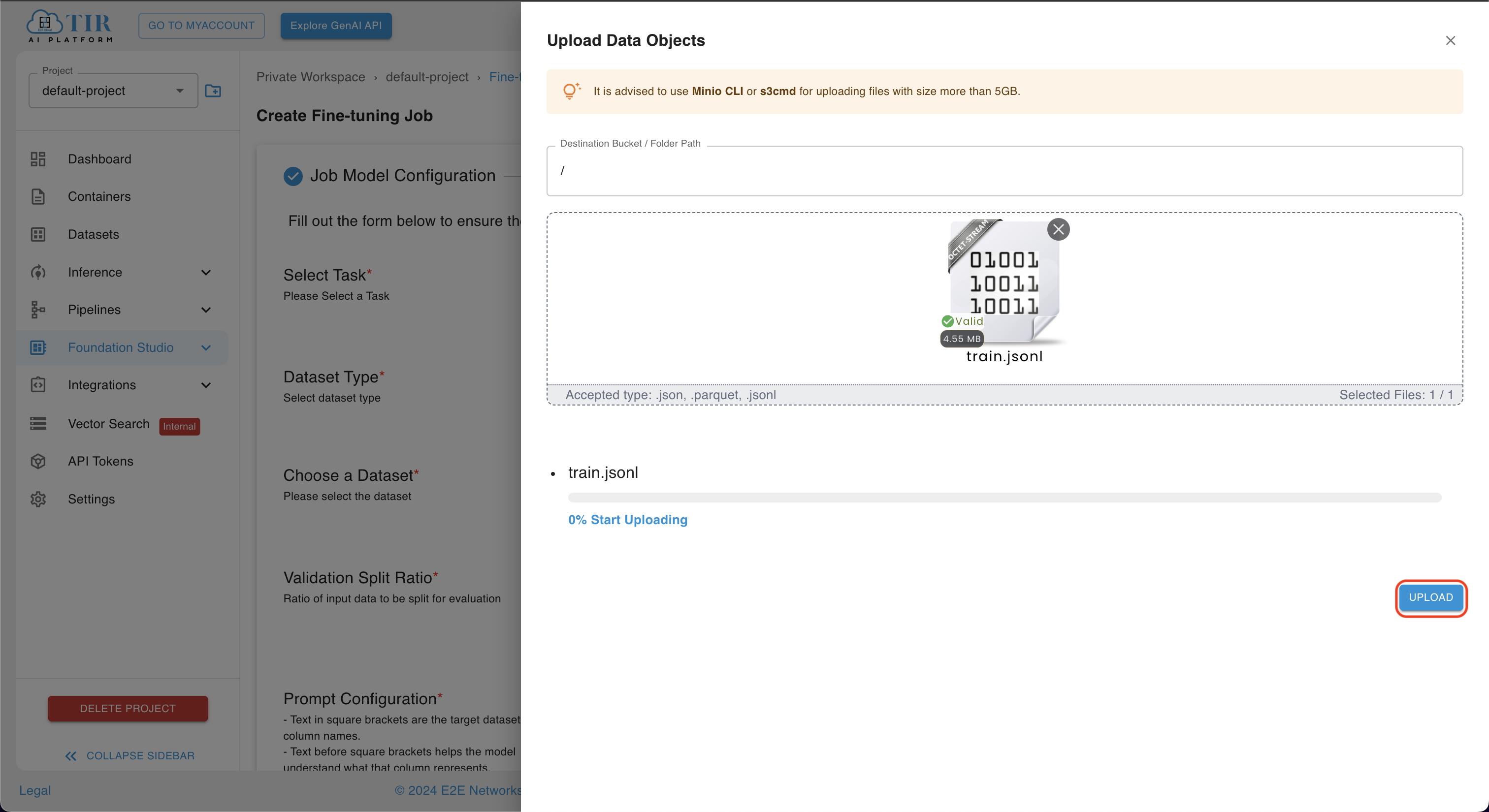
- Click on the
UPLOAD DATASETbutton, upload objects, and then click on theUPLOADbutton.
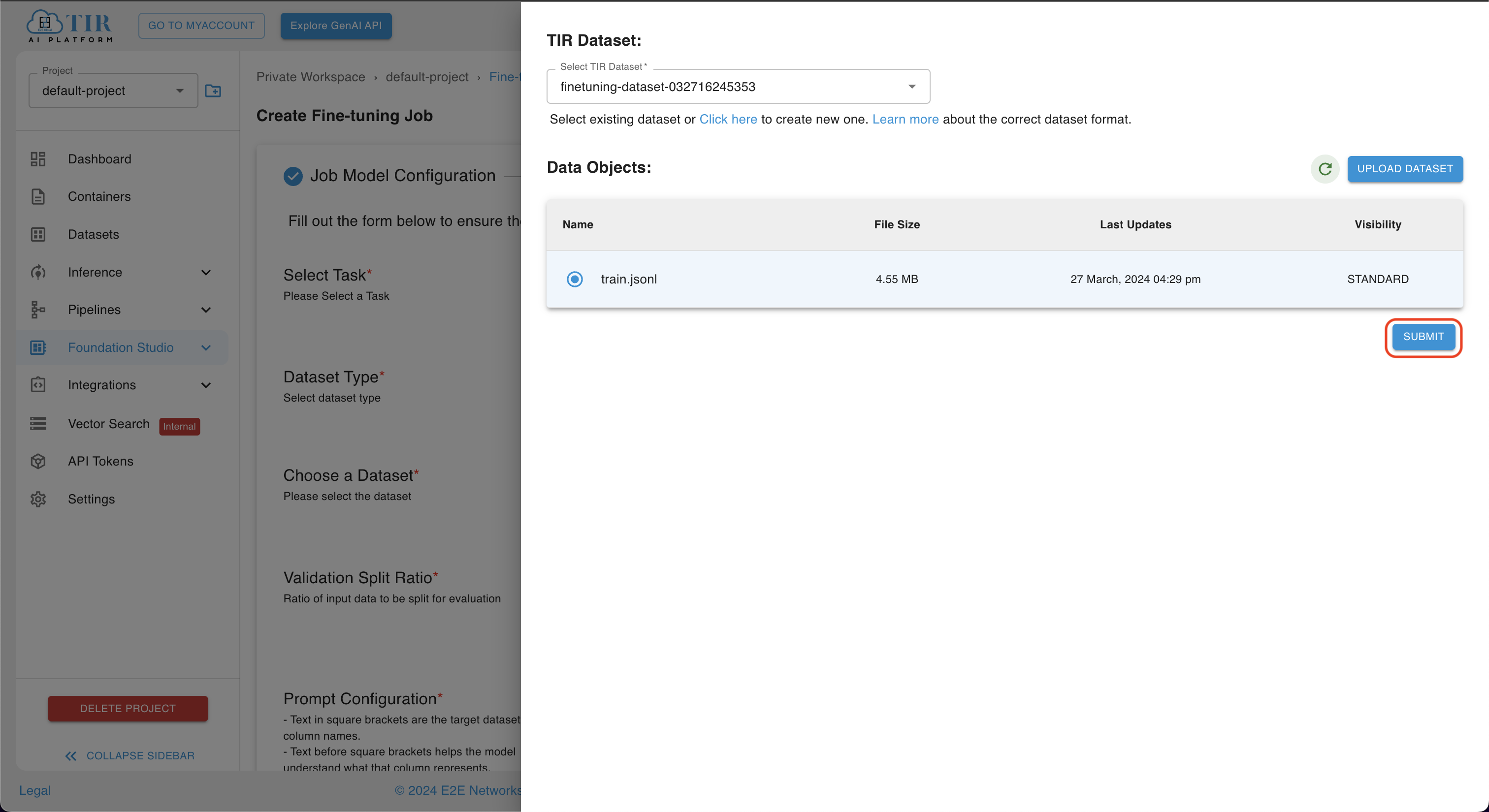
- After uploading objects to a specific dataset, choose a particular file to continue, and then click on the
SUBMITbutton.
How to Define a Hyperparameter Configuration?
- Upon providing the dataset preparation details, users are directed to the
Hyperparameter Configurationpage. This interface allows users to customize the training process by specifying desired hyperparameters, thereby facilitating effective hyperparameter tuning. The form provided enables the selection of various hyperparameters, including but not limited to training type, epoch, learning rate, and max steps. Please fill out the form meticulously to optimize the model training process.
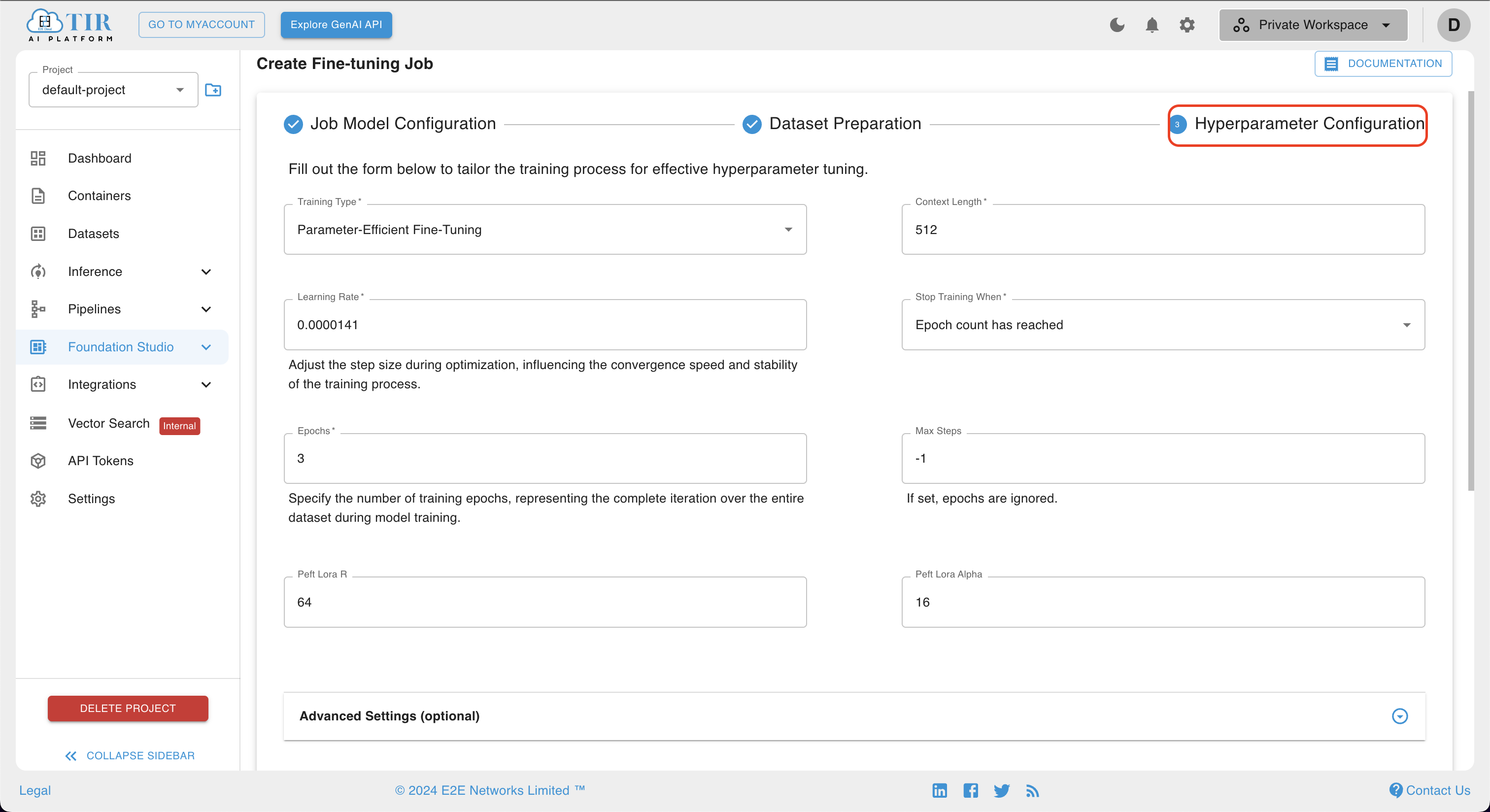
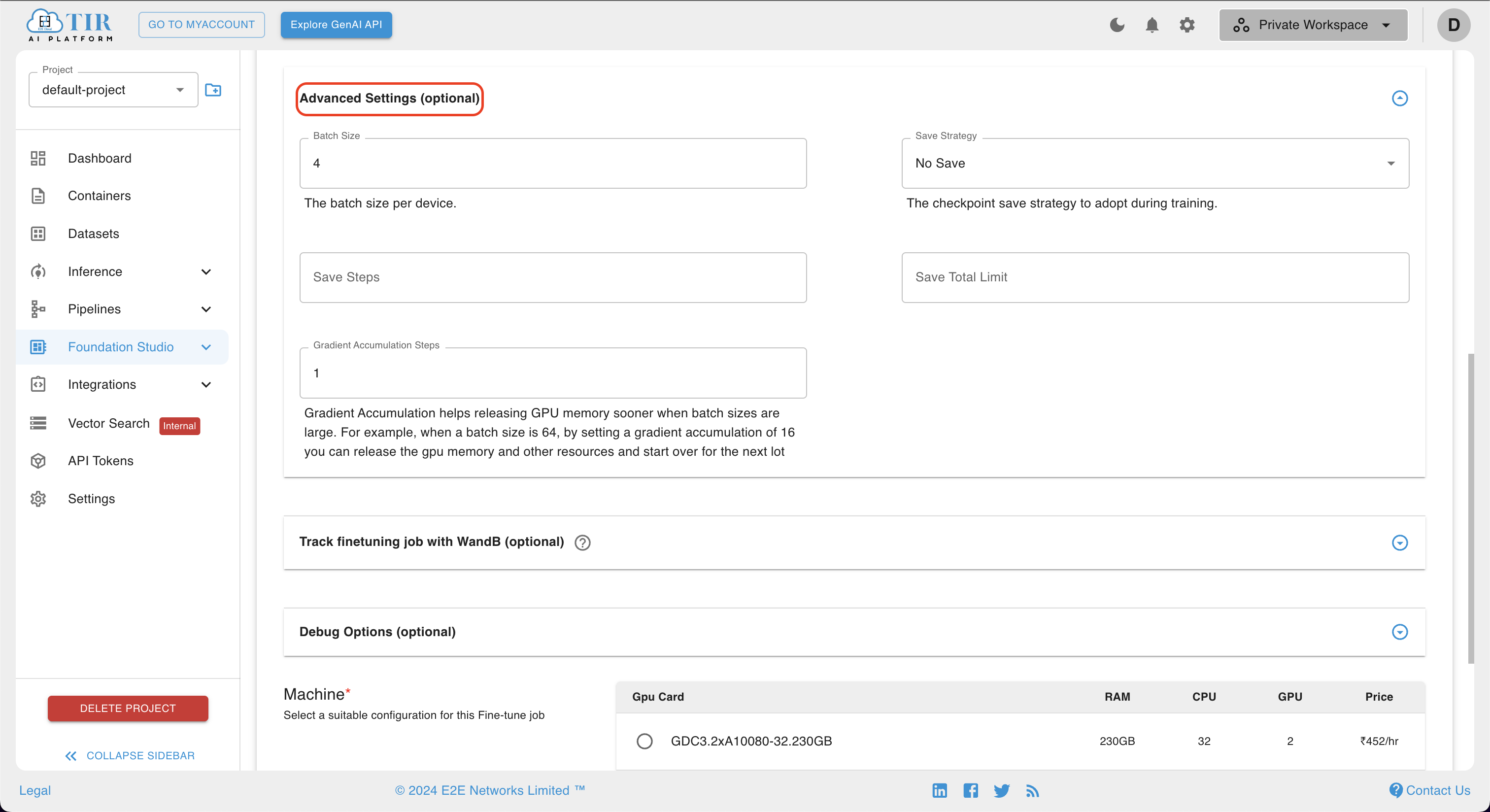
- In addition to the standard hyperparameters, the configuration page offers advanced options such as batch size and gradient accumulation steps. These settings can be utilized to further refine the training process. Users are encouraged to explore and employ these advanced options as needed to achieve optimal model performance.
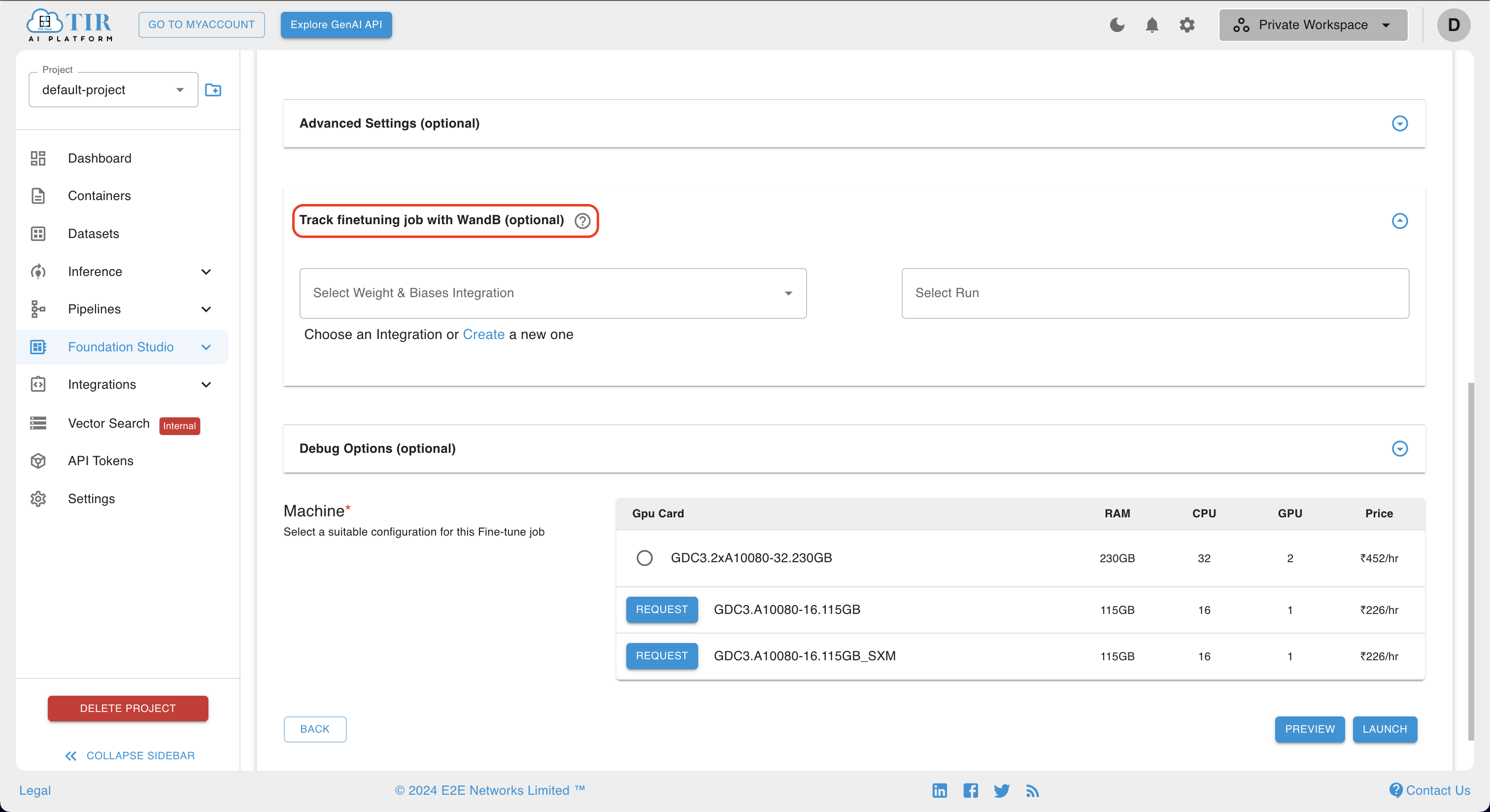
- Upon specifying the advanced settings, users are advised to leverage the WandB Integration feature for comprehensive job tracking. This involves proceeding to fill in the necessary details in the provided interface. By doing so, users can effectively monitor and manage the model training process, ensuring transparency and control throughout the lifecycle of the job.
- Users can also describe the
debugoption as desired for debugging purposes or quicker training.
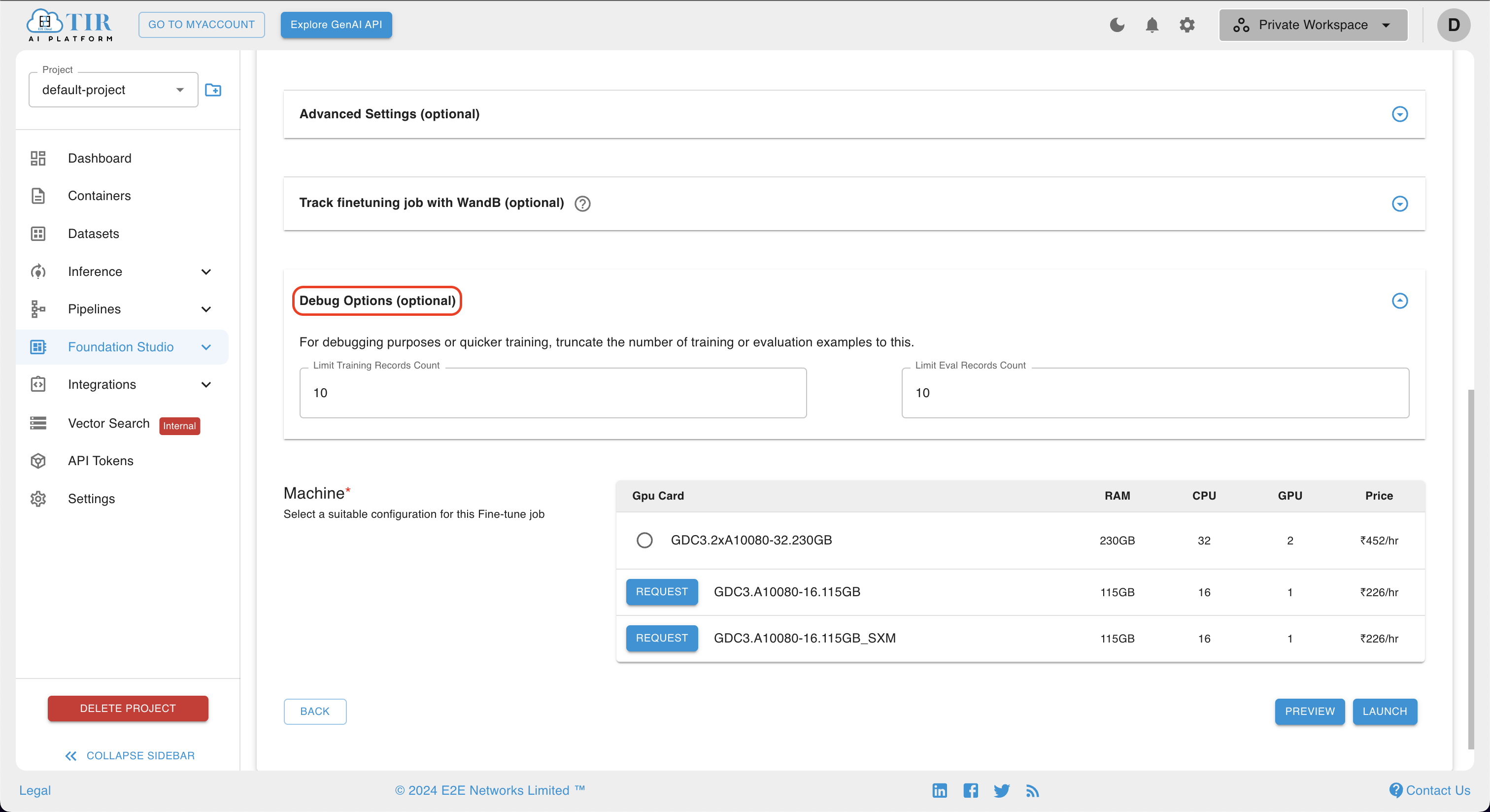
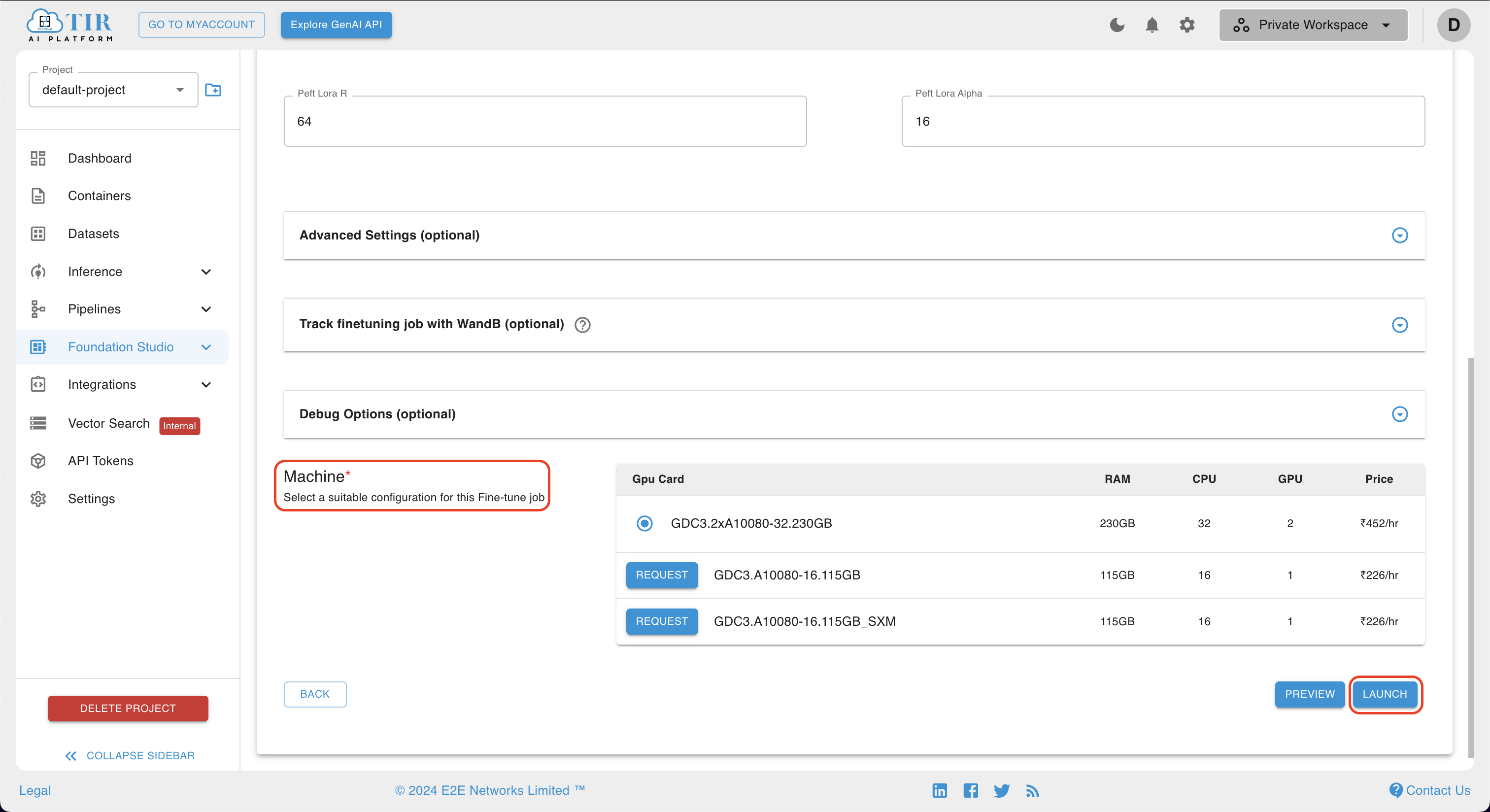
- Once the debug option has been thoroughly addressed, users are required to select their preferred machine configuration for the finetuning job. Subsequently, clicking on the
LAUNCHbutton will initiate or schedule the job, depending on the chosen settings. To ensure fast and precise training, a variety of high-performance GPUs, such as Nvidia H100 and A100, are available for selection. This allows users to optimize their resources and accelerate the model training process.
Viewing Your Job Parameters and Fine-Tuned Models
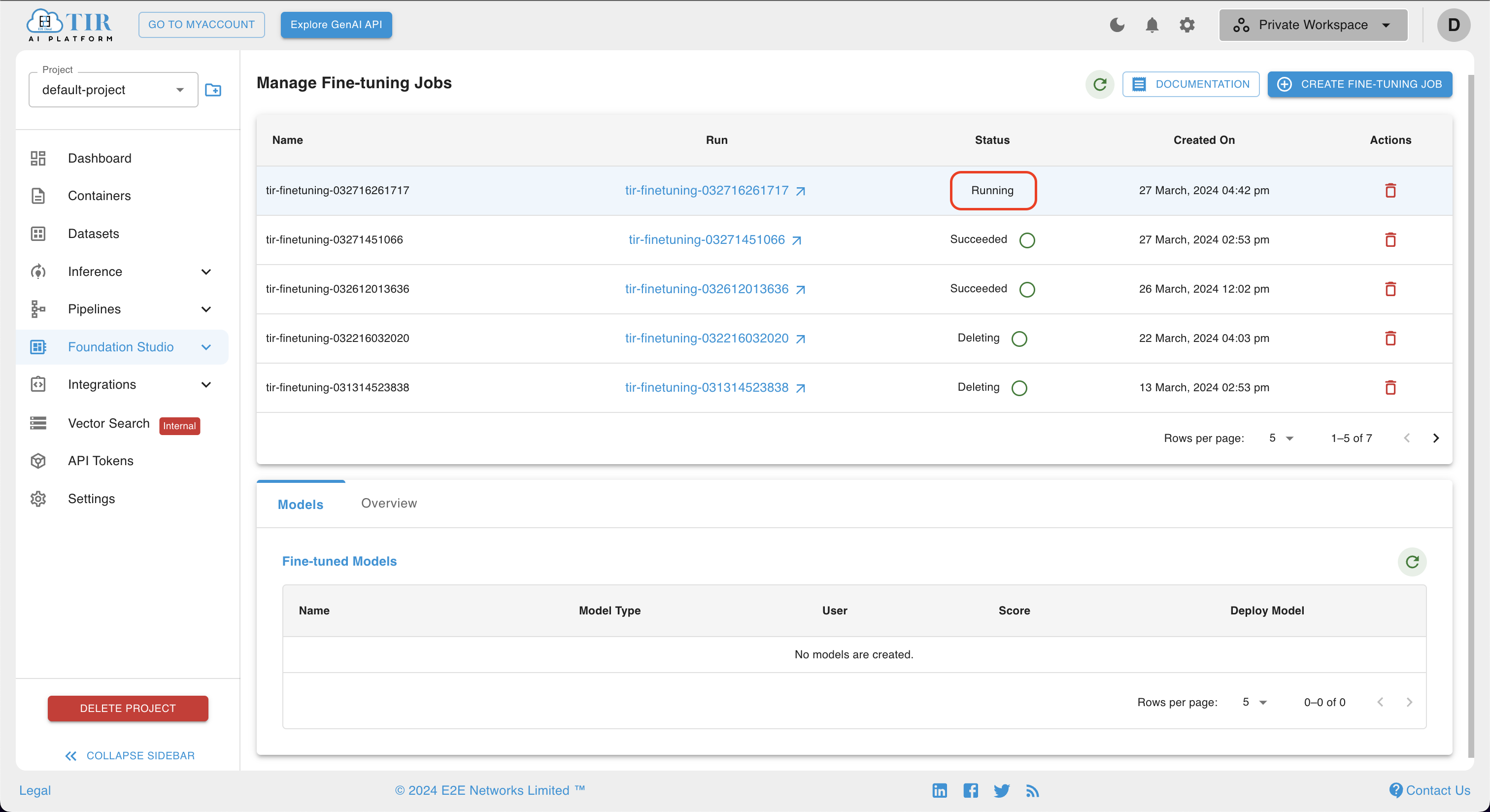
- On completion of the job, a Fine-Tuned model will be created and will be shown in the models section at the lower part of the page. This fine-tuned model repo will contain all checkpoints of model training as well as adapters built during training. Users can also directly go to the model repo page under inference to view it.
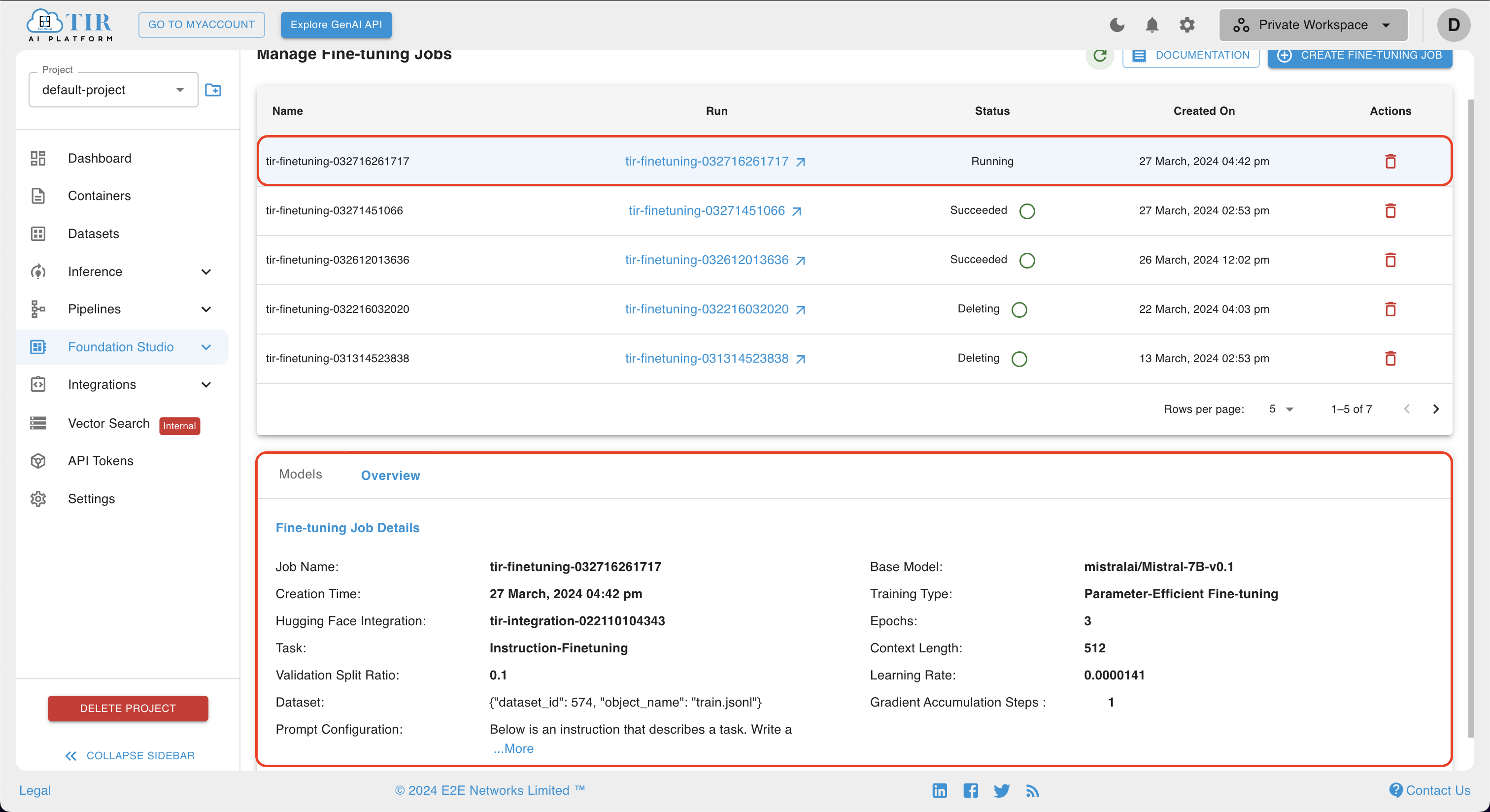
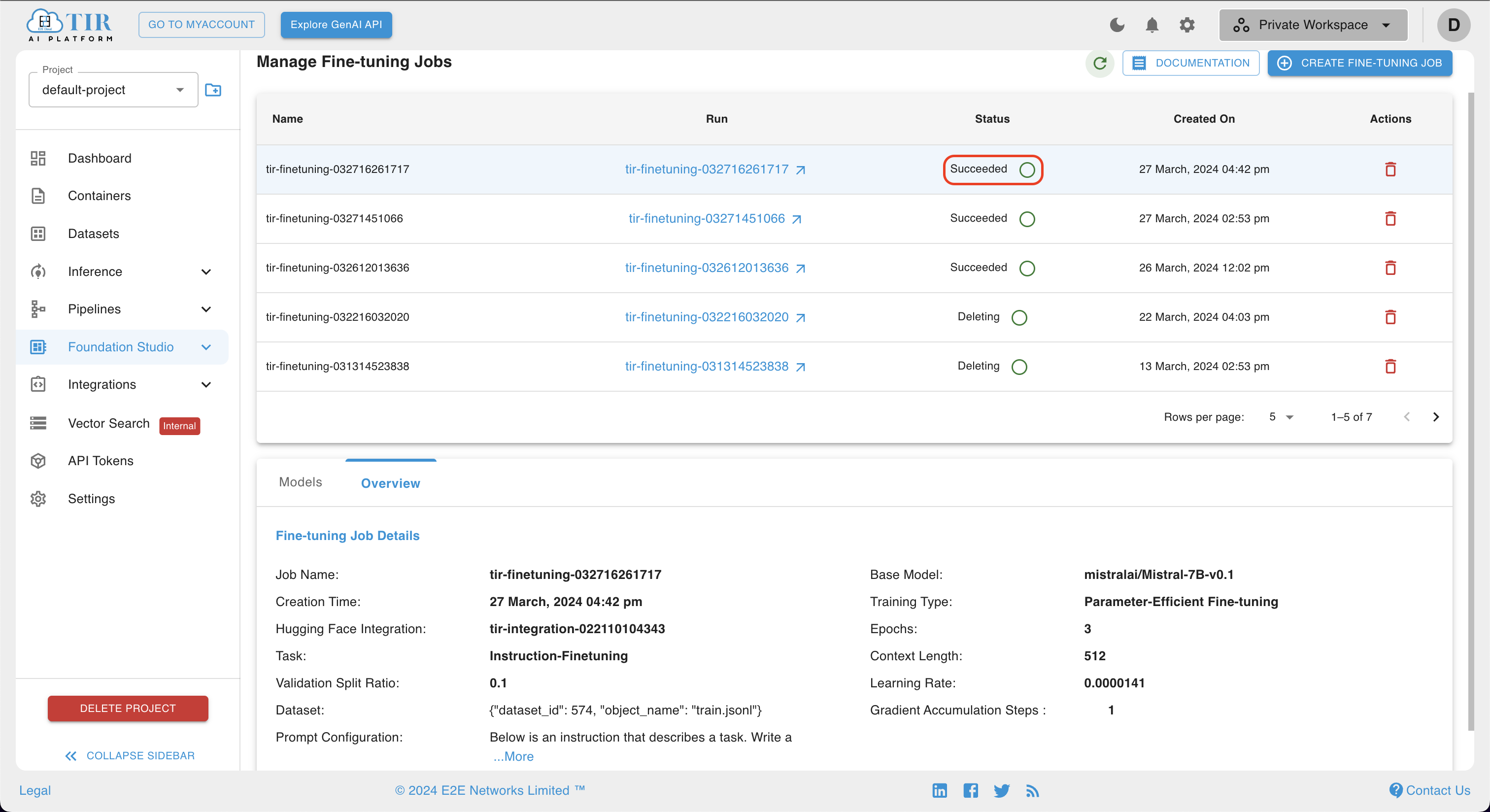
- If desired, the user can view job parameter details in the overview section of the job, as shown below.
- Users can effortlessly access the logs of the model training by clicking on the run of the fine-tuning job they've created. These logs serve as a valuable resource, aiding users in debugging the training process and identifying any potential errors that could impede the model's progress.
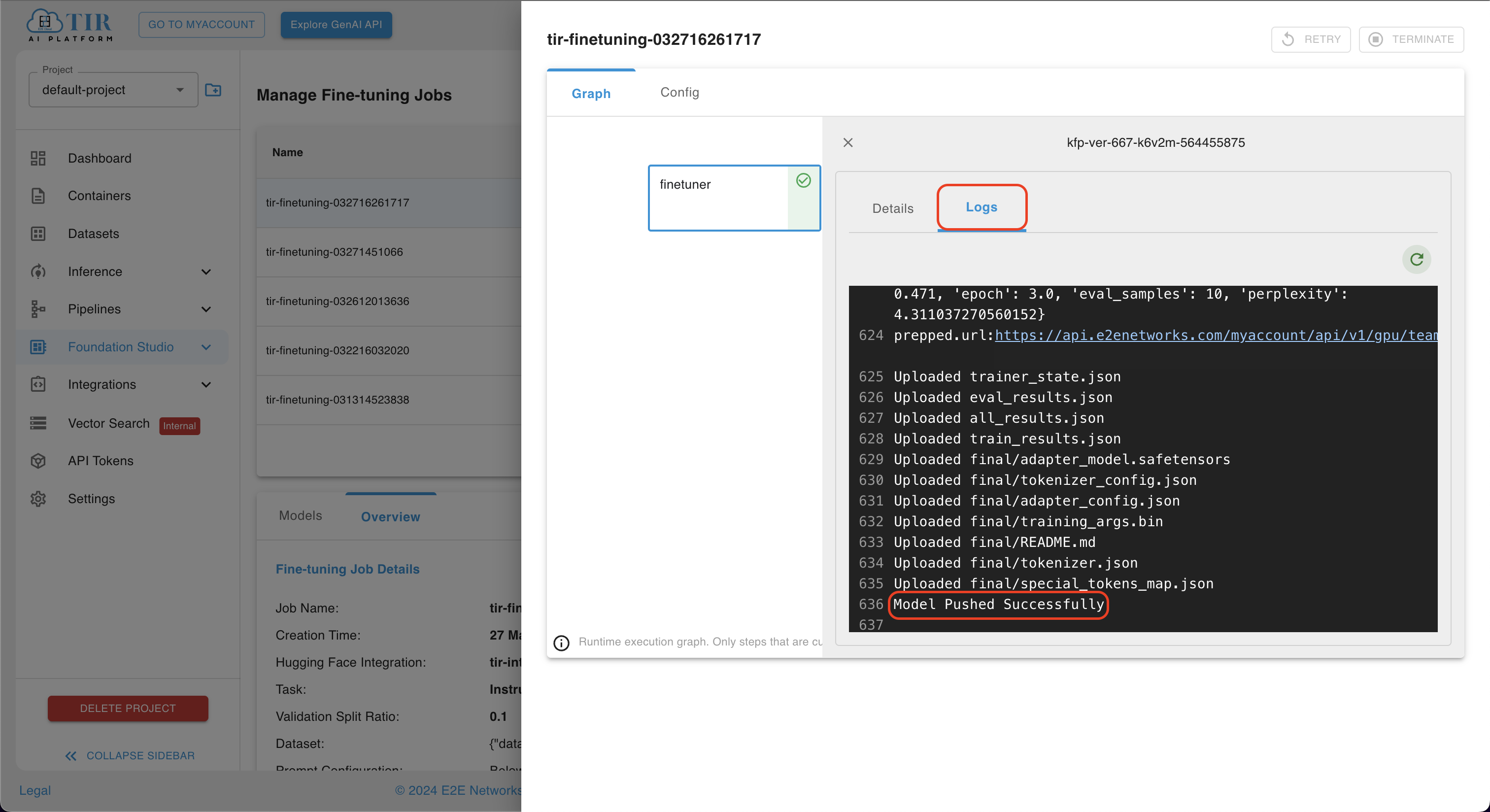
- Upon successful completion of training, the model will be seamlessly pushed, ensuring smooth integration with our existing model infrastructure.
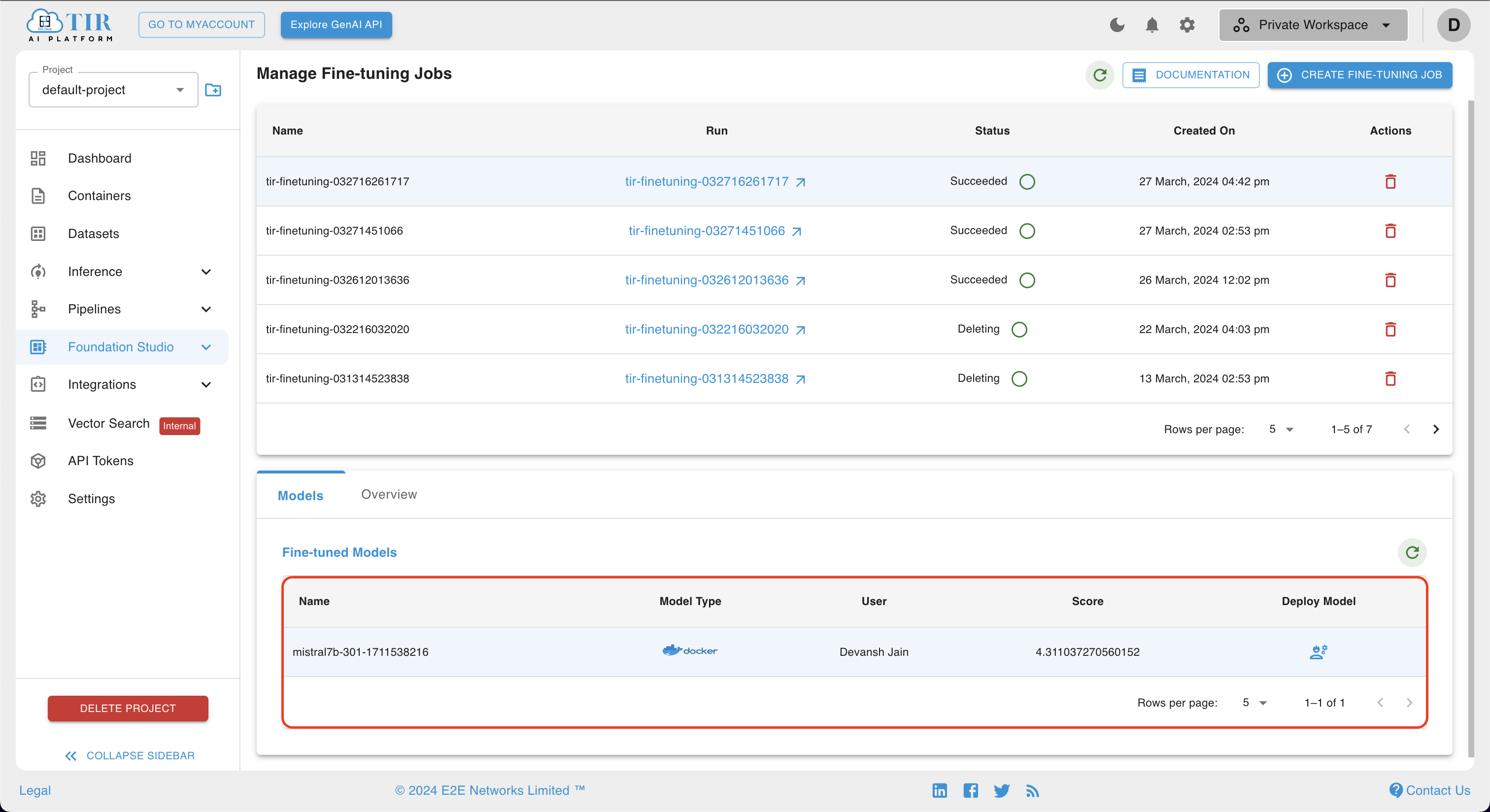
Running Inference on the Fine-Tuned Mistral Model
Upon successful completion of model training, the fine-tuned Mistral-7B model can be conveniently accessed and viewed under the Models section.
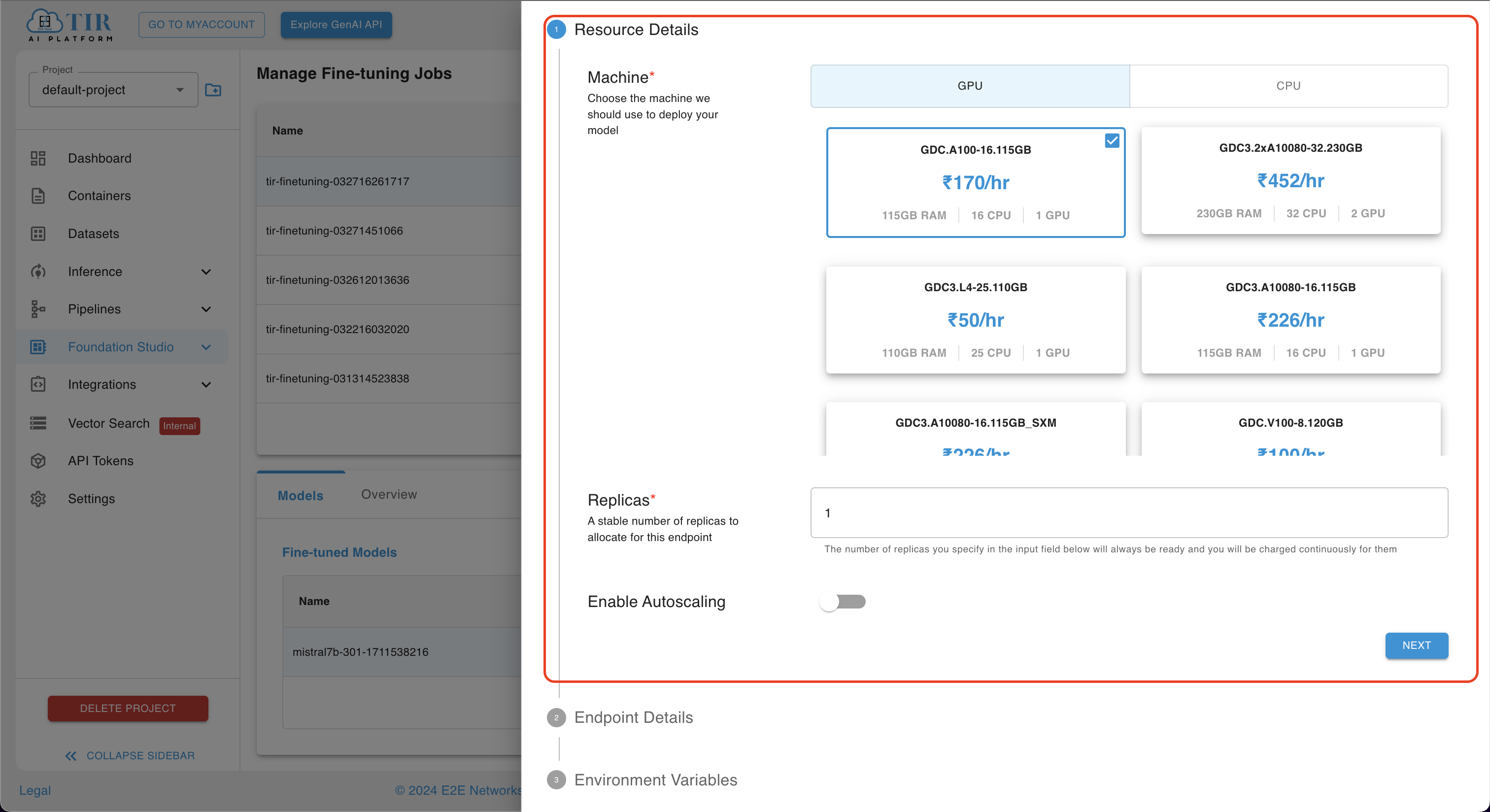
Deployment of Fine-Tuned Mistral-7B
Selecting the Deploy icon reveals a sidebar featuring different menus, including Resource Details, Endpoint Details, and Environment Variables.
-
Within the Resource Details menu, users can specify their desired CPU/GPU configuration and set the number of replicas. Once configurations are finalized, users can proceed by clicking on the Next button.
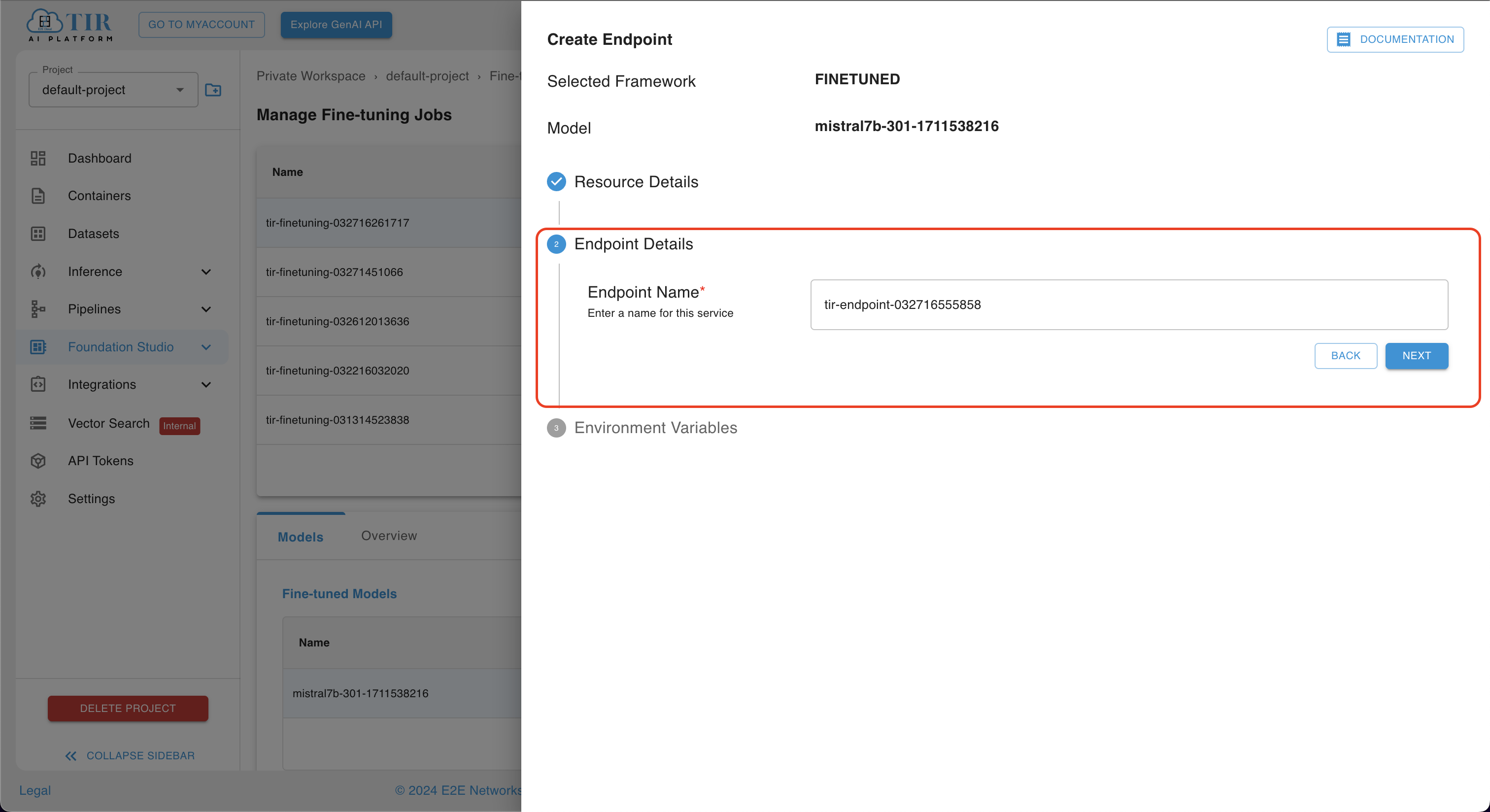
-
In the Endpoint Details section, users can either enter a custom name for the endpoint or opt to use the default name provided. We have used the default name.
-
In the Environment Variables section, input your HuggingFace token for authentication purposes.
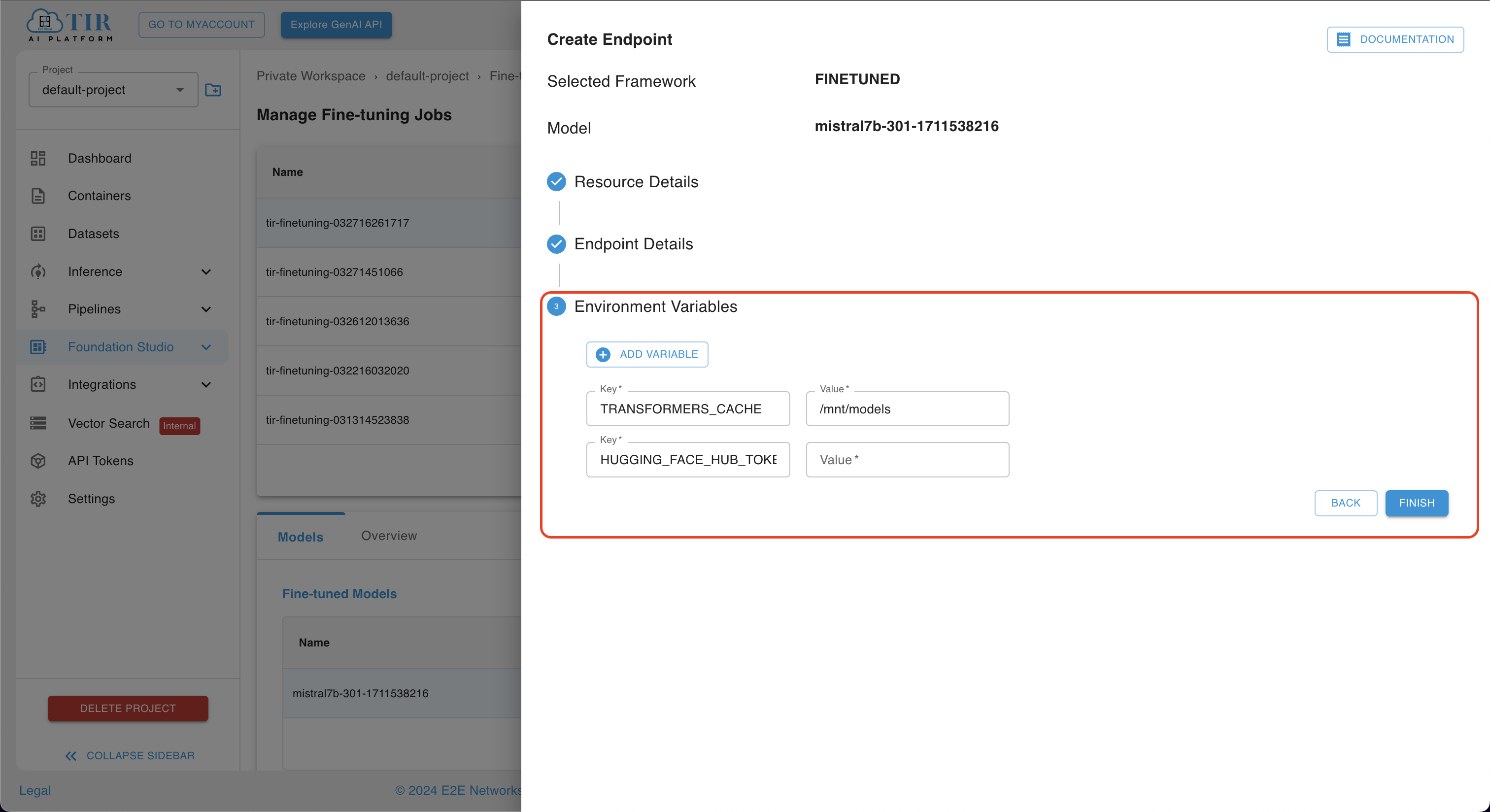
-
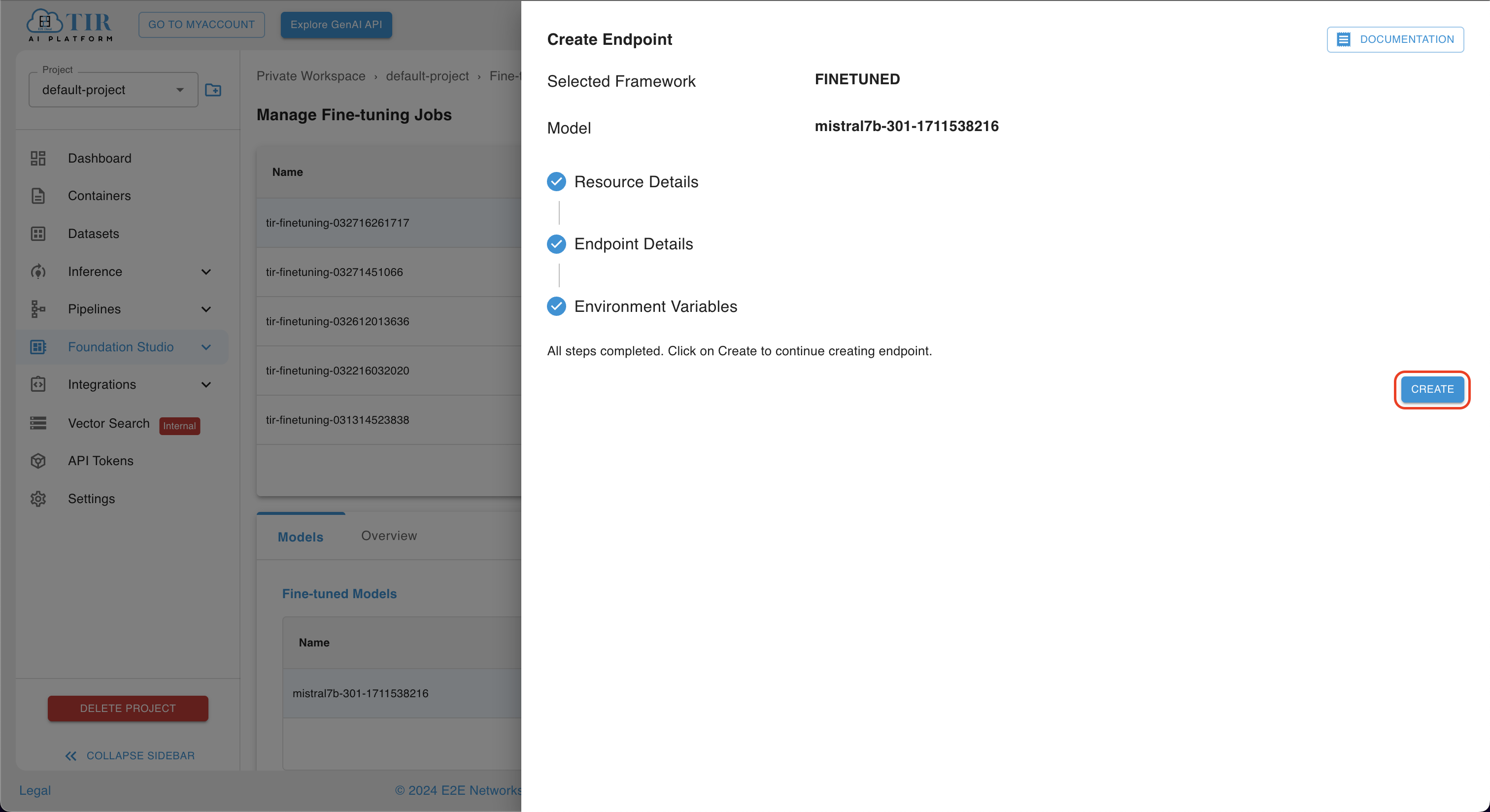
Following the completion of the aforementioned steps, proceed by selecting the Create option. This action will initiate the creation process for your model endpoint.
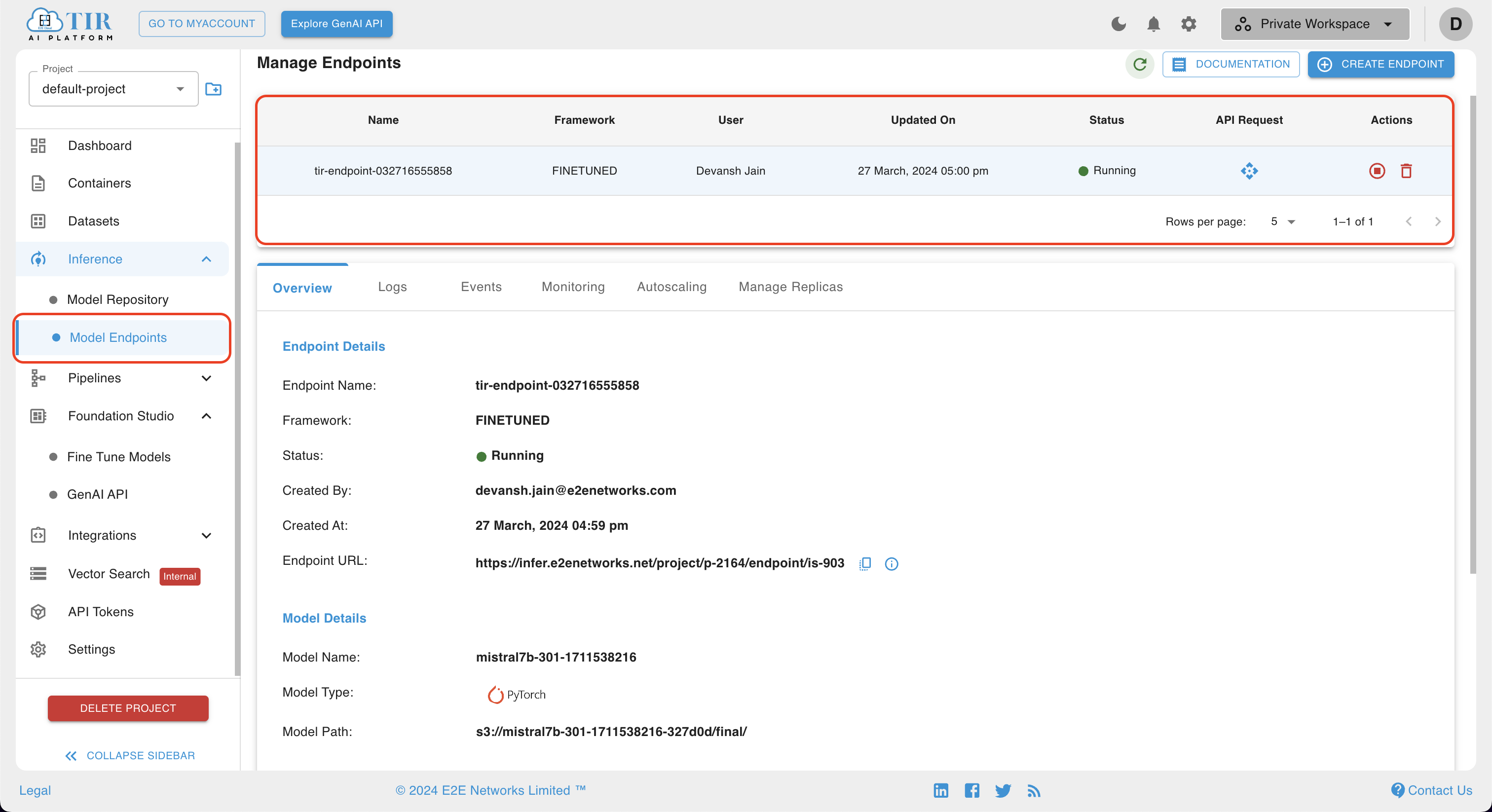
Running Inference on the Model Endpoint
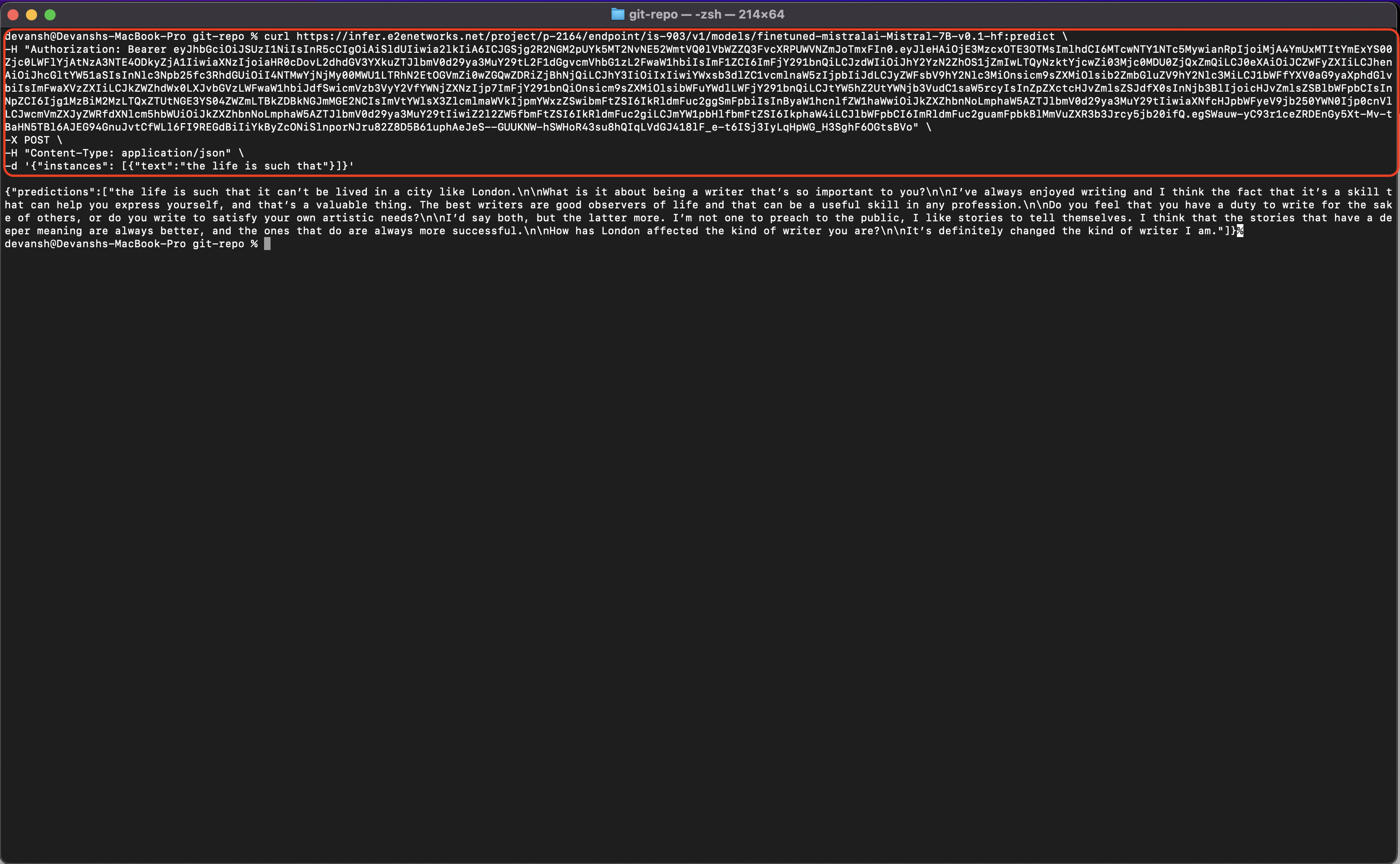
Navigate to the Inference section and select the Model Endpoint option to access the details of your created model endpoint. Here, you can monitor the status of your model endpoint. Once the status changes to Running, you can proceed by clicking on the API Request icon to make requests to your endpoint.
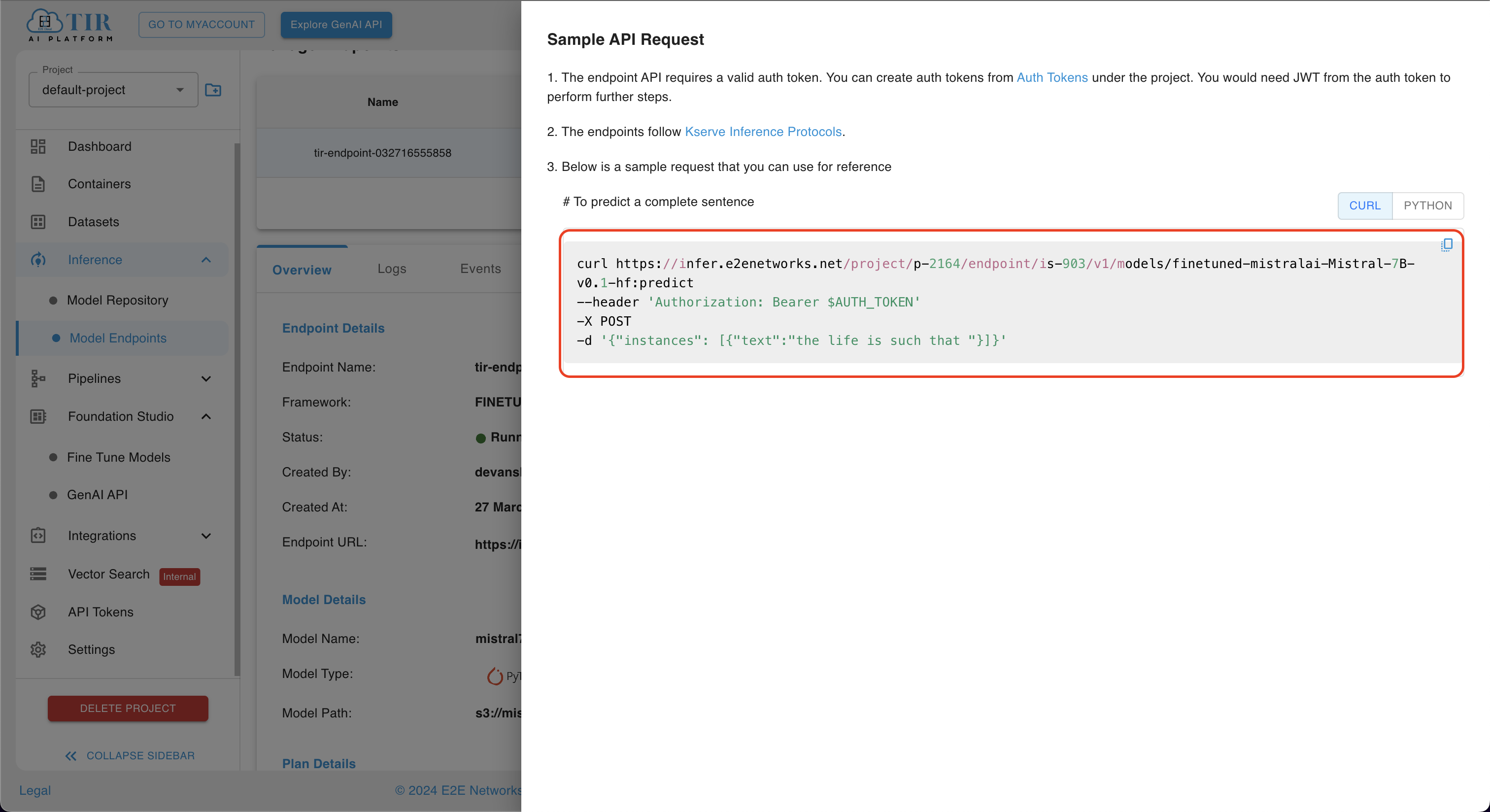
A sidebar menu titled Sample API Request will appear. Within this menu, you have two options for running inference:
-
Curl Script: Execute the provided curl script on your terminal of your local machine.
-
Python Script: Run the provided Python script on your terminal or any code editor of your choice.
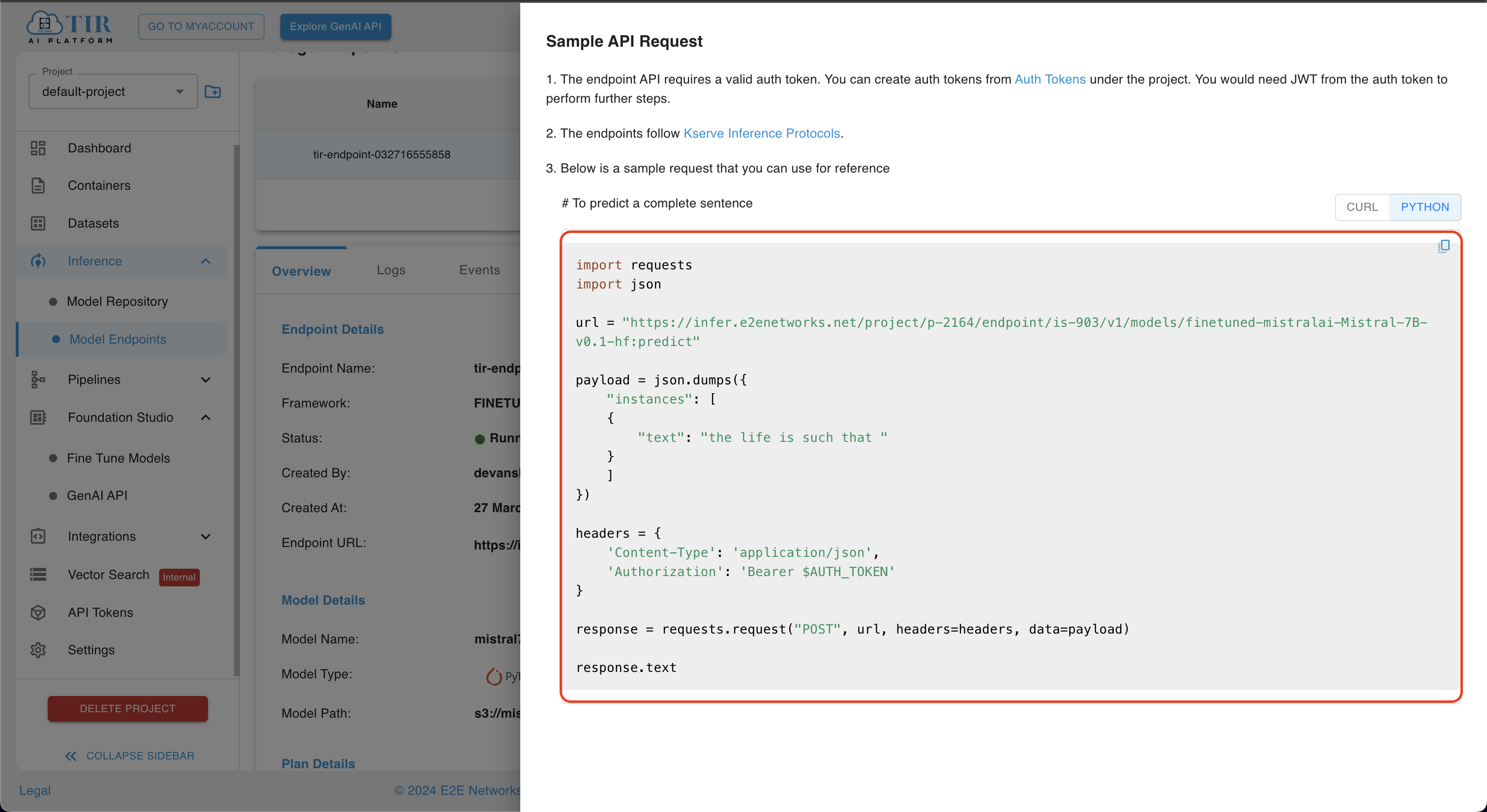
Ensure to replace the placeholder $AUTH_TOKEN in the script with your actual API authentication token. You can locate your authentication token in the "API Tokens" section. If you don't have an authentication token, you can generate a new one from the same section.
Choose the method that best suits your workflow preferences to perform inference with your model endpoint.