Mistral7B LLM with RAG for QnA
Retrieval Augmented Generation (RAG) enhances Large Language Models (LLMs) by addressing issues like outdated training data and the tendency for LLMs to generate inaccurate responses when faced with gaps in knowledge. By combining information retrieval with text generation, RAG anchors LLMs with precise, up-to-date information from an external knowledge store, enabling the creation of domain-specific applications.
Implementation Details
This documentation explores the implementation of RAG using the documentation data of E2E Networks Limited. We’ll leverage vector embedding and Qdrant (vector database) services provided by E2E Networks to achieve this.
Basic Architecture of RAG
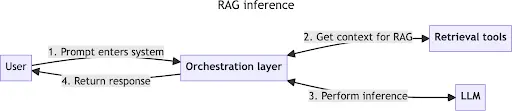
The basic architecture of a RAG-enabled LLM application involves three main components:
Orchestration Layer: This layer receives user input, interacts with retrieval tools and LLMs, and returns the generated response. It typically consists of tools like LangChain, Semantic Kernel, and native code.
Retrieval Tools: These utilities retrieve context from knowledge bases or API-based retrieval systems. They provide the necessary information to ground LLM responses.
LLMs: The Large Language Models receive prompts from the orchestration layer and generate responses based on the provided context.

In a typical LLM application, your inference processing script connects to retrieval tools as necessary. If you’re building an LLM agent-based application, each retrieval utility is exposed to your agent as a tool. From here on, we’ll only discuss typical script-based usage.
When users trigger your inference flow, the orchestration layer knits together the necessary tools and LLMs to gather context from your retrieval tools and generate contextually relevant, informed responses. The orchestration layer handles all your API calls and RAG-specific prompting strategies (which we’ll touch on shortly). It also performs validations, like making sure you don’t go over your LLM’s token limit, which could cause the LLM to reject your request because you stuffed too much text into your prompt.
Knowledge Base Retrieval
Vector Store ETL Pipeline
To query your data effectively in LLM-based applications, you need to transform your data into a format accessible to your application. This typically involves setting up a vector store—a database capable of querying based on textual similarity rather than exact matches. Here’s how to set up a Vector Store ETL Pipeline:

Step 1: Aggregate Source Documents
Aggregate all relevant source documents that you want to make available to your application. This may include product documentation, white papers, blog posts, internal records, planning documents, etc.
Step 2: Clean Document Content
Clean the document content to remove any information that shouldn’t be visible to the LLM provider or end users. Remove personally identifiable information (PII), confidential information, and in-development content.
Step 3: Load Document Contents
Load the cleaned document contents into memory using tools like Unstructured, LlamaIndex, or LangChain’s Document loaders. These tools can handle various document types, such as text documents, spreadsheets, web pages, PDFs, Git repos, etc.
Step 4: Split Content into Chunks
Split the content into smaller, manageable chunks that can fit into an LLM prompt while preserving meaning. Use text splitters available in LangChain or LlamaIndex, or develop your own based on the content type.
Step 5: Create Embeddings for Text Chunks
Generate embeddings for the text chunks to store numerical representations of their relative positions and relationships. You can use embedding models like SentenceTransformers or options provided by LangChain and LlamaIndex.
Step 6: Store Embeddings in a Vector Store
Add the embeddings to a vector store such as Pinecone, Weaviate, FAISS, Chroma, etc., where you can query based on similarity.
Querying the Vector Store
Once the vectors are stored, you can query the vector store to find content similar to your query. You can also update or add to your source documents as needed, as most vector stores support updating the store.
Update Strategy
If you expect regular updates to your source documents, consider implementing a document indexing process to only process new or recently updated documents.
Code Implementation
Step 1: Install Required Python Packages
Install necessary Python packages using pip.
!pip install -U -q bitsandbytes transformers peft accelerate datasets scipy matplotlib huggingface_hub
!pip install -U -q langchain langchain-text-splitters qdrant-client sentence-transformers
!pip install e2enetworks
Note
If you are using a GPU notebook provided by E2E Networks, make sure you uninstall the previous version of e2enetworks first.
Step 2: Import Libraries
Import required libraries for the implementation.
import os
import sys
import time
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, pipeline, BitsAndBytesConfig
from qdrant_client import QdrantClient
from qdrant_client.http.models import PointStruct
from e2enetworks.cloud import tir
from langchain_text_splitters import SentenceTransformersTokenTextSplitter
from huggingface_hub import login
Step 3: Login to Hugging Face Account
Log in to your Hugging Face account using your API key.
login(api_key='')
Step 4: Set Up Configuration
If you haven’t created a MyAccount yet, you can do so by visiting the E2E Networks account signup page at E2E Networks.
Next, navigate to TIR and create a new Qdrant. For any questions or assistance, you can consult the E2E Networks documentation on vector database.
Once you’ve completed these steps, you can enter the details of your TIR account and the new Qdrant created below.
# Embedding model provided by E2E Networks
EMBEDDING_MODEL_NAME = "e5-mistral-7b-instruct"
# TIR API credentials
TIR_API_KEY = ""
TIR_ACCESS_TOKEN = ""
TIR_PROJECT_ID =
TIR_TEAM_ID =
# Qdrant credentials
QDRANT_HOST = ""
QDRANT_API_KEY = ""
QDRANT_COLLECTION_NAME = "" # Make sure to create a collection with the given name
Step 5: Load Text-based LLM
Load the desired text-based Large Language Model (LLM) and tokenizer.
model_name = "mistralai/Mistral-7B-Instruct-v0.2"
tokenizer = AutoTokenizer.from_pretrained(
model_name,
add_bos_token=True,
add_eos_token=True,
trust_remote_code=True,
)
model = AutoModelForCausalLM.from_pretrained(
model_name,
device_map="auto",
trust_remote_code=True,
)
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
device_map="auto"
)
# Define the sentence splitter of your choice
text_splitter = SentenceTransformersTokenTextSplitter()
Step 6: Connect to Qdrant and TIR
Connect to the Qdrant client and the TIR platform by E2E Networks.
qdrant_client = QdrantClient(host=QDRANT_HOST, port=6333, api_key=QDRANT_API_KEY)
tir.init(api_key=TIR_API_KEY, access_token=TIR_ACCESS_TOKEN)
tir_client = tir.ModelAPIClient(project=TIR_PROJECT_ID, team=TIR_TEAM_ID)
Step 7: Define Functions for Vector Operations
Define functions for vector operations such as getting vectors, inserting vectors, and creating vector embeddings.
def get_vector(tir_client: tir.ModelAPIClient, text: str):
# Function to get vector representation of text
data = {"prompt": text}
response = tir_client.infer(model_name=EMBEDDING_MODEL_NAME, data=data)
vector = response.outputs[0].data
return vector
def insert_vector(client: QdrantClient, vector: list, text: str, vector_id: int, chunk_id: int):
# Function to insert vectors into Qdrant
points = []
new_id = int(time.time())
point = PointStruct(
vector=vector,
id=new_id,
payload={"data": text, "chunk_id": chunk_id}
)
points.append(point)
res = client.upsert(collection_name=QDRANT_COLLECTION_NAME, wait=False, points=points)
def create_vector():
# Function to create vector embeddings for data
vector_id = 1
text_files_dir = "path_to_folder" # create a folder containing all the text files with relevant data
for filename in os.listdir(text_files_dir):
filepath = os.path.join(text_files_dir, filename)
with open(filepath, 'r', encoding='utf-8') as file:
text = file.read()
if not text:
continue
chunks = text_splitter.split_text(text)
chunk_id = 0
for chunk in chunks:
vector = get_vector(tir_client, chunk)
if not vector:
continue
insert_vector(qdrant_client, vector, chunk, vector_id, chunk_id)
vector_id += 1
chunk_id += 1
# Create vector embeddings for your data
create_vector()
Step 8: Define Function for Chatting with E2E
Define a function to perform vector search in Qdrant and pass the results as context to the Text LLM.
def chat_with_E2E(prompt):
# Encode prompt to get its vector representation
vector = get_vector(tir_client, prompt)
# Perform vector search in Qdrant
search_result = qdrant_client.search(
collection_name=QDRANT_COLLECTION_NAME,
query_vector=vector,
limit=2, # gives you top 2 vectors based on the search score
)
# Extract context from search results
payloads = [hit.payload for hit in search_result]
context = ' '.join(hit['data'] for hit in payloads)
# Pass context to the text prompt using <SYS> tag
text = f"""
<INST> {prompt}
Context: {context}
<SYS>Generate an answer relevant to the context provided only.
Start the conversation with "Welcome to E2E Networks Limited."</SYS></INST>
"""
# Generate response based on the text prompt
sequences = pipe(
text,
do_sample=True,
max_new_tokens=1000,
temperature=0.7,
top_k=50,
top_p=0.95,
num_return_sequences=1,
return_full_text=False,
)
print(sequences[0]['generated_text'])
Step 9: Chat with E2E
Interact with the E2E Networks chatbot by providing a prompt.
prompt = "User can enter their prompt here"
chat_with_E2E(prompt)
Preview of responses given by the Model
For prompts relevant to data
prompt = "How to finetune Mistral-7B? "
chat_with_E2E(prompt)
prompt = "What is a notebook in TIR? "
chat_with_E2E(prompt)

For promts not relevant to data
prompt = "What is the purpose of Life? "
chat_with_E2E(prompt)

prompt = "What is the current unemployment rate in the United States? "
chat_with_E2E(prompt)

Fine-Tuning vs. RAG
Fine-tuning involves training a model on additional data to improve performance on specific tasks, while RAG augments LLMs with external knowledge for contextually relevant responses.
RAG addresses the issue of forgetting by allowing easy addition, update, and deletion of knowledge base contents.
Combining fine-tuning with RAG creates specialized LLM-powered applications capable of leveraging contextual knowledge while being optimized for specific tasks or domains.
Conclusion
Retrieval Augmented Generation (RAG) is a powerful technique for enhancing the capabilities of Large Language Models (LLMs) like Mistral. By combining information retrieval with text generation, RAG enables LLMs to generate contextually relevant responses based on up-to-date information from external knowledge sources. Implementing RAG involves setting up document loaders, vectorizing text data, prompting the LLM with relevant context, and post-processing the response to ensure quality and compliance with token limits.
With RAG, LLM-powered applications can provide more accurate and informed responses, improving user experiences and information accuracy across various domains.
By following the steps outlined in this guide, developers can integrate RAG into their applications to leverage the full potential of LLMs.