Model Endpoints
TIR provides two methods for deploying containers that serve model API endpoints for AI inference services:
Deploy Using Pre-built Containers (Provided by TIR)
Before launching a service with TIR’s pre-built containers, you need to create a TIR Model and upload the necessary model files. These containers are configured to automatically download model files from an EOS (E2E Object Storage) Bucket and start the API server. Once the endpoint is ready, you can make synchronous requests to the endpoint for inference. Learn more in this tutorial .
Deploy using your own container
You can launch an inference service using your own Docker image, either public or private. Once the endpoint is ready, you can make synchronous requests for inference. Optionally, you can attach a TIR model to automate the download of model files from an EOS bucket to the container. Learn more in this tutorial .
Create Model Endpoints
- To create a model endpoint:
- Navigate to Inference: Click on “Model Endpoints.”
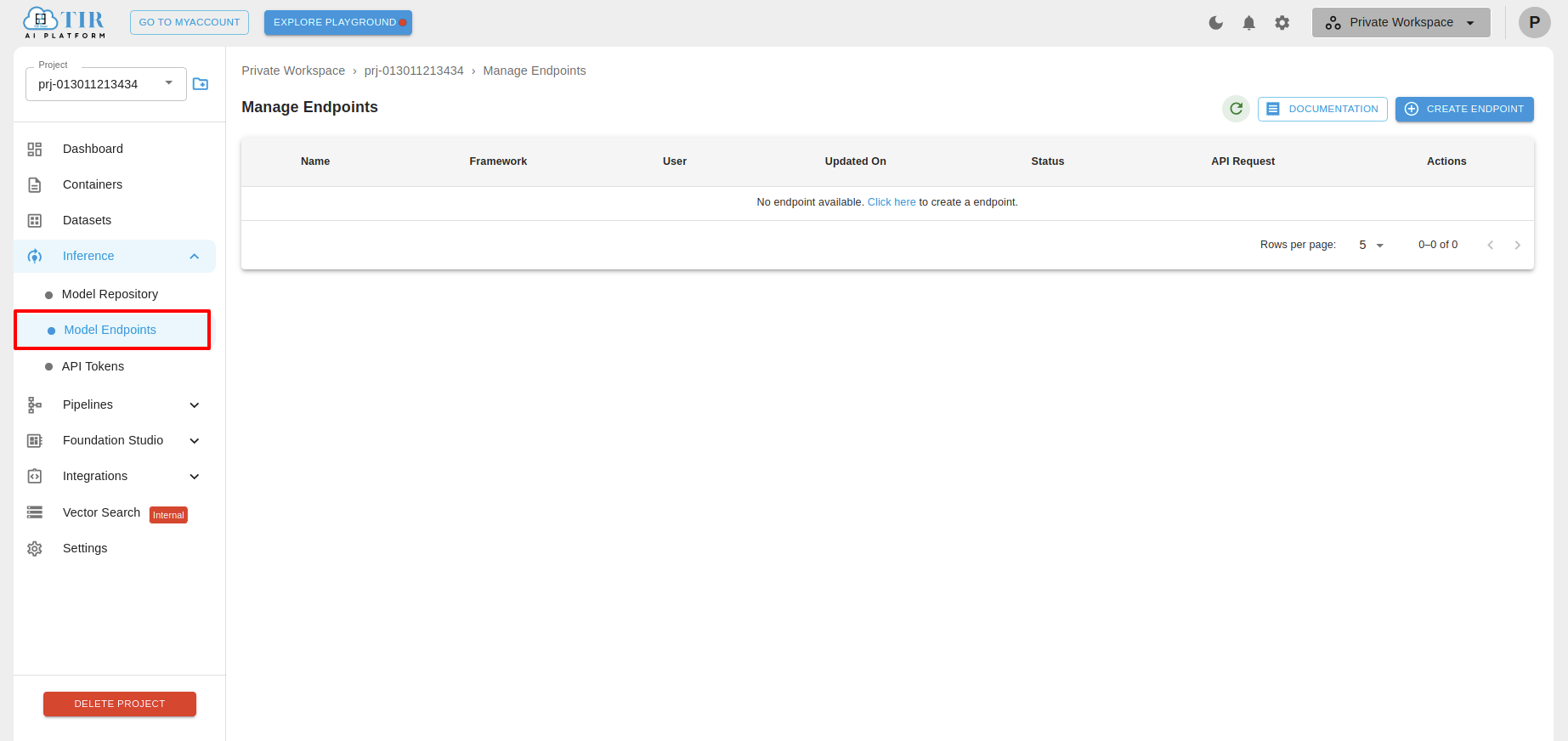
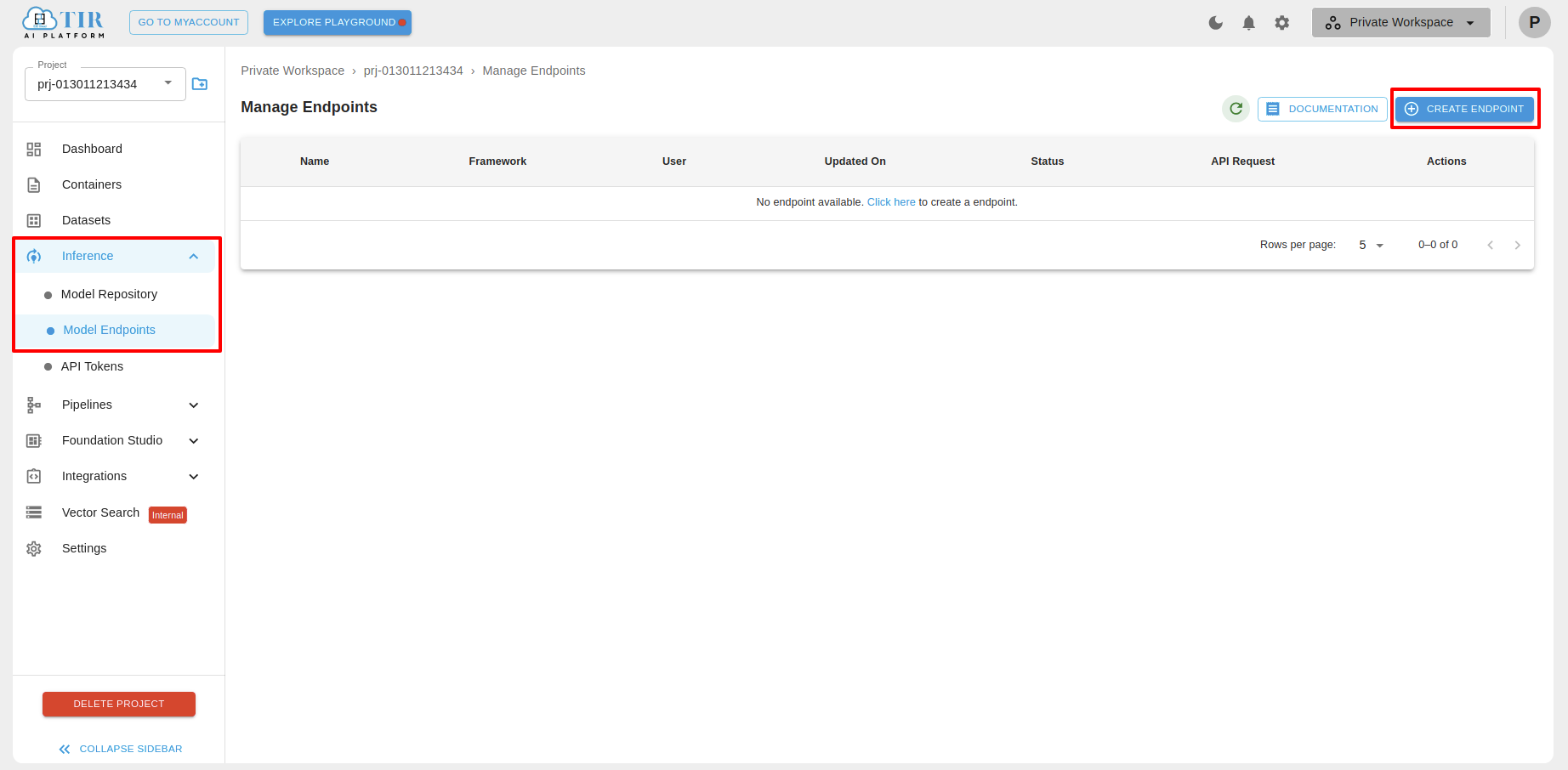
- Create an Endpoint: Click on the “CREATE ENDPOINT” button.
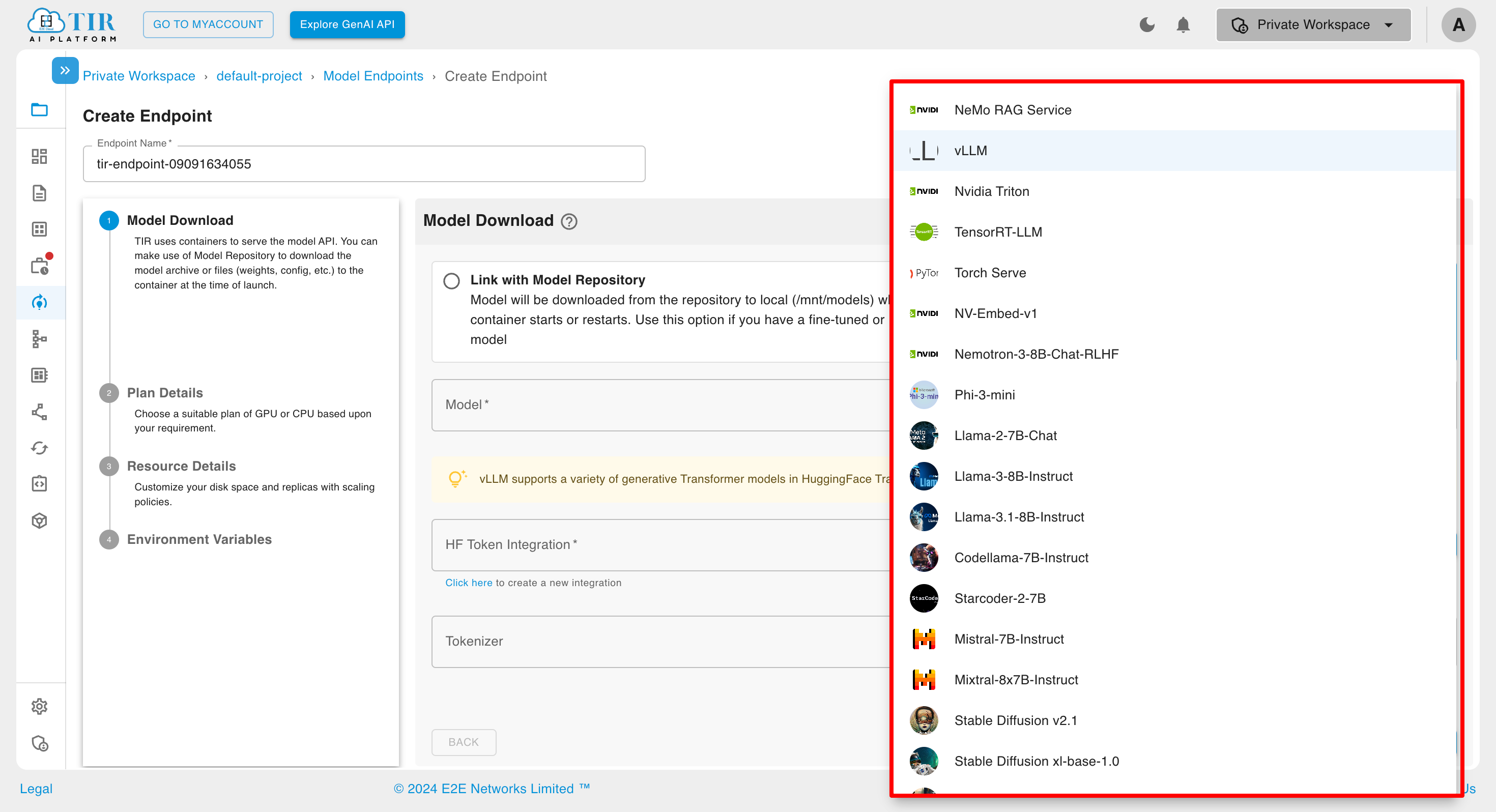
Choose a Framework:

You can use the search bar to explore the available frameworks.

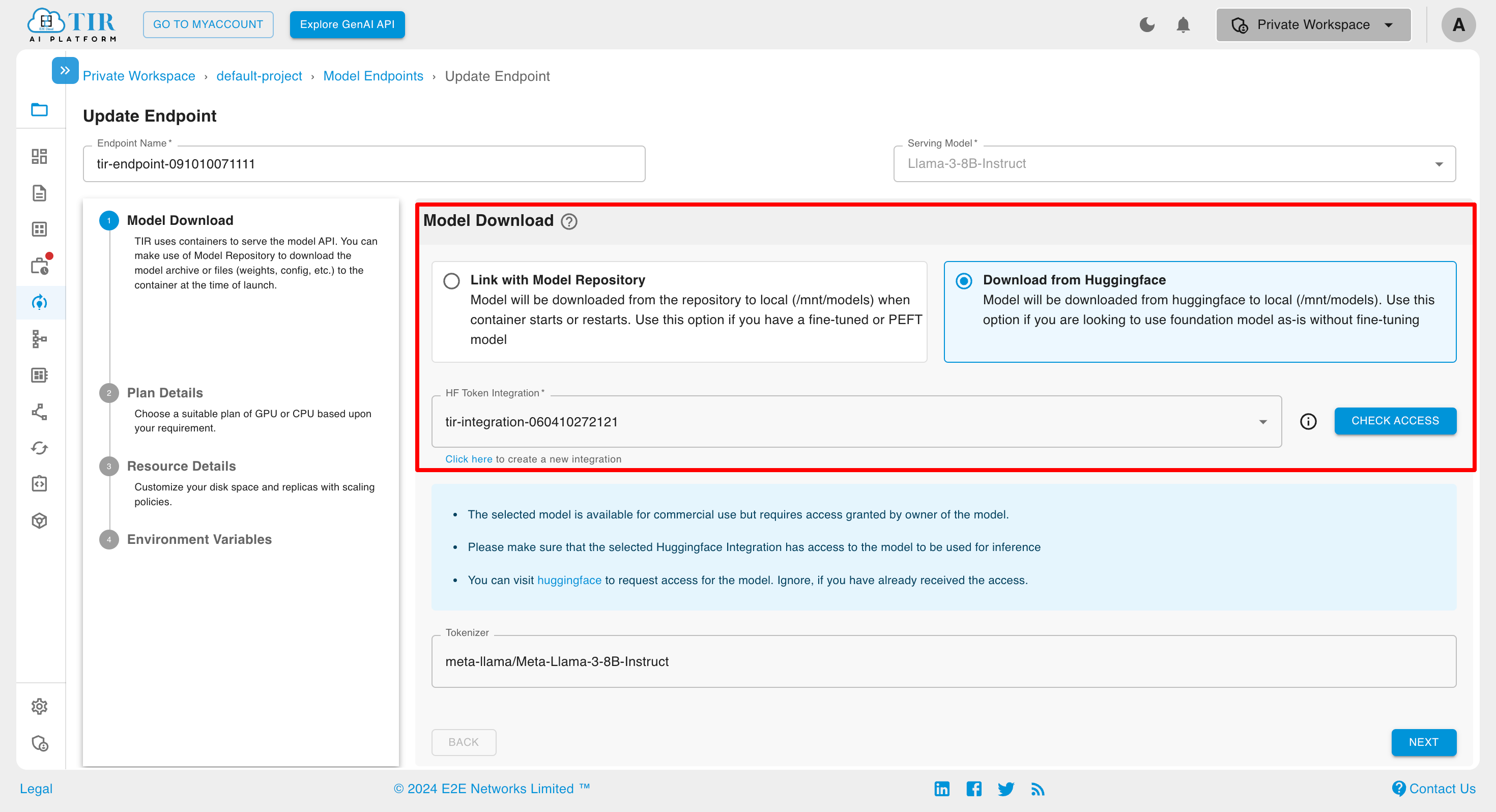
Click on Link with Model Repository and select from Model Repository
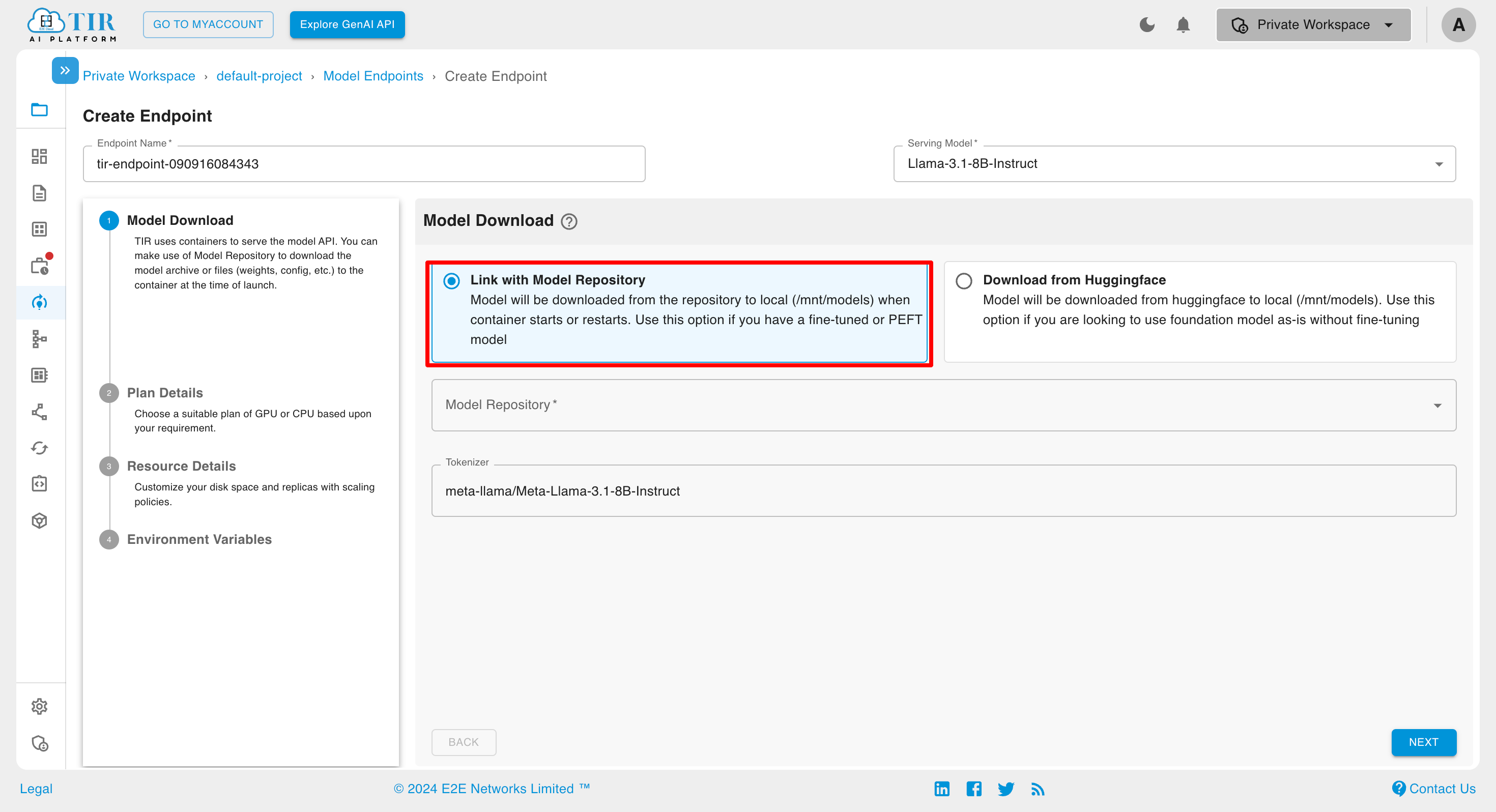
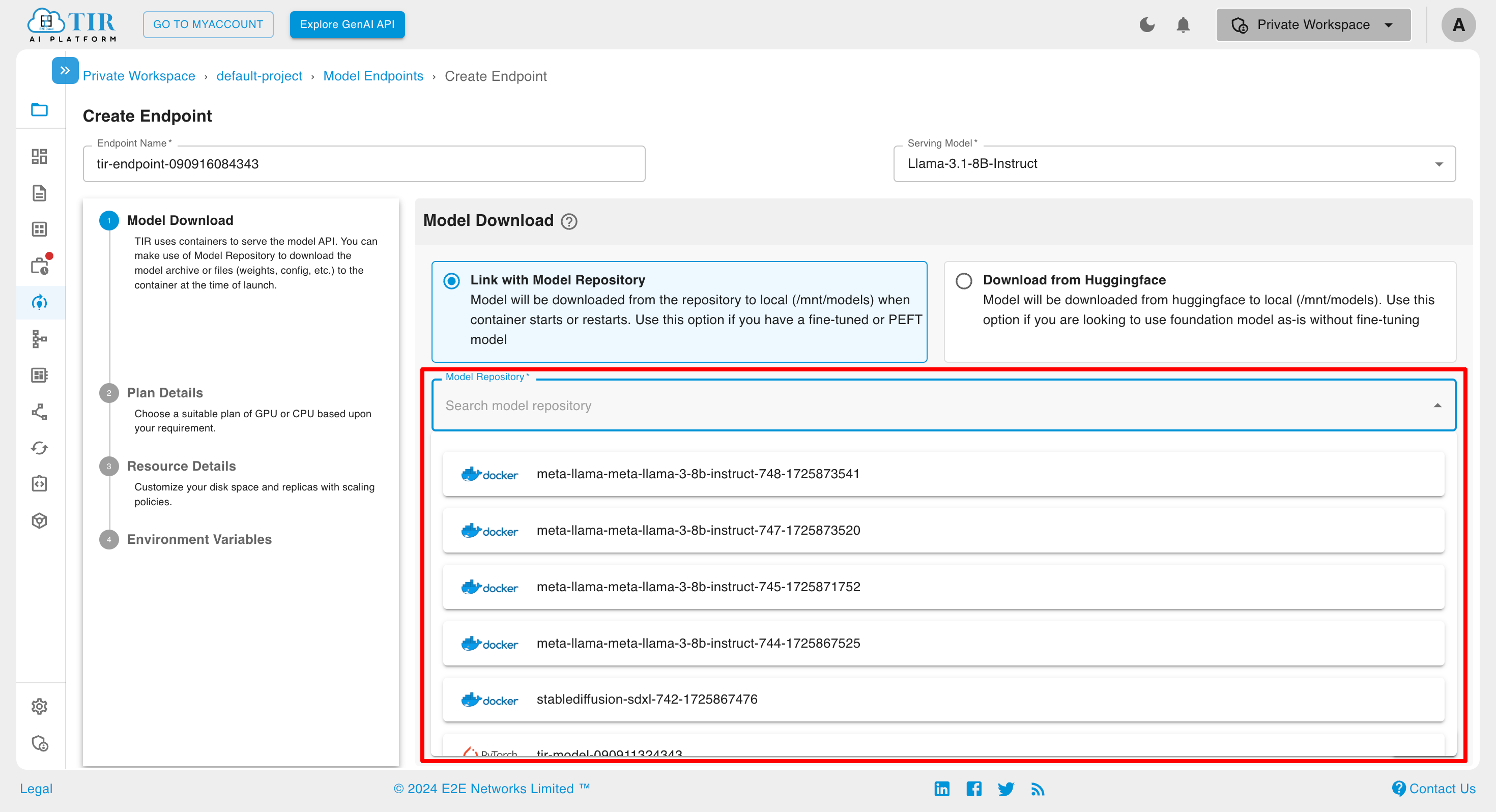
Click on Download from Huggingface and select token from HF Token Integration
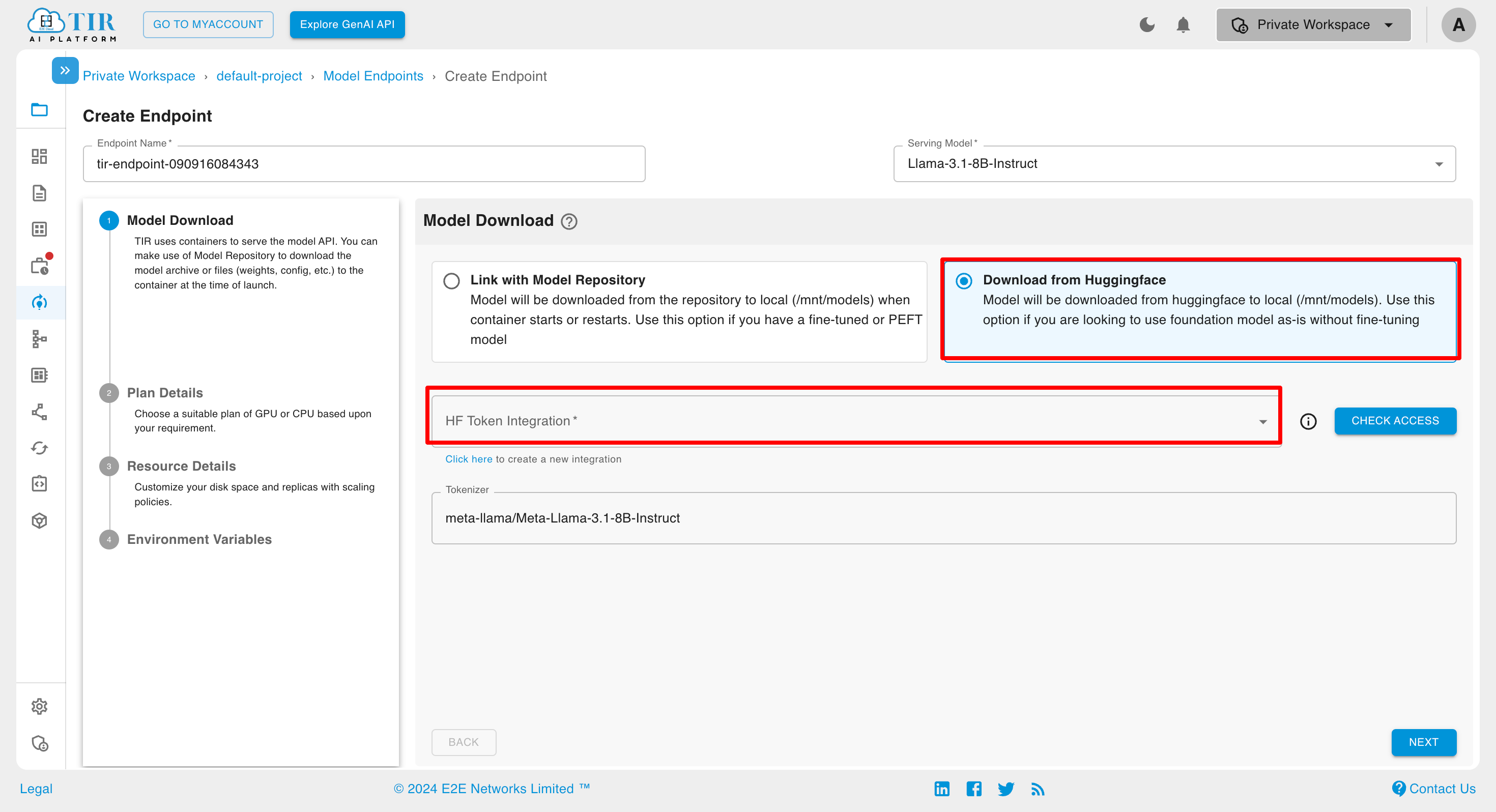
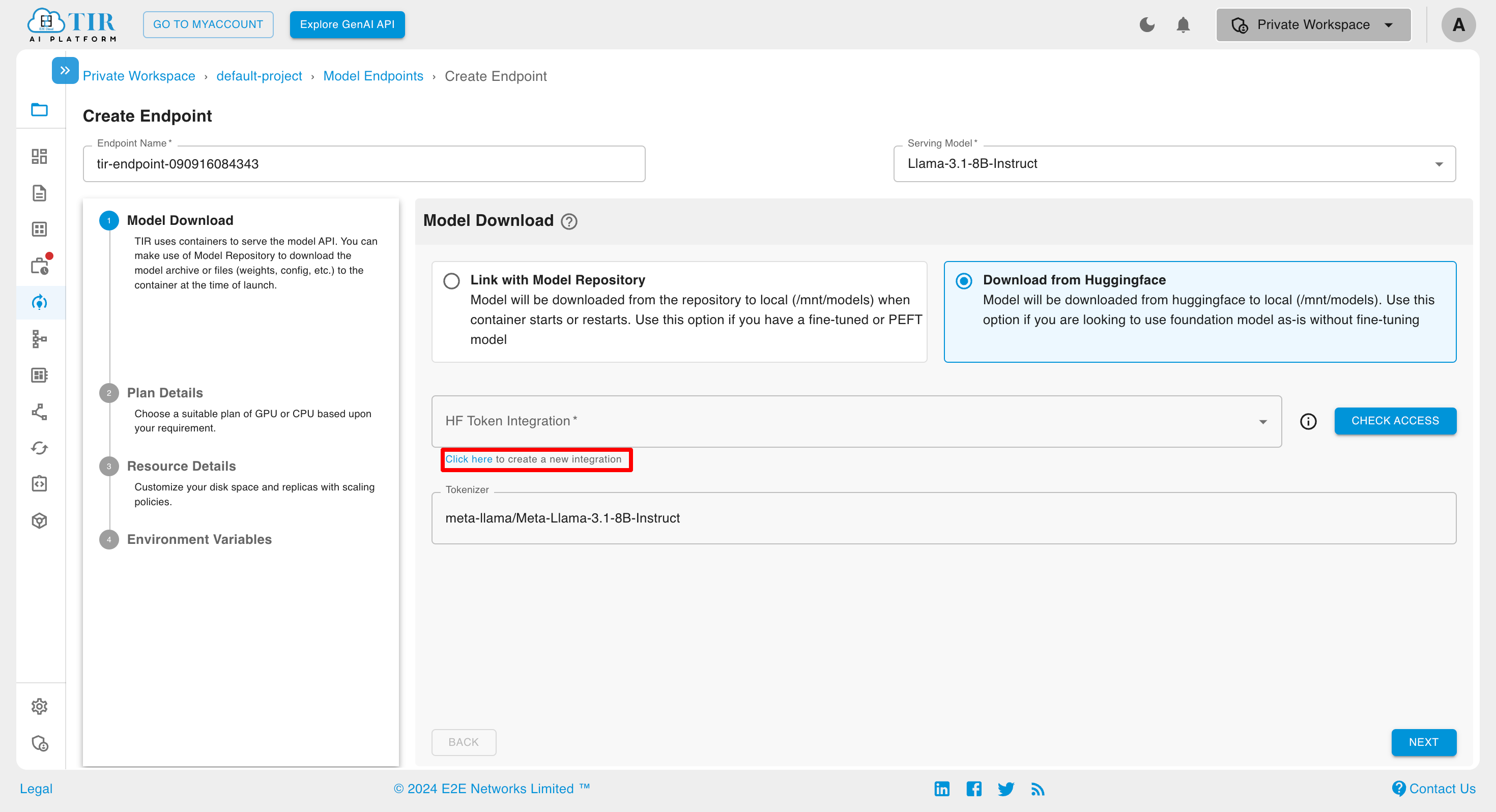
In case any HF Token is not integrated, then click on Click Here to create a new Integration
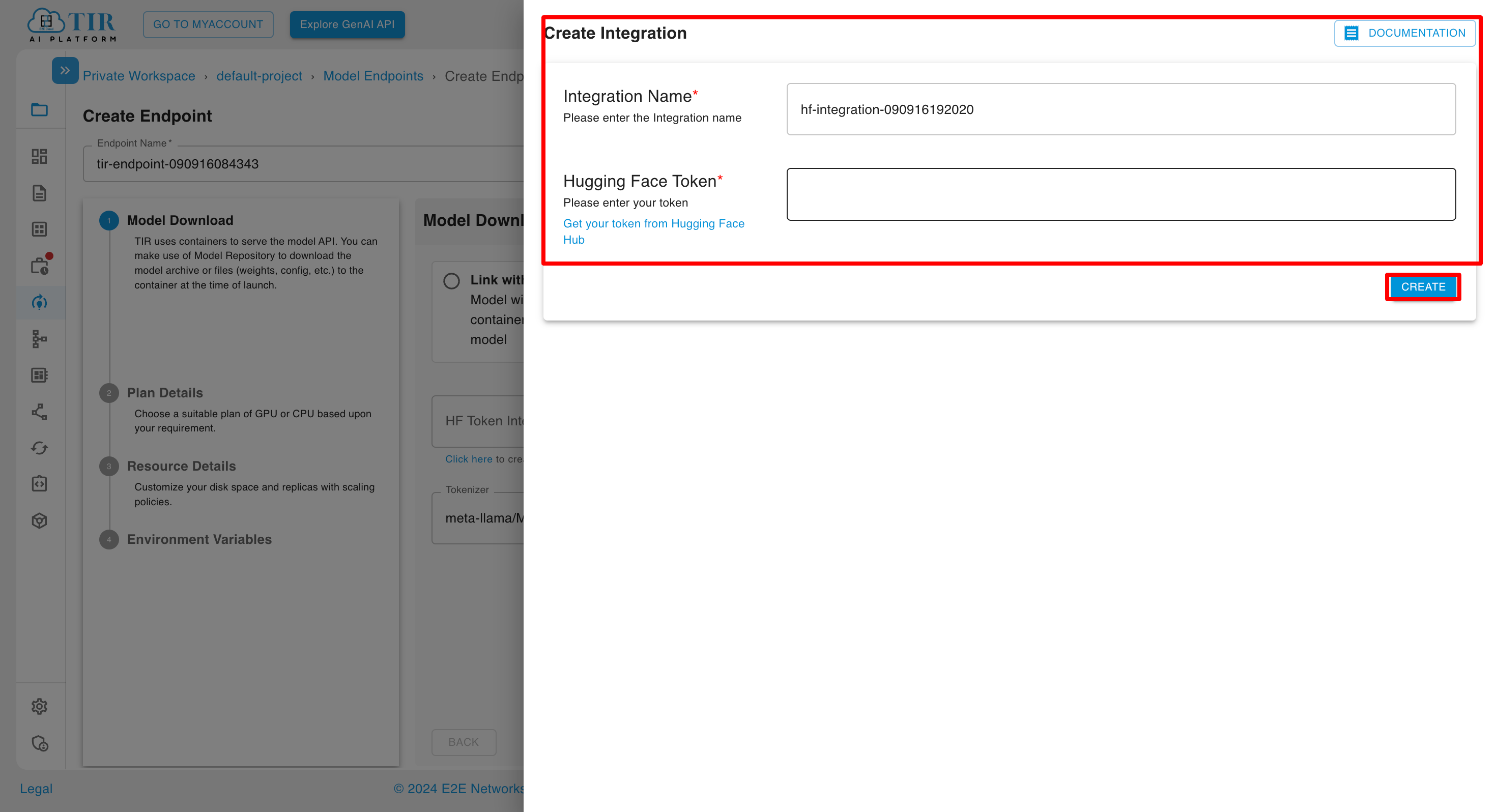
Add Integration Name and Hugging Face Token and then click on create
Plan Details
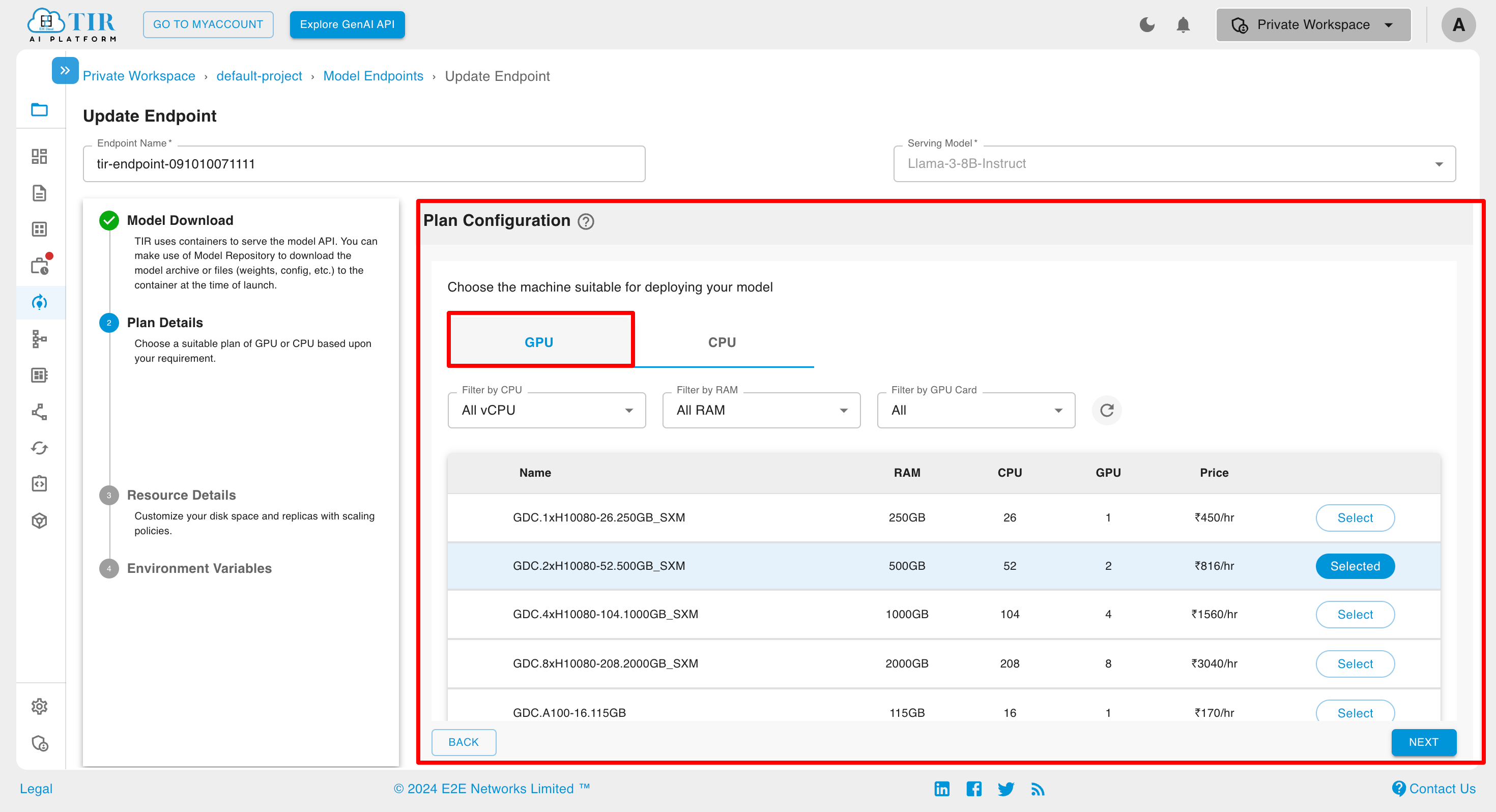
Machine
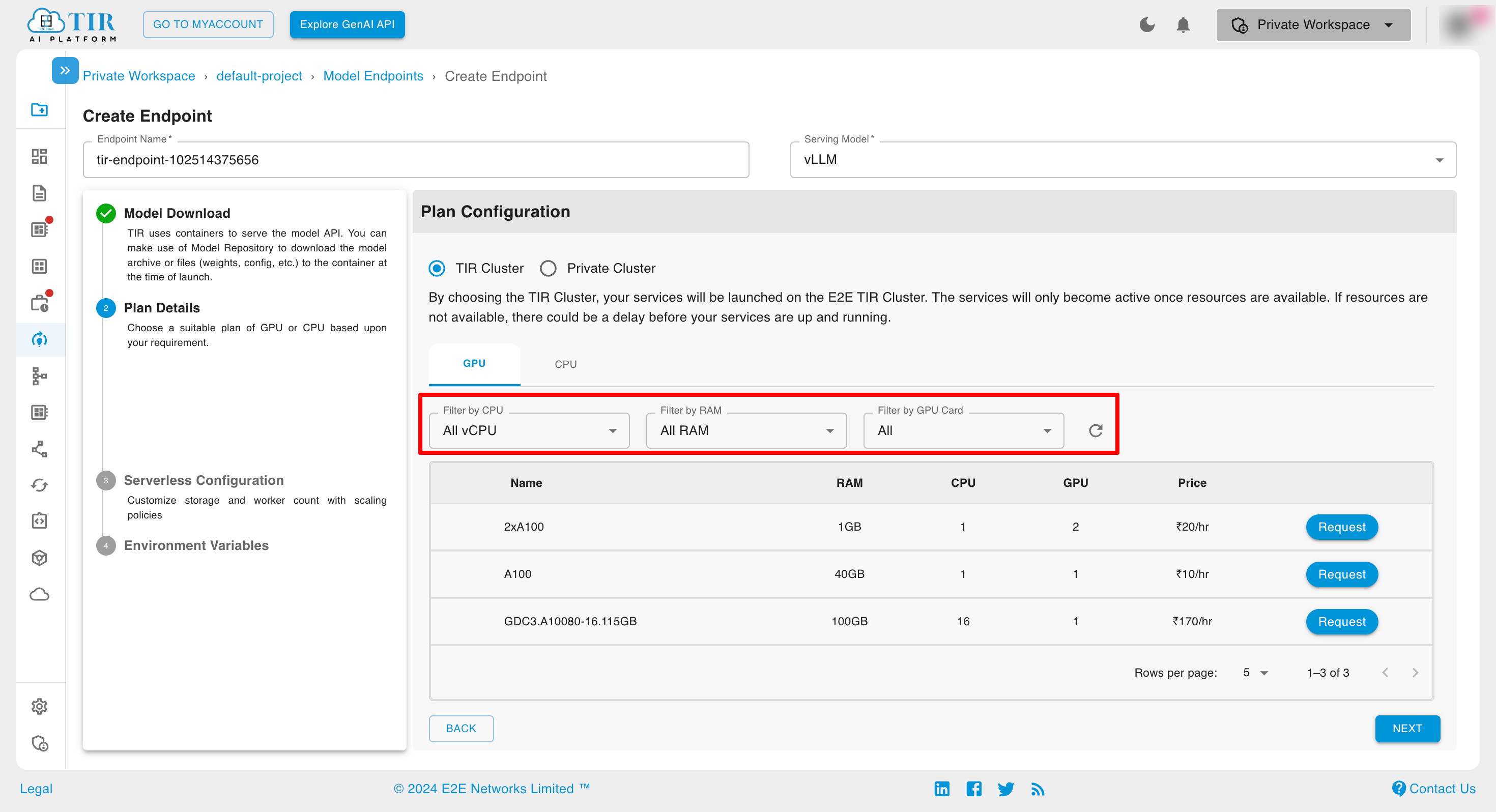
You have the option to select from TIR Cluster & Private Cluster. After you select the TIR Cluster, you can select a machine type either GPU or CPU. While selecting the plan , Here you can select the plan of the Inference from Committed or Hourly Billed
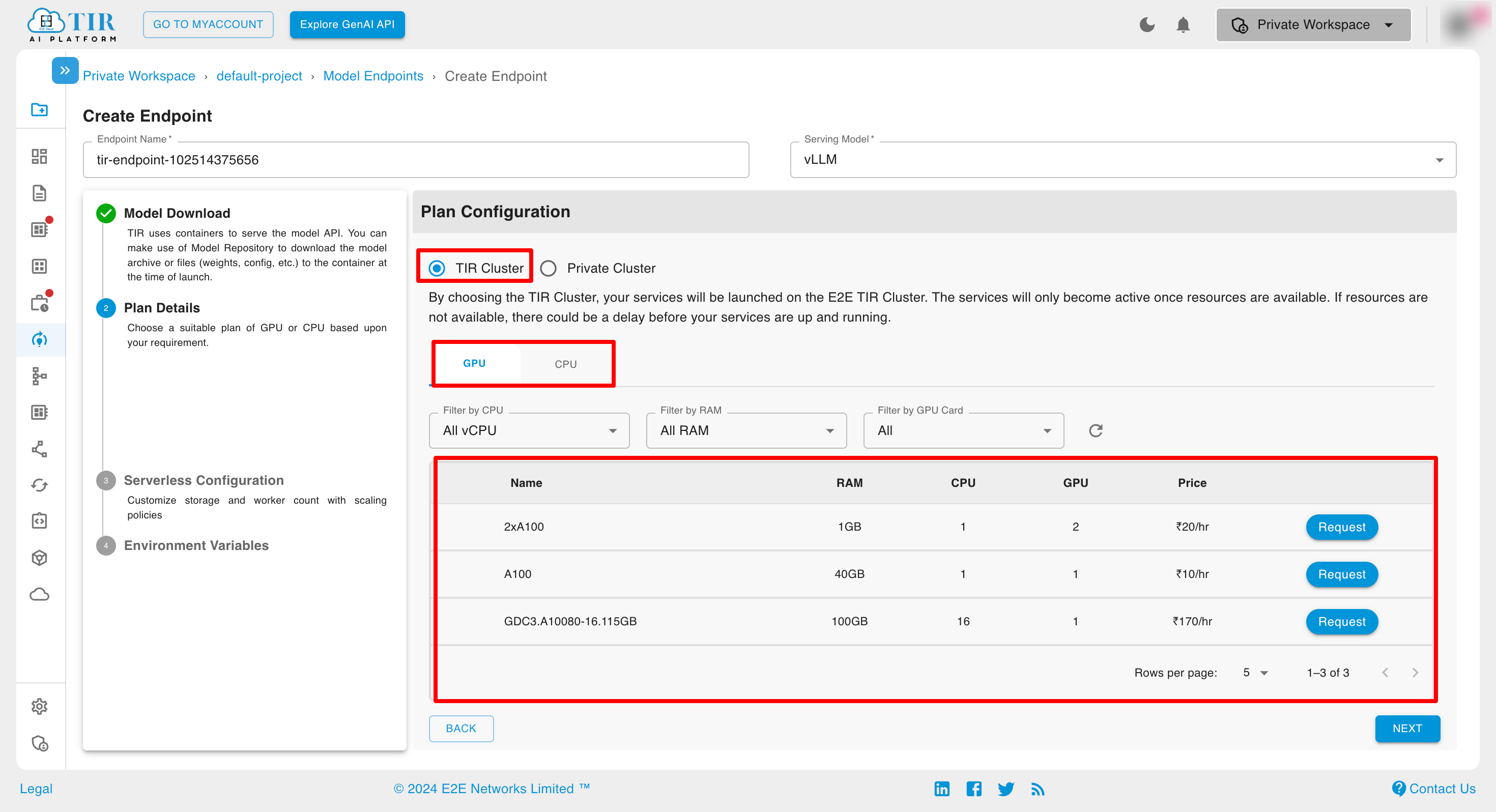
You can apply filters to the available machines to refine your search results.
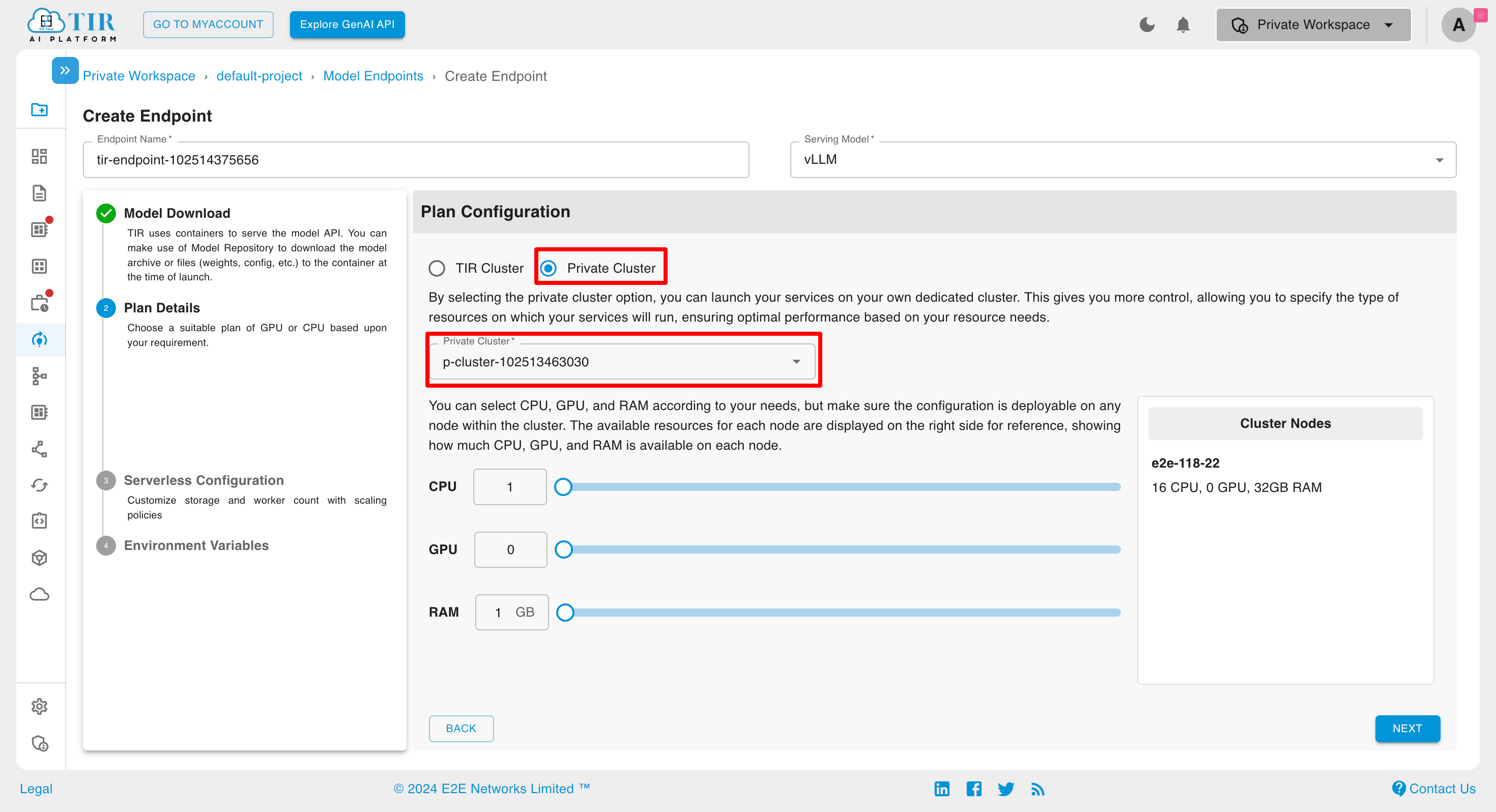
When selecting a Private Cluster, you can either choose from the available options or create a new one. For the chosen Private Cluster, you can specify the quantity of vCPUs, RAM, and GPU.
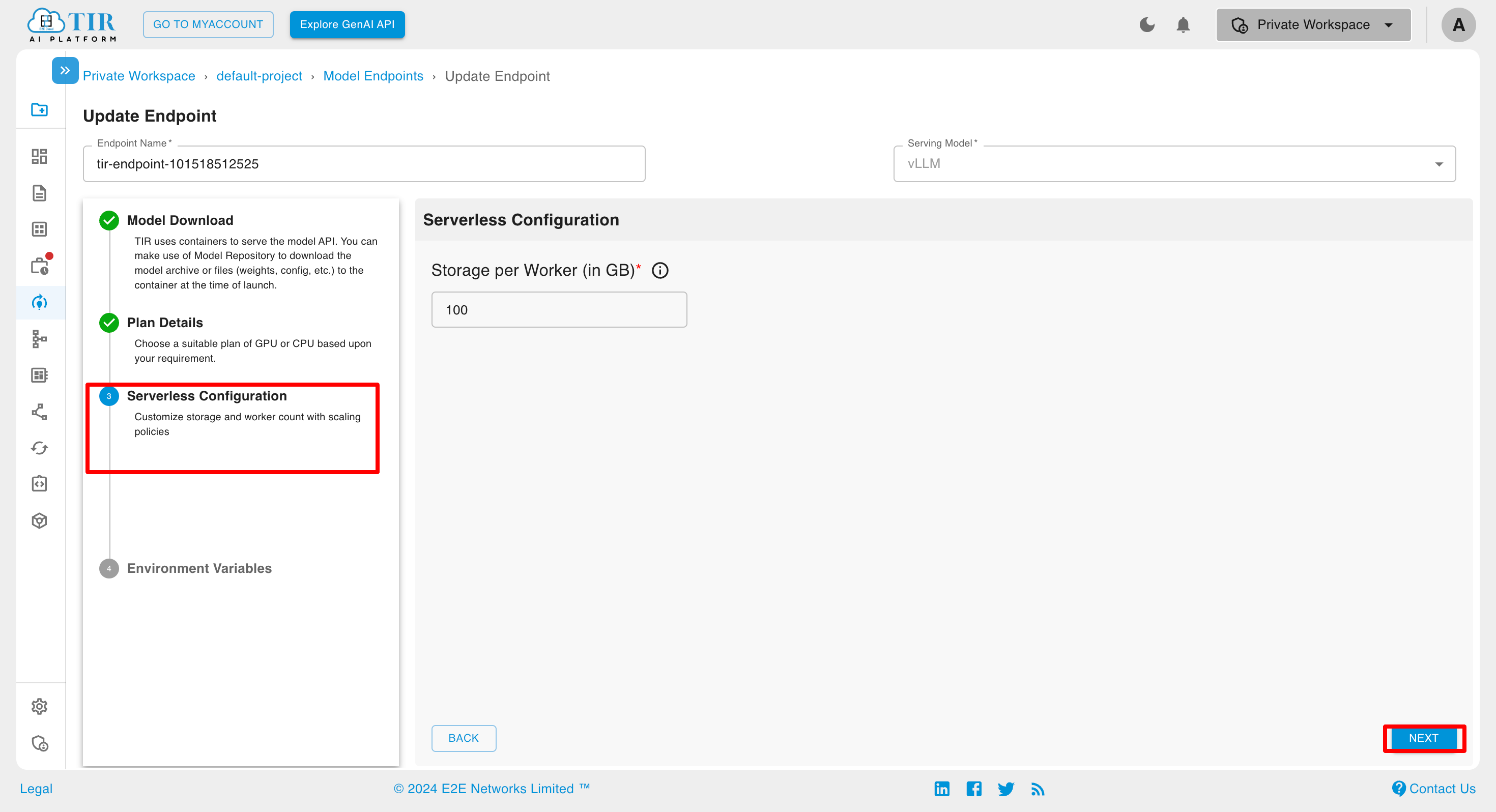
Serverless Configuration
For Hourly Billed Inference, it’s also possible to set the Active Workers to 0.You can set the number of Active Workers to any value from 0 up to the max workers. When there are no incoming requests, the number of active workers automatically reduces to 0, ensuring that no billing is incurred for that period.
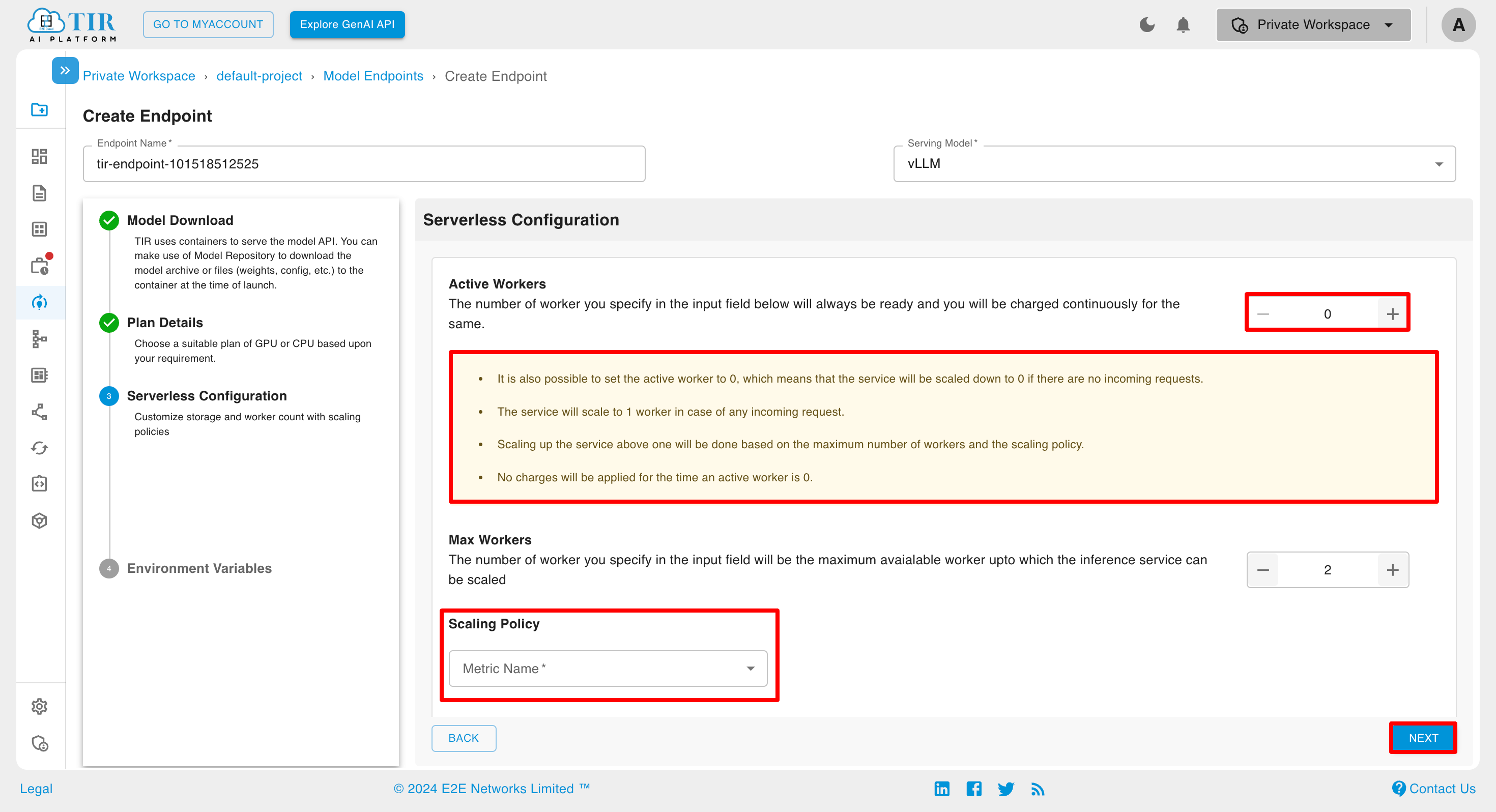
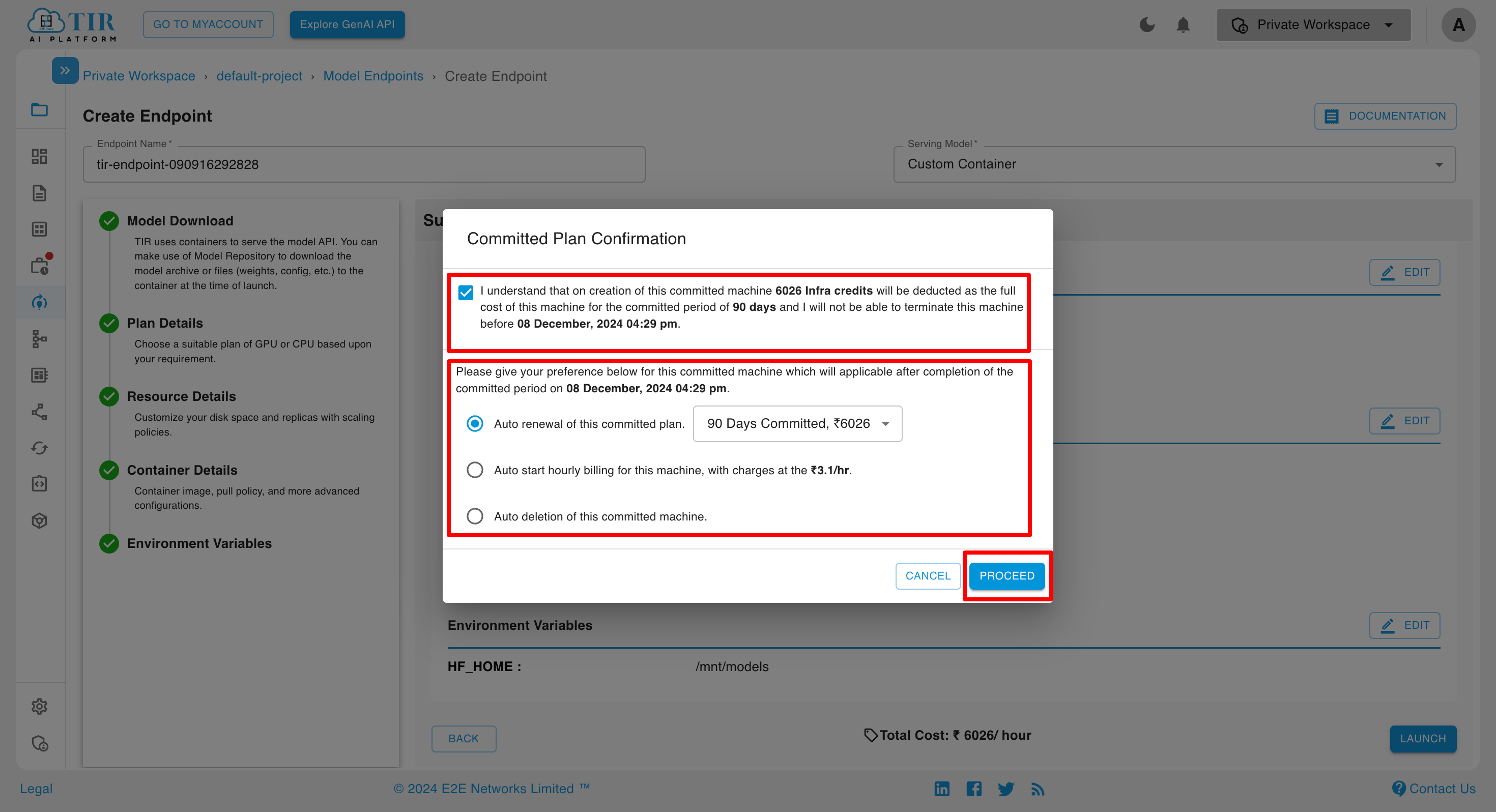
For Committed Inference, the Active Workers cannot be set to 0, and the number of active workers must always remain greater than 0, ensuring committed nature of Inference.You can set the number of Active Workers to any value from 1 up to the Max workers.
Note
All additional inferences, which are added automatically due to the autoscaling feature, will be charged at an hourly billing rate. Similarly, if the Active Worker count is increased from a serverless configuration after the inference is created, those additional inferences will also be billed at the hourly rate.
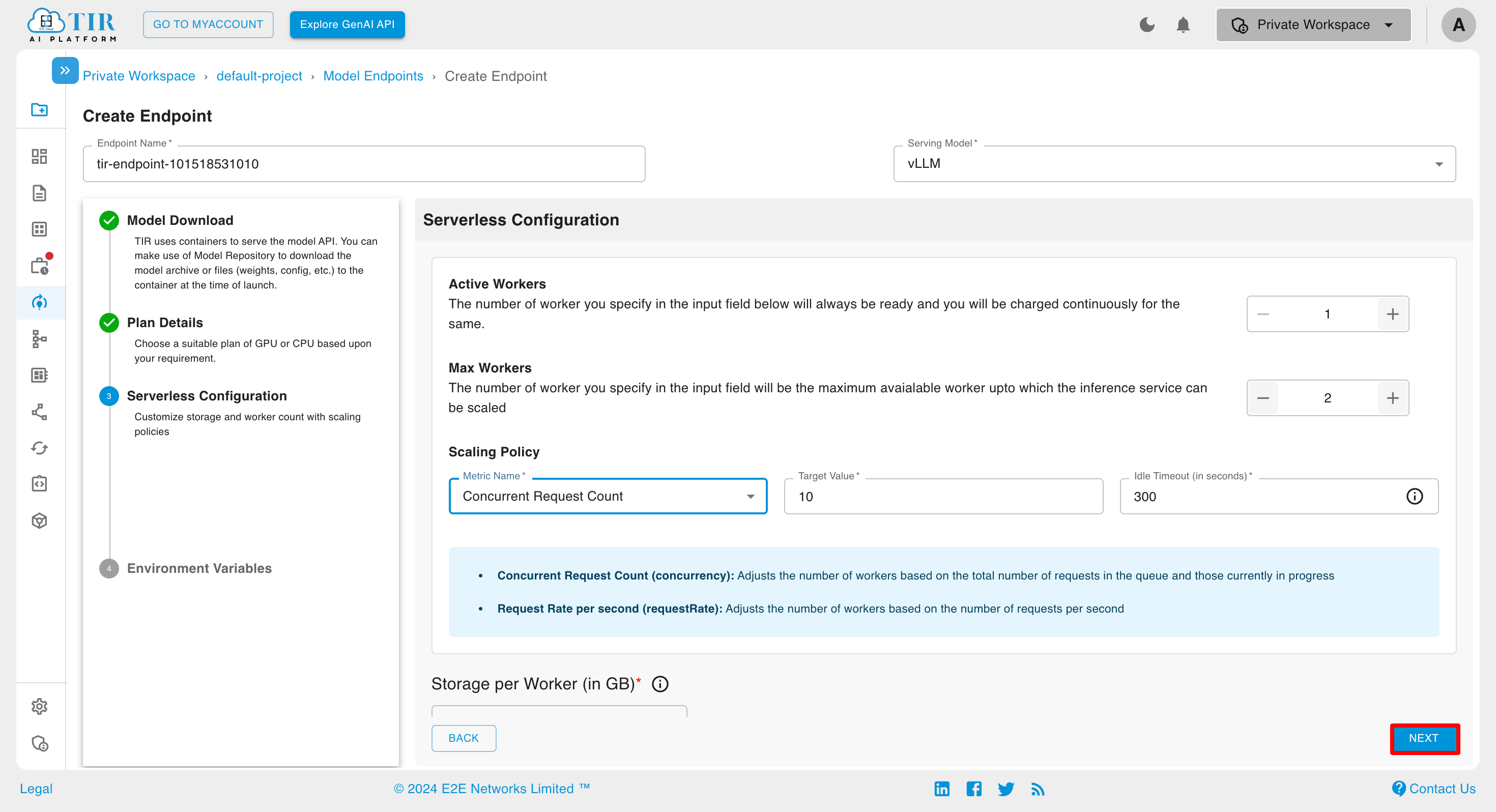
Environment Variables
Add Variable
You can add variable by clicking ADD VARIABLE button.
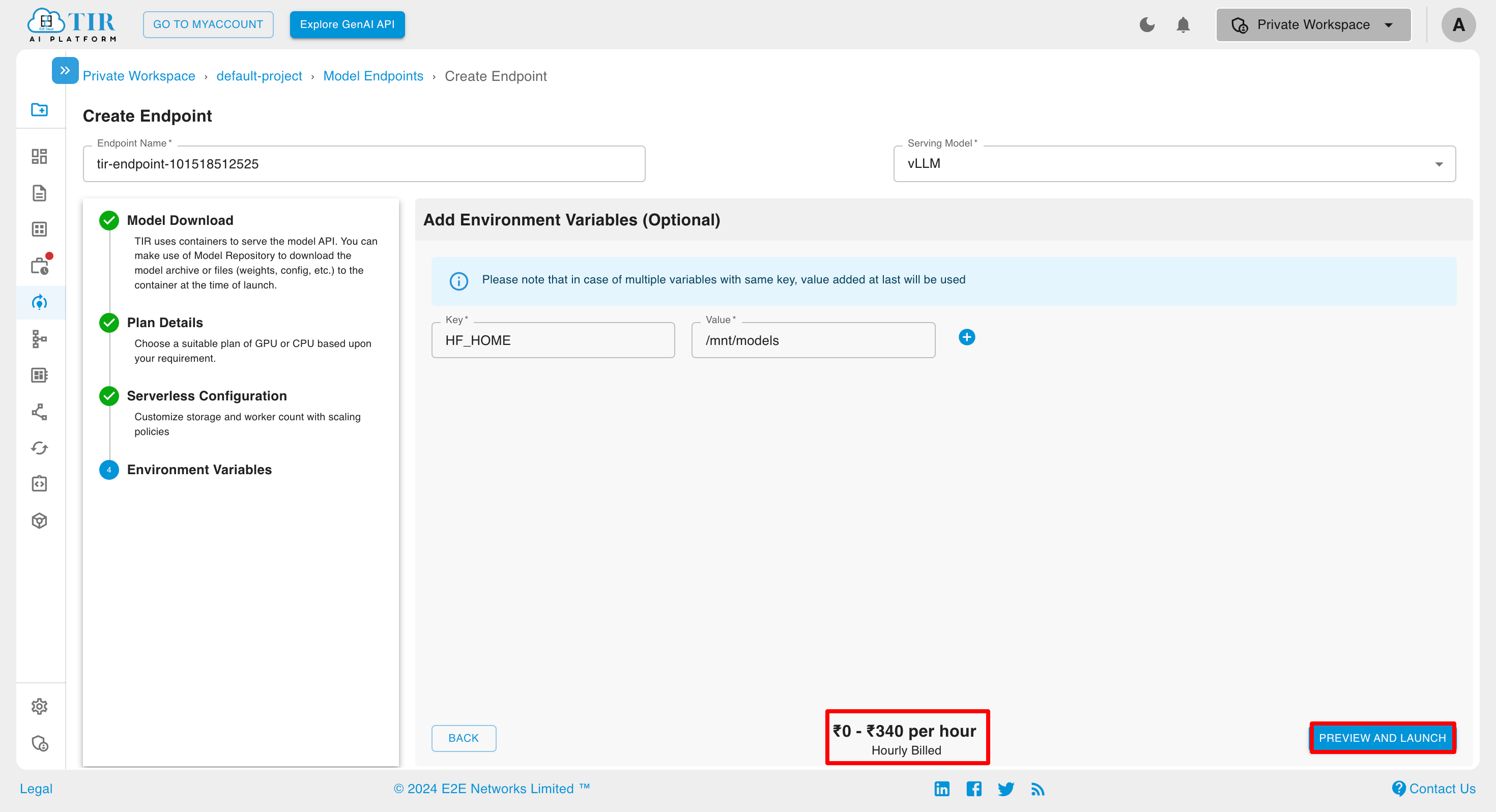
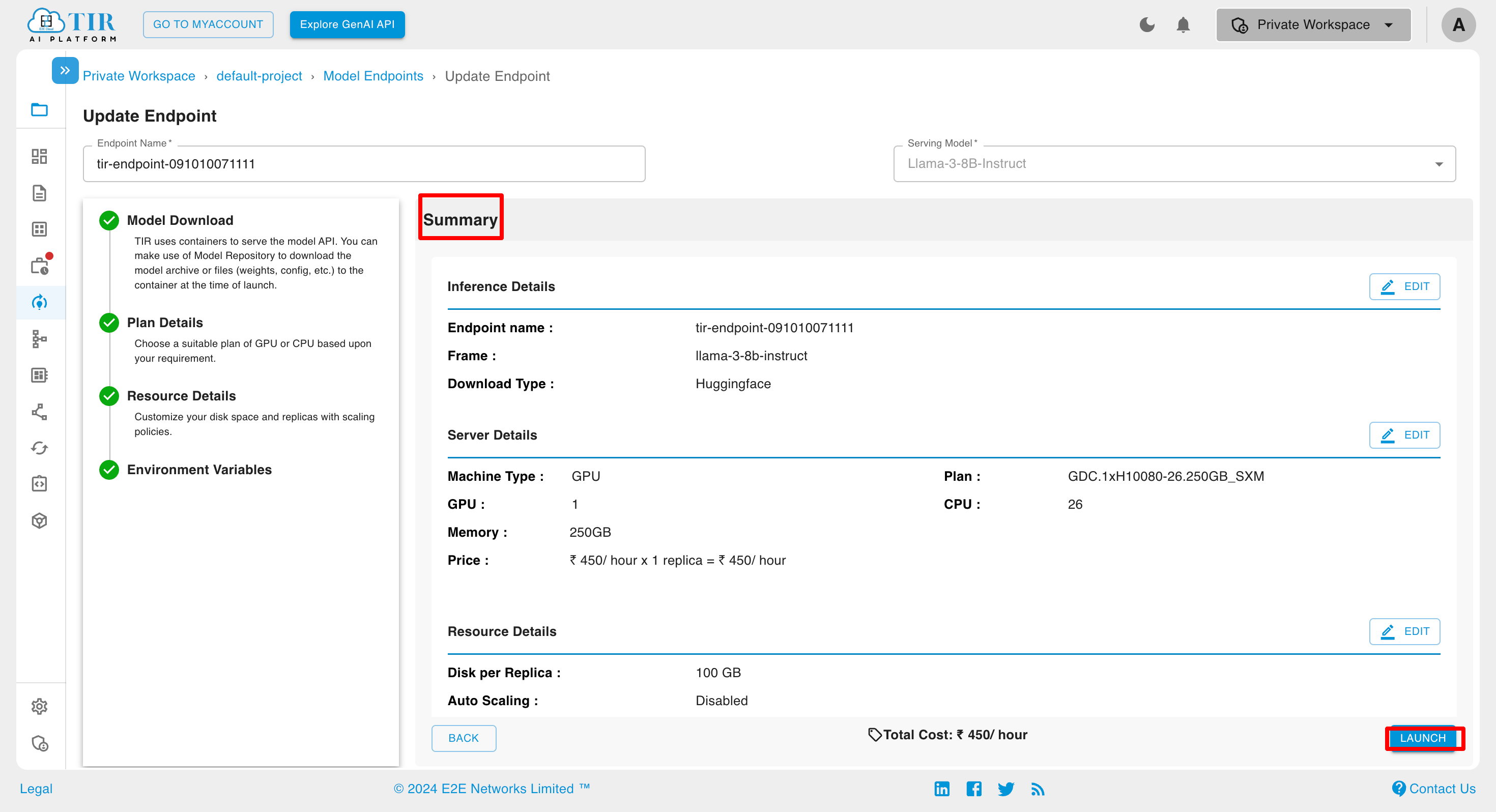
Summary
You can view the endpoint summary on the summary page, and if needed, modify any section of the inference creation process by clicking the edit button.
In case of the Hourly Billed Inference with Active Worker is not equal to Max Worker, the billing is shown as:
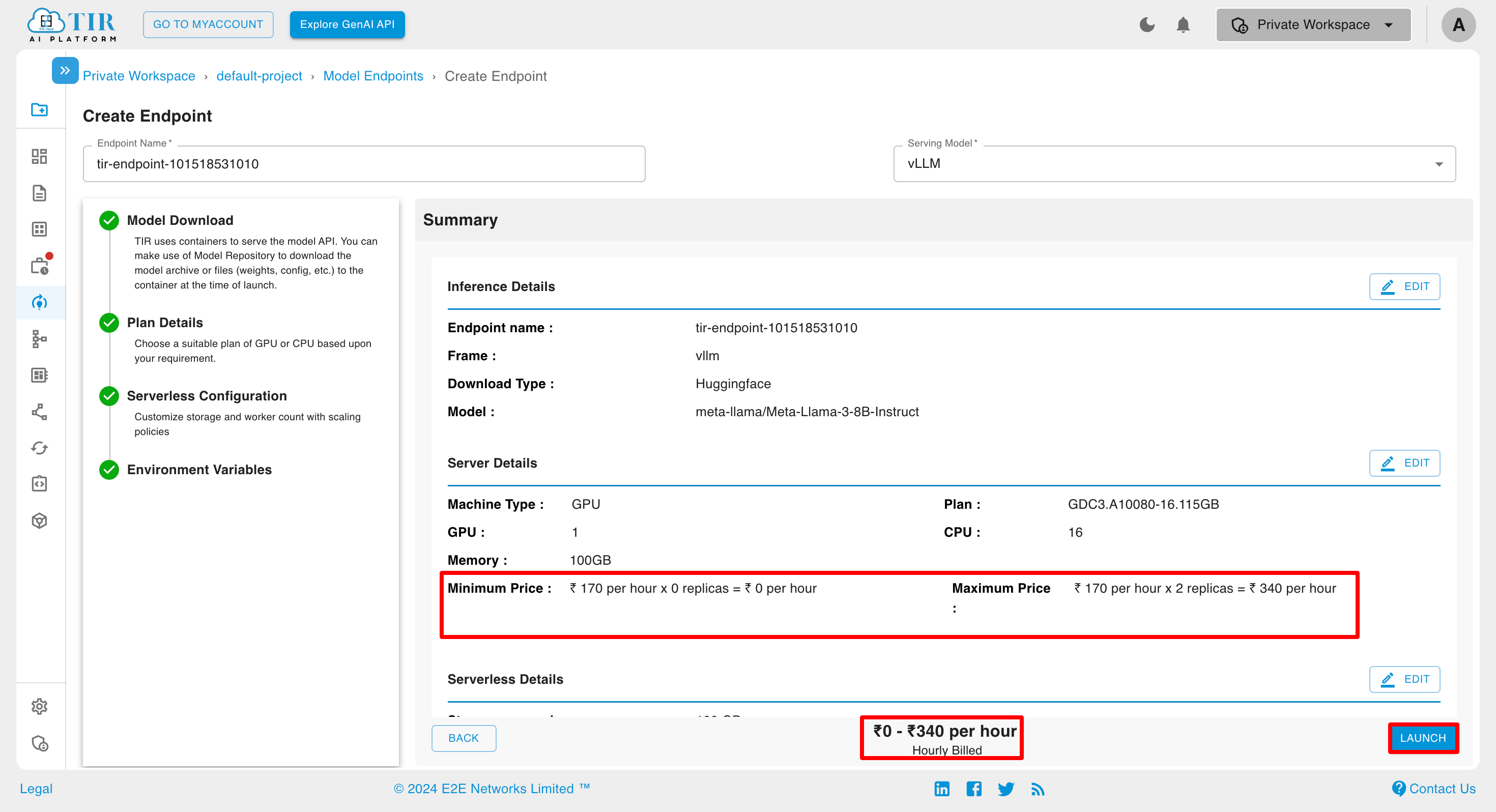
In case of the Committed Inference with Active Worker is not equal to Max Worker, the billing is shown as:
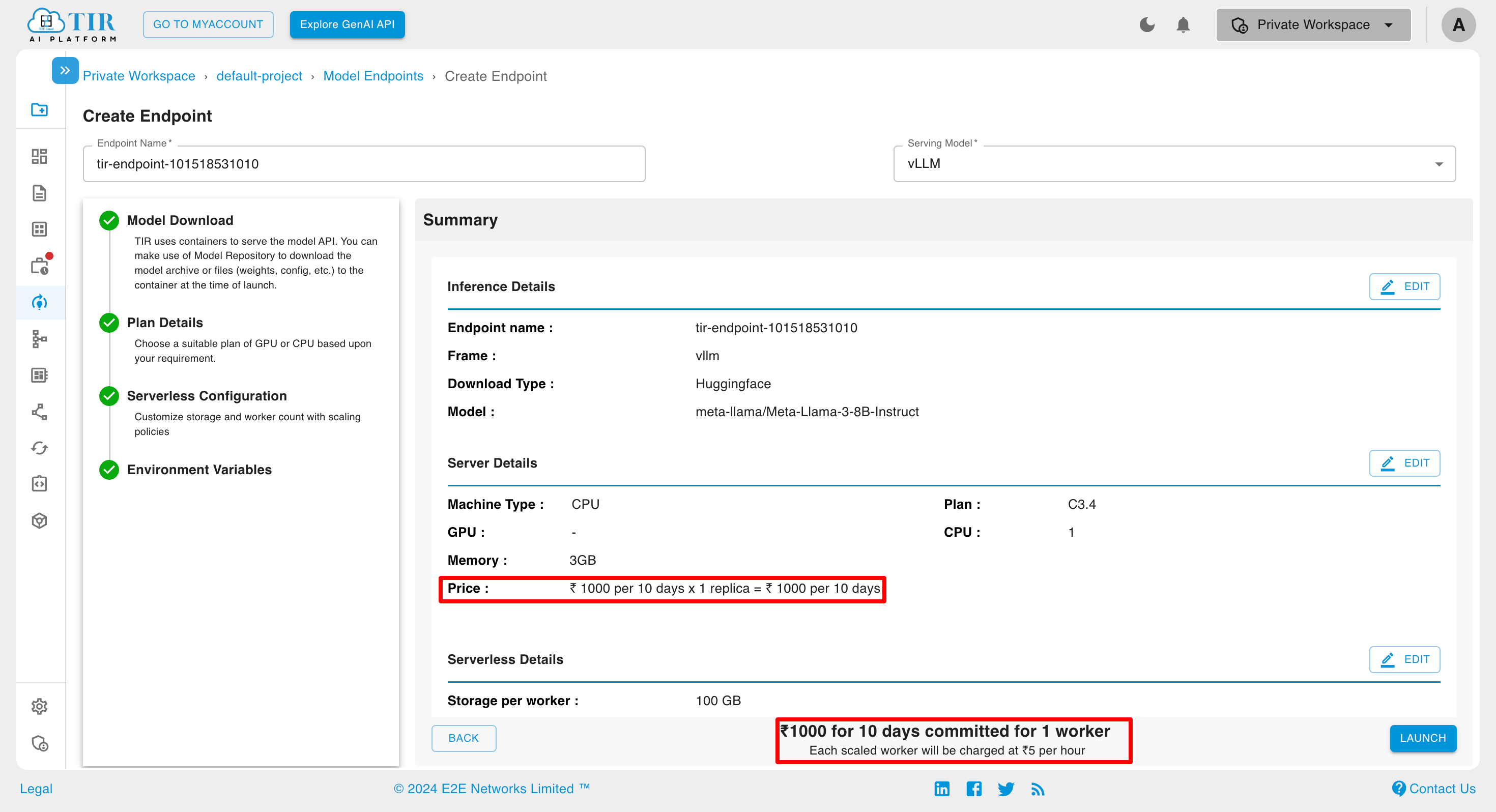
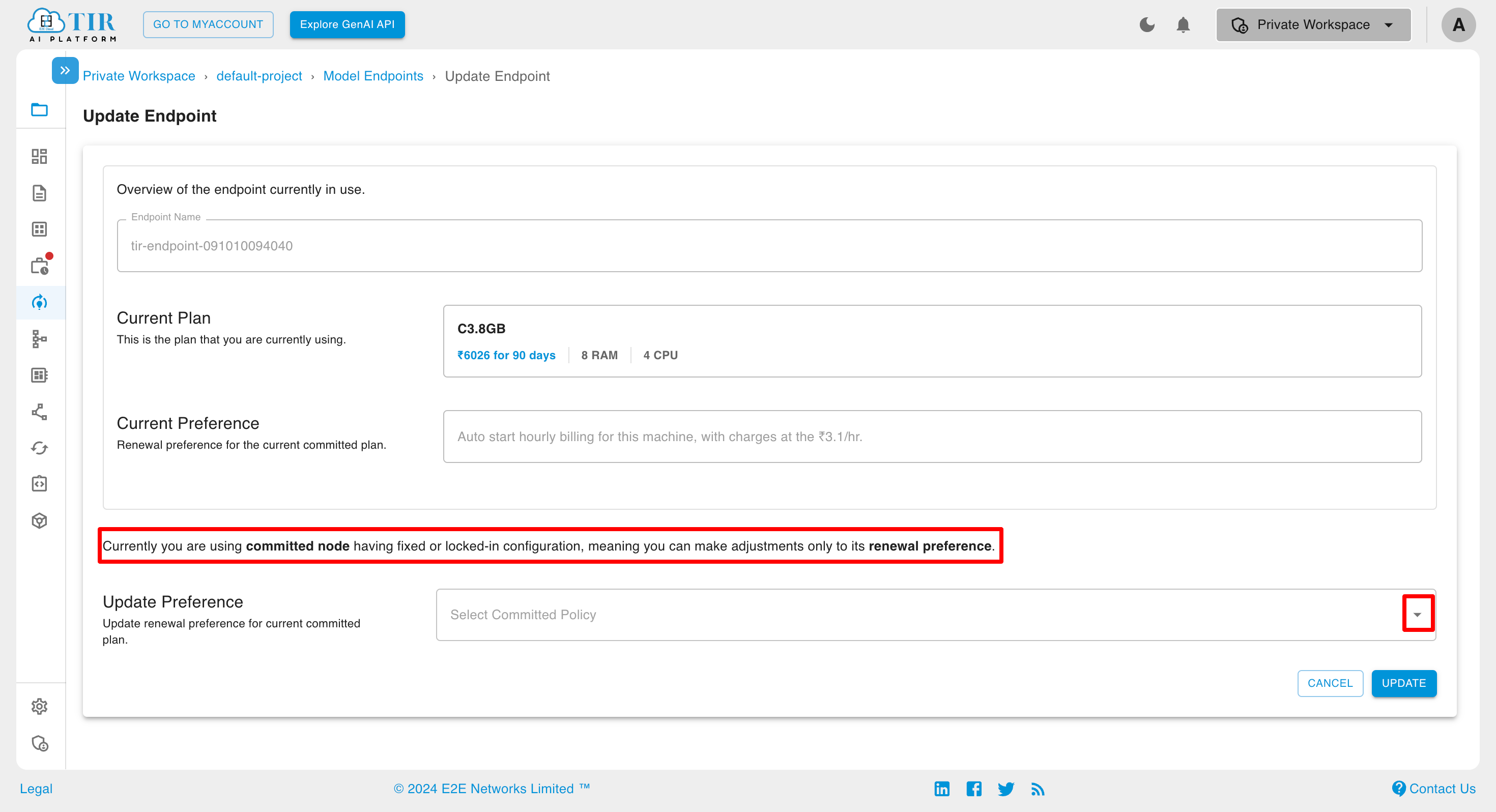
If the committed inference option is selected, a dialog box will appear asking for your preference regarding the next cycle.
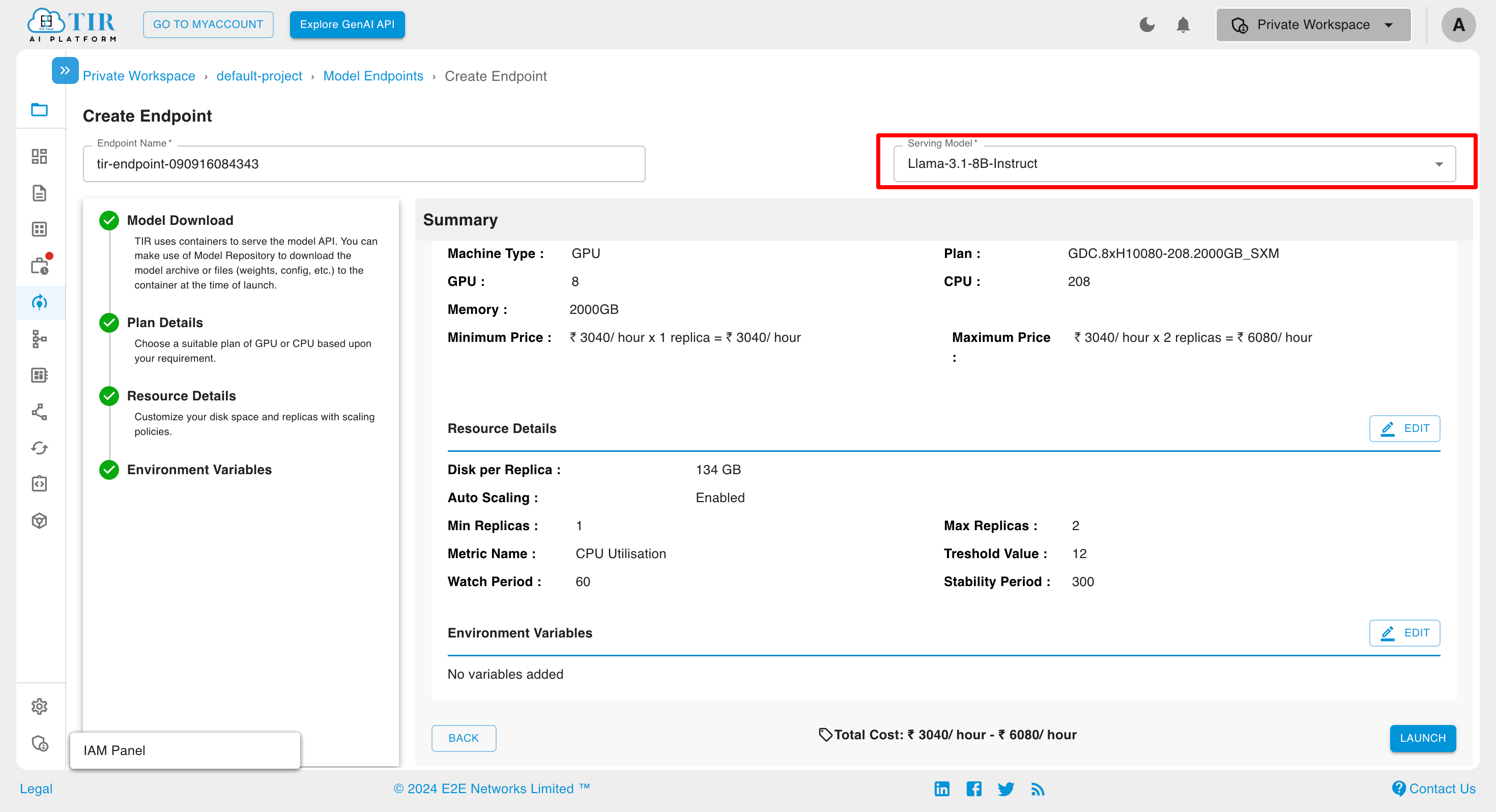
You can change the serving model for the inference at any stage of the inference creation process.
Model Endpoint Dashboard
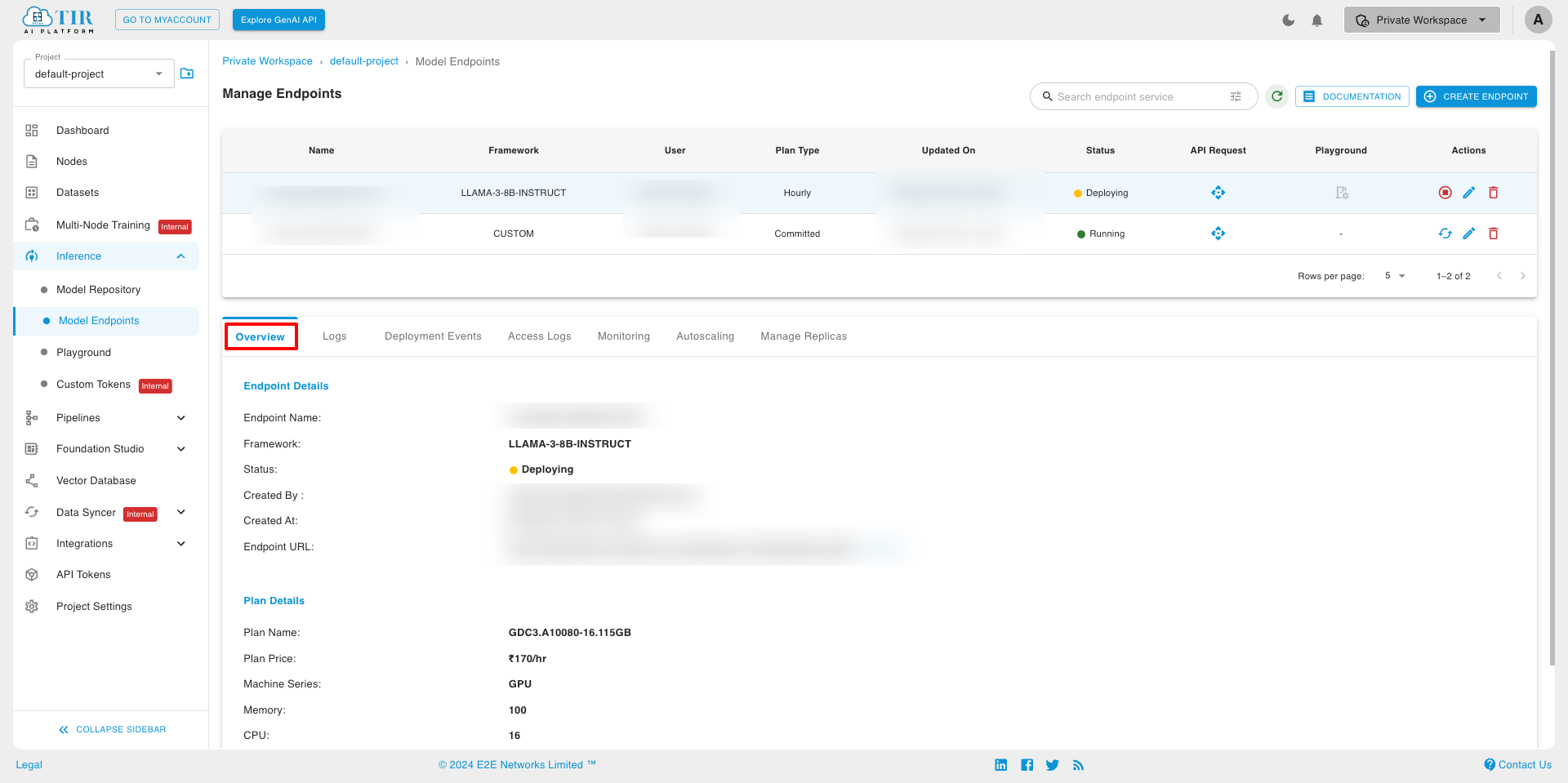
After successfully creating model endpoints, you will see the following screen.
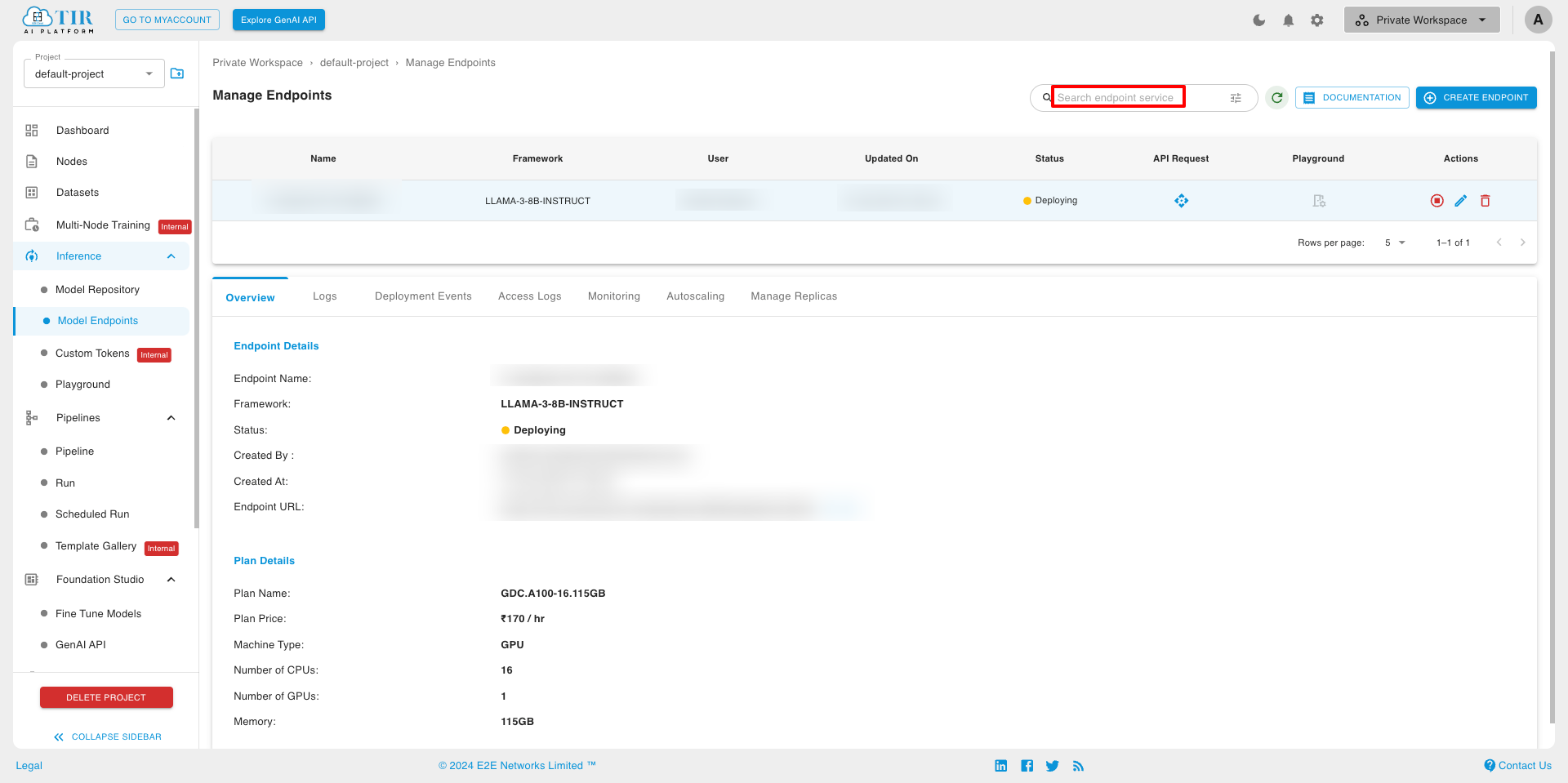
Overview In that overview tab, you can see the Endpoint Details and Plan Details.
Logs In the log tab, logs are generated, and you can view them by clicking on the log tab.
Deployment Events In the Deployments Events tab, the information about Deployment Events are provided.
Access Logs In the Access log tab, Access logs are generated, and you can view them by clicking on the tab.
Monitoring In the Monitoring tab, you can choose between Hardware and Service as metric types. Under Hardware, you’ll find details like GPU Utilization, GPU Memory Utilization, GPU Temperature, GPU Power Usage, CPU Utilization, and Memory Usage.
Serverless Configuration In the Serverless Configuration, you can modify both the Active Worker and Max Worker counts. If the Active Worker count is not equal to the Max Worker, autoscaling will be enabled.
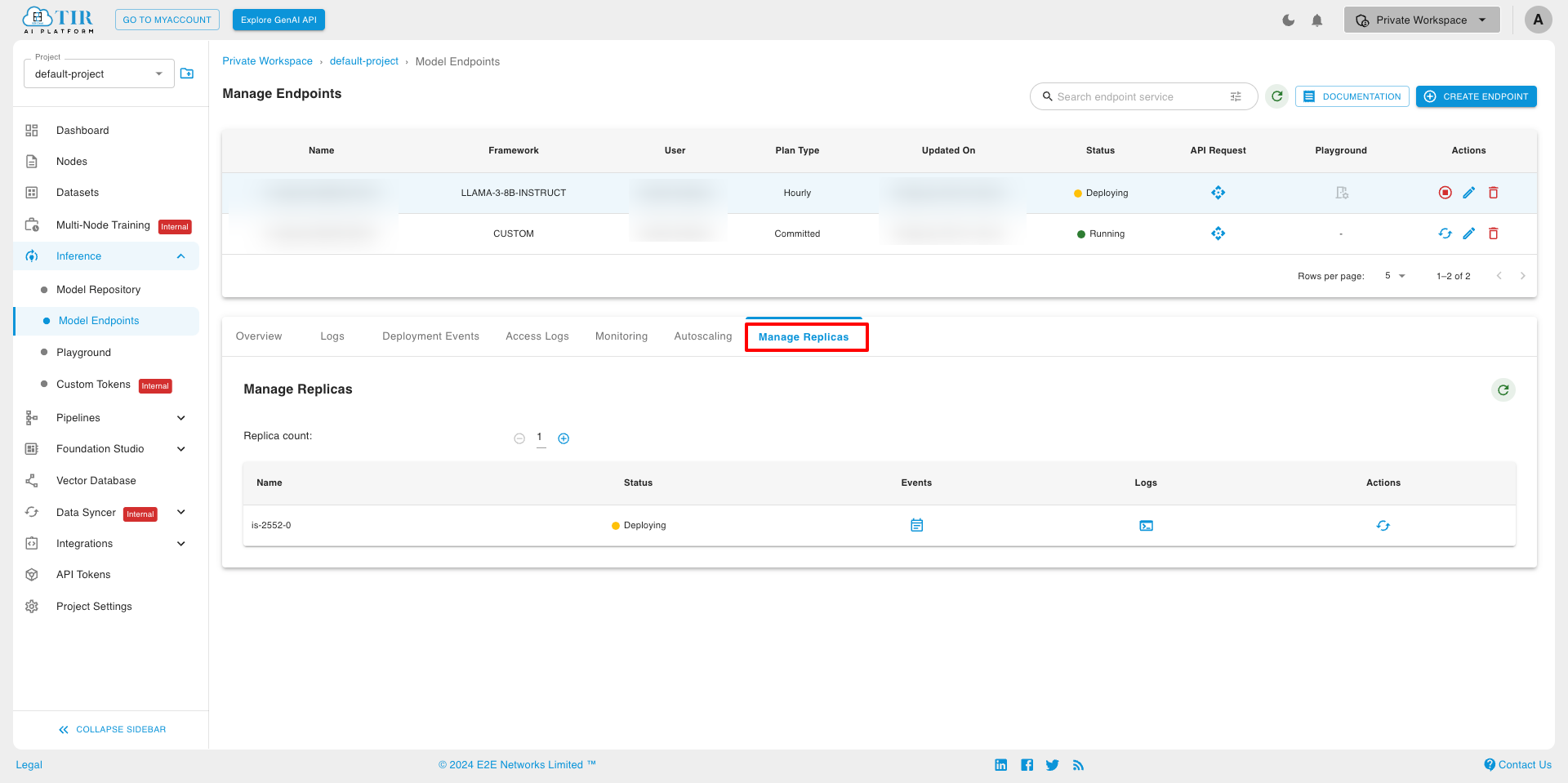
Manage Replicas In the Replica Management tab, you can handle the replicas. You’ll see the current replicas, and you also have the option to delete them by clicking delete icon.
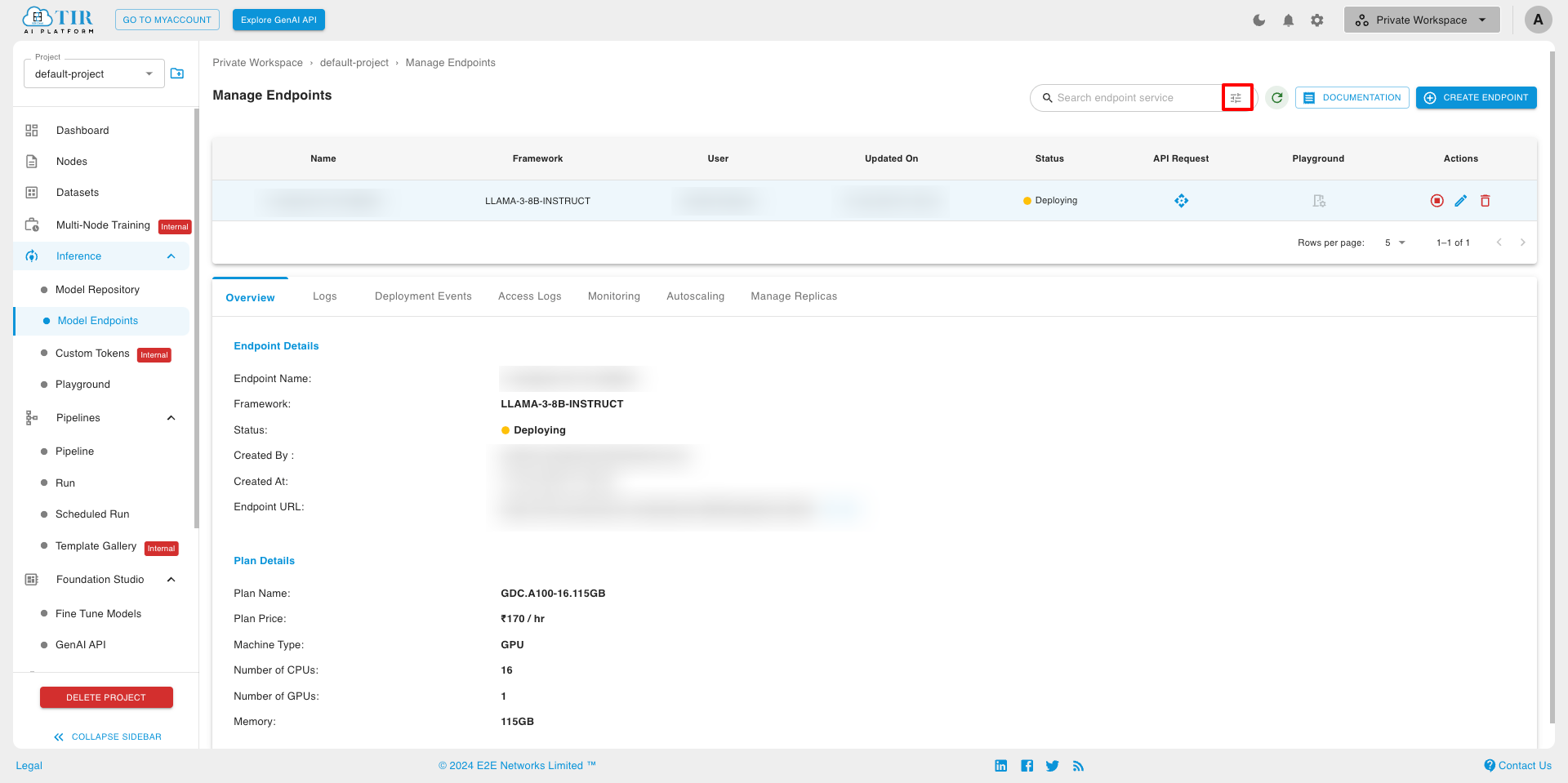
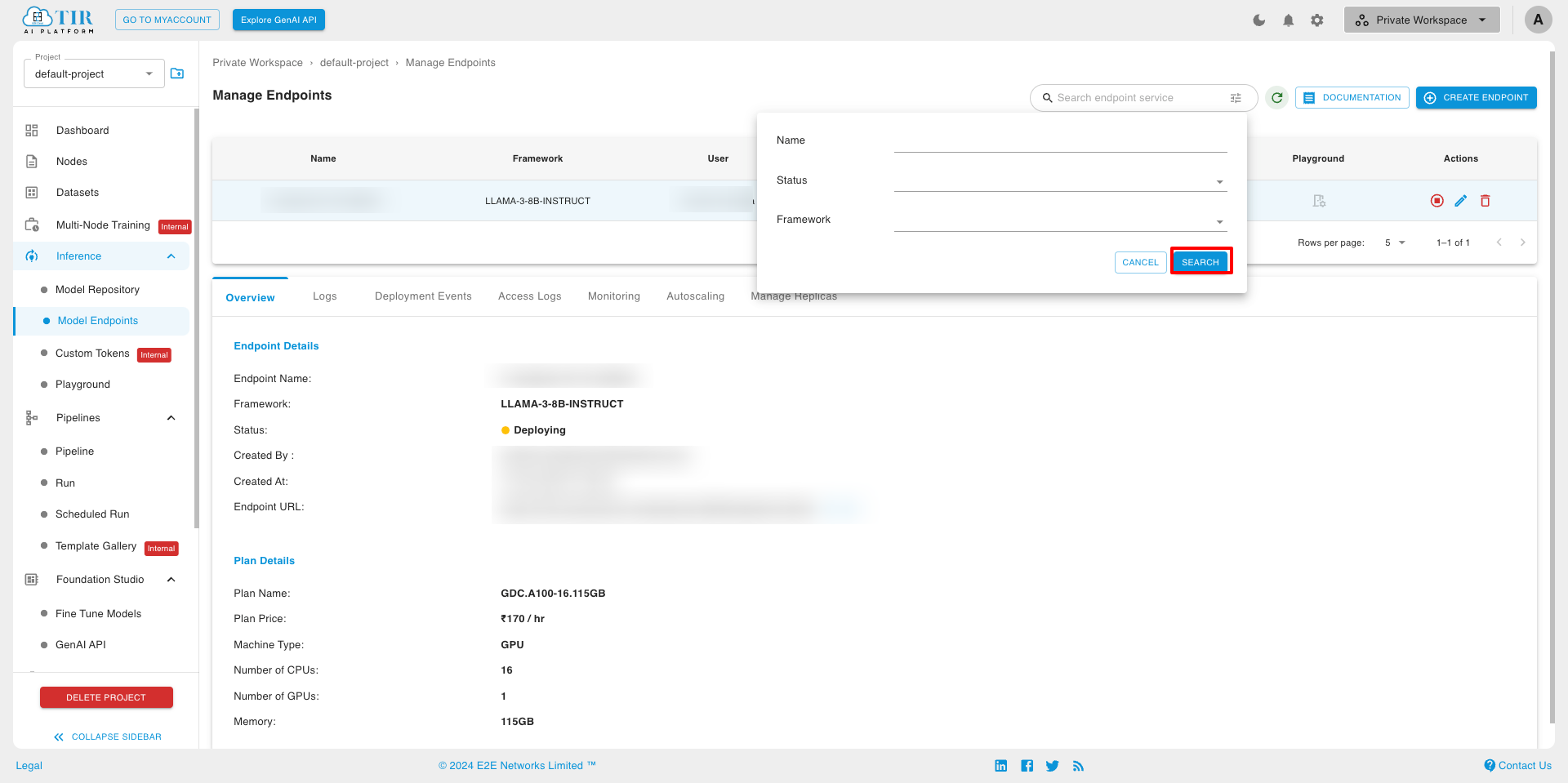
Search Model Endpoint In the search model endpoint tab, You can search for the model endpoint by name and apply advanced filter configurations to refine your search criteria.
Update Model Endpoint
To update a Model Endpoint you have to click on Edit option.
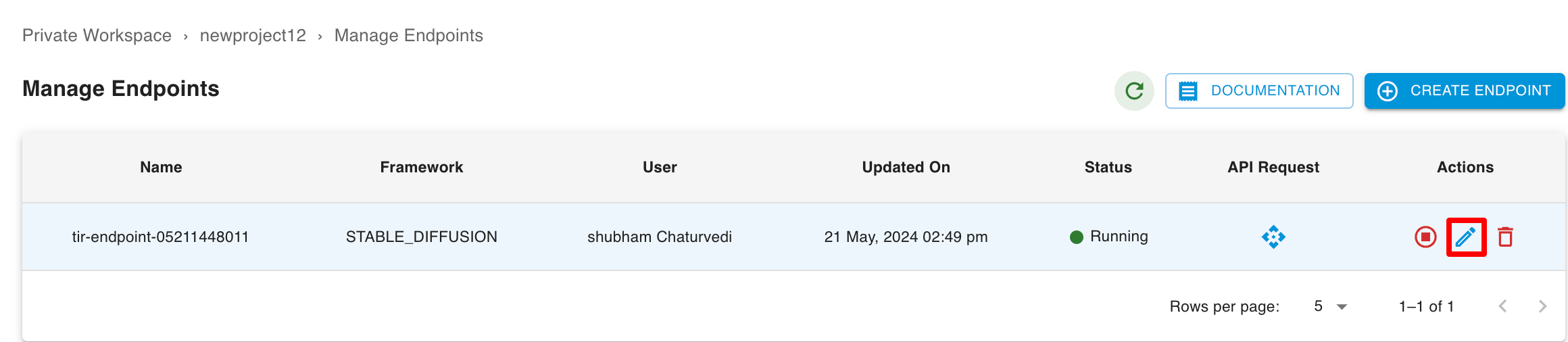
When it is Committed inference
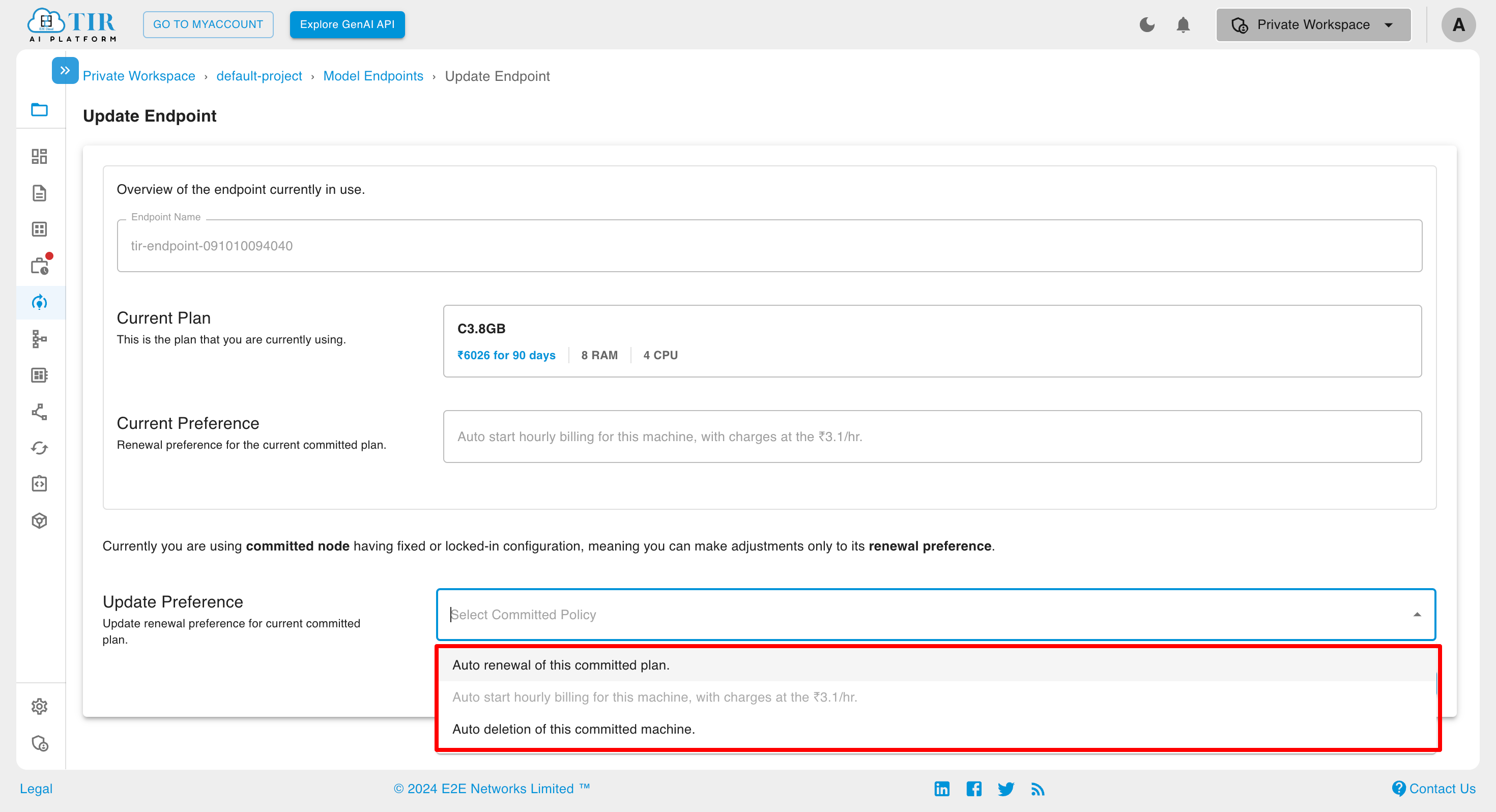
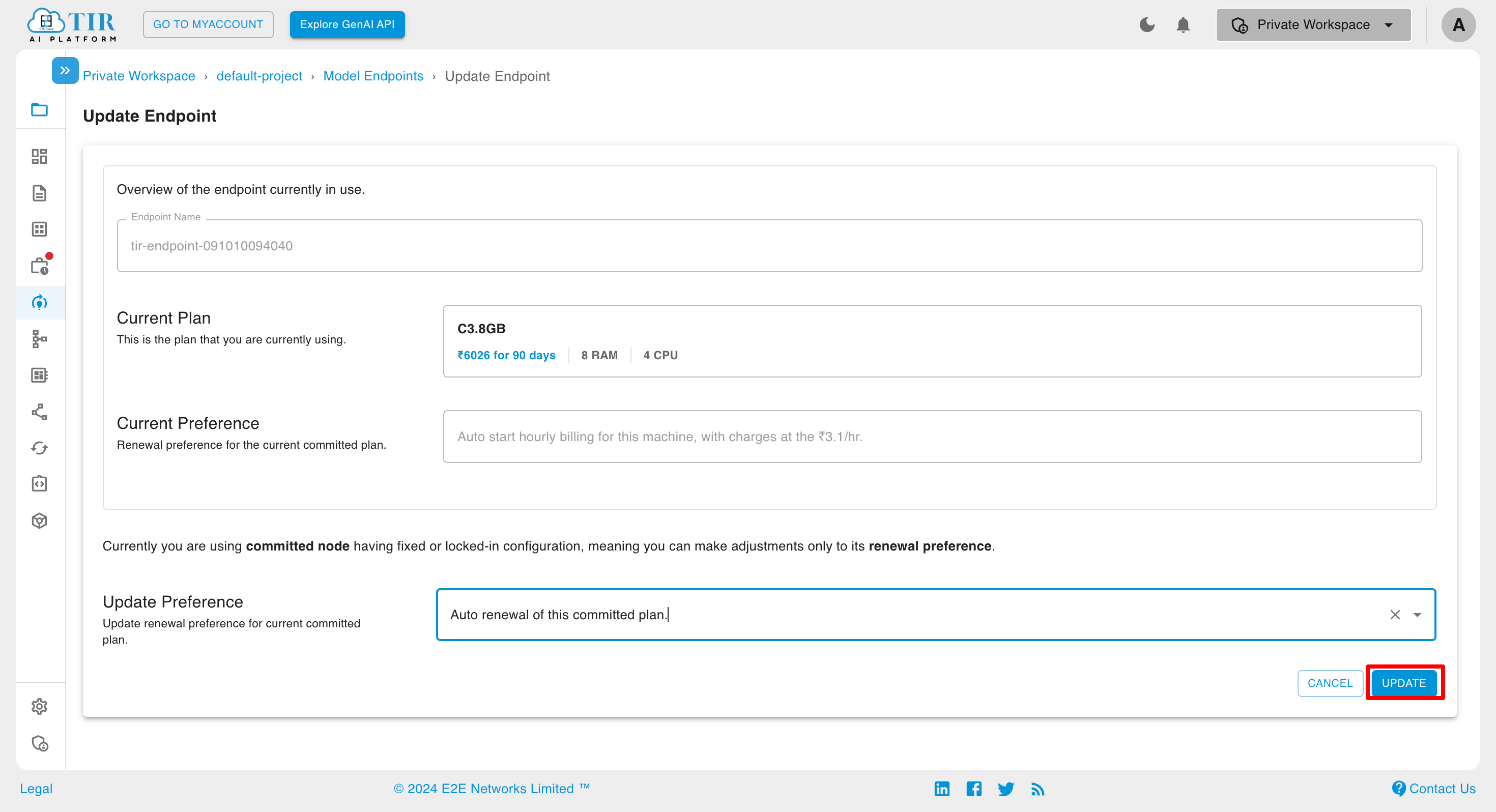
When it is Hourly Billed inference
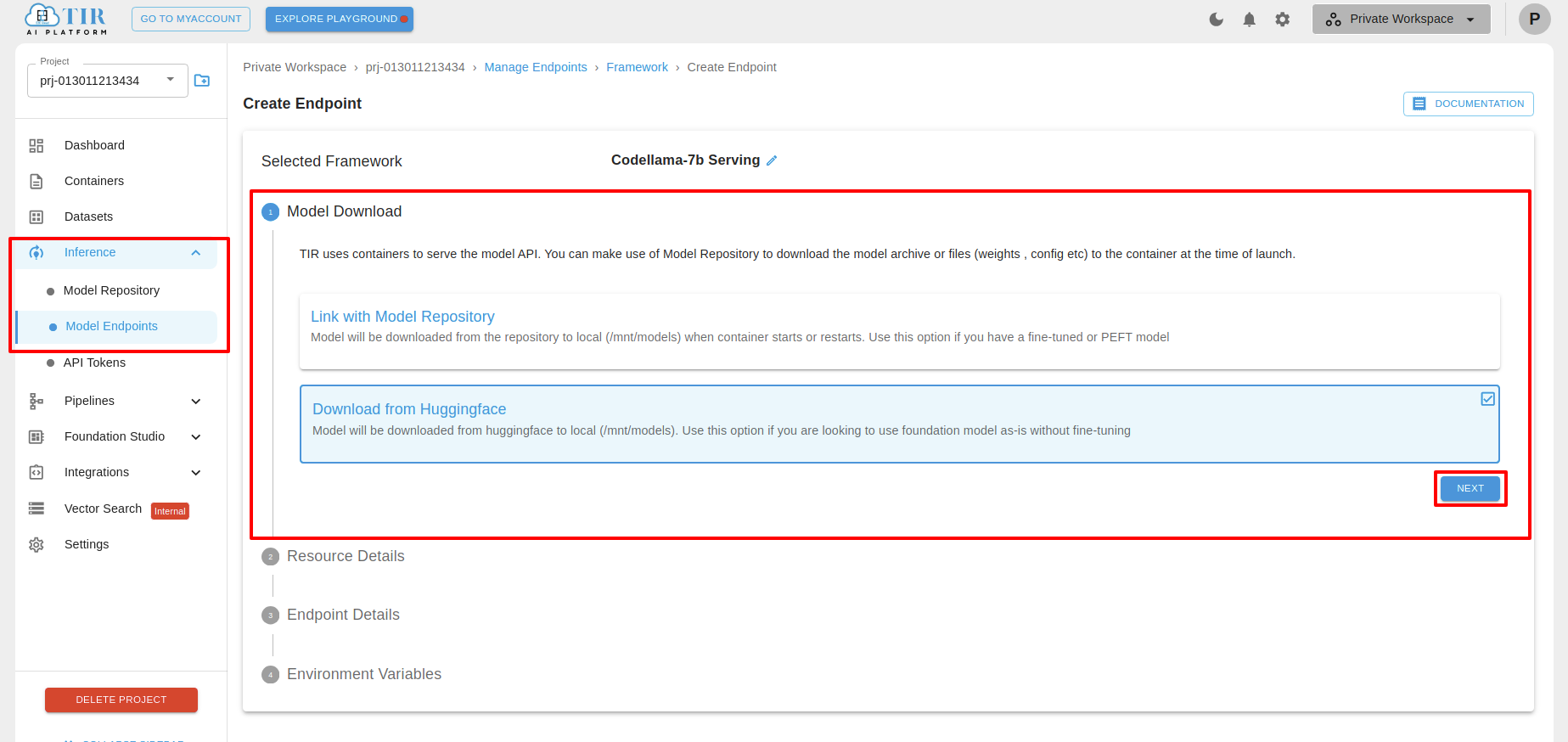
Model Download
Here you can select Link with Model Repository or Download from Huggingface.
Machine
Here you can select a machine type either GPU or CPU.
When updating an Hourly Billed Inference, only the Storage per Worker can be modified. All other aspects, such as scaling and worker adjustments, are managed through the Serverless Configuration tab.
Environment Variable
Add Variable
Summary