Knowledge Base
Knowledge base (KB) is a structured repository of information, designed to store and organize data that the retrieval model can access to find relevant context for a language model (LLM) to generate accurate responses. The KB in RAG systems acts as the “memory” from which relevant knowledge is retrieved and used to enhance response quality.
Key Components and Functionality of a Knowledge Base in RAG
Data Sources and Parsing:
The KB typically consists of various types of data, including documents (FAQs, guides, reports), structured datasets, and other relevant content. Data is preprocessed and parsed into smaller chunks (paragraphs, sentences, or user-defined sections) to enable efficient retrieval.
Embedding and Vectorization:
Each chunk of text is converted into an embedding—a numerical vector that captures the semantic meaning of the text—using models like BERT, RoBERTa, or specialized embedding models. These embeddings allow the KB to organize data in a way that enables similarity-based search, so the retriever can locate contextually relevant information quickly.
Indexing for Efficient Search:
The KB is indexed to support rapid retrieval based on vector similarity. This indexing helps match user queries to relevant chunks in the KB, based on their semantic similarity. Indexing methods like FAISS (Facebook AI Similarity Search) are commonly used to optimize this process.
Retrieval of Contextual Data:
When a user query is received, the RAG system’s retriever searches the KB for chunks that closely match the meaning of the query. The retrieved chunks are then passed to the LLM, which uses them as context to generate a more accurate and informed response.
Knowledge Base Updating and Maintenance:
The KB in a RAG system can be updated with new information as it becomes available, which ensures that the RAG system stays accurate and up-to-date. Changes in company policies, new product information, and relevant knowledge are added to the KB, and embeddings are recalculated as needed.
Getting Started
Create a new Knowledge Base
Log in to the TIR AI Platform: Ensure you are logged in and working within the correct project. If needed, you can create a new project.
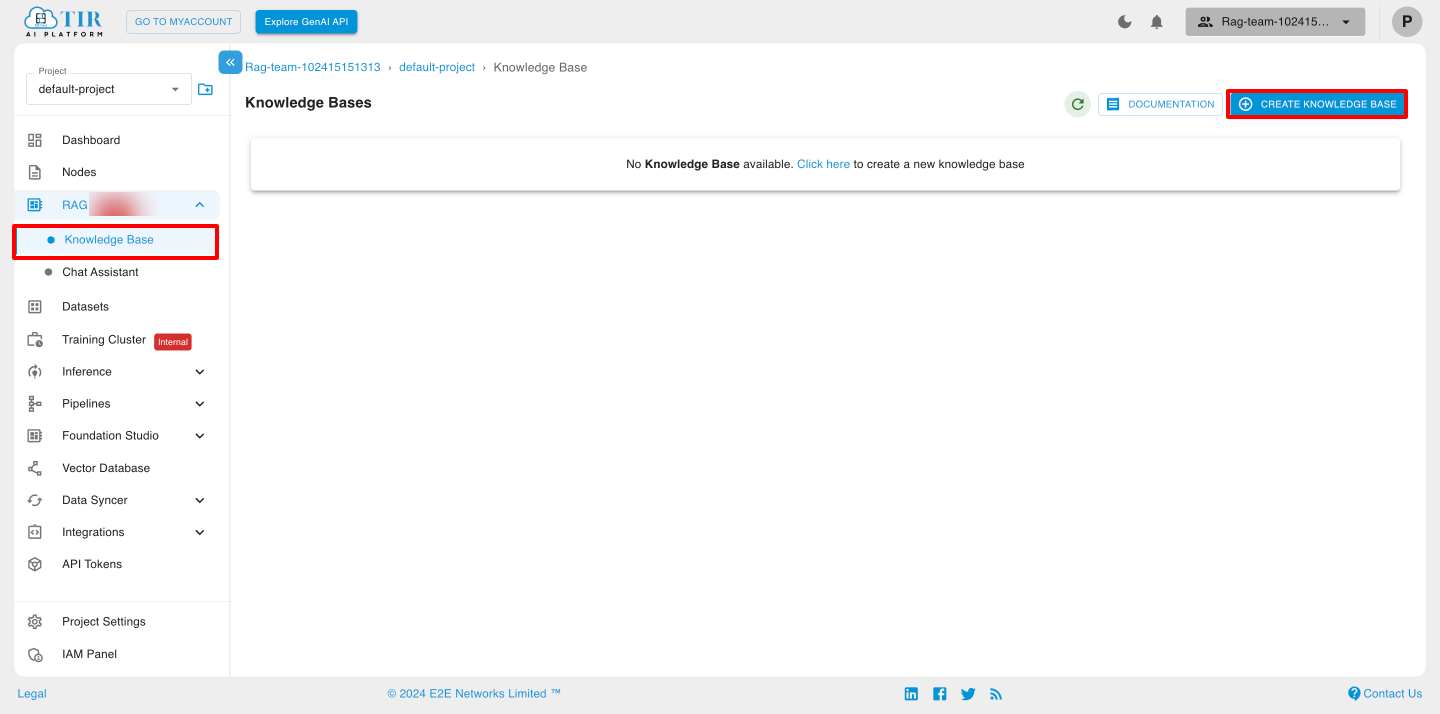
Navigate to the Rag Section: From the TIR dashboard, go to the Knowledge Base section.
Click on the Create Knowledge Base button.
You will be redirected to the “Create Knowledge Base” page. Fill in all the required details, then click the “Create” button.
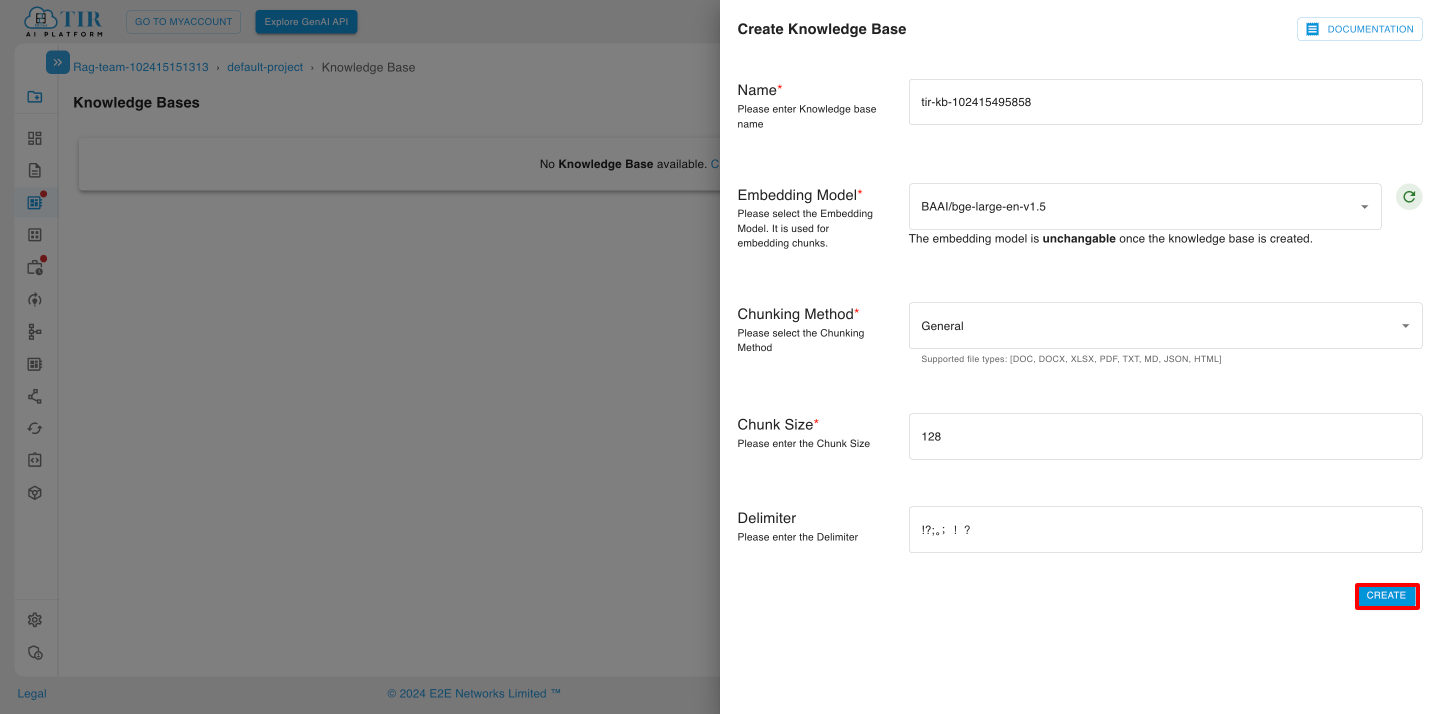
Embedding Model - Embedding models in a knowledge base are used to convert textual data (or other data types) into numerical representations, called embeddings, that capture semantic meaning. These embeddings allow a knowledge base to perform efficient search, comparison, and retrieval of relevant information based on the meaning rather than exact word matching
Chunking Method - Chunking in a knowledge base is a method of dividing larger documents or datasets into smaller, manageable “chunks” of information. This is especially useful in systems that rely on retrieval-augmented generation (RAG) models or semantic search techniques, as it allows for more accurate retrieval and generation of responses by working with smaller, focused pieces of content.
Chunk Size - Chunk size in a knowledge base refers to the length (in terms of words, tokens, sentences, or characters) of each divided section or “chunk” of a document. Choosing an optimal chunk size is critical for balancing context preservation, retrieval accuracy, and computational efficiency in knowledge bases that use techniques like retrieval-augmented generation (RAG) or semantic search.
Delimiter - A delimiter in a knowledge base is a character or sequence of characters used to separate sections of text or data. Delimiters play a critical role in chunking, parsing, and structuring data within a knowledge base, making it easier for systems to process and retrieve information accurately.
Entity Type - In a knowledge base, entity types provide a flexible, structured approach to organizing information, allowing the system to deliver precise, relevant, and contextually appropriate information across diverse applications
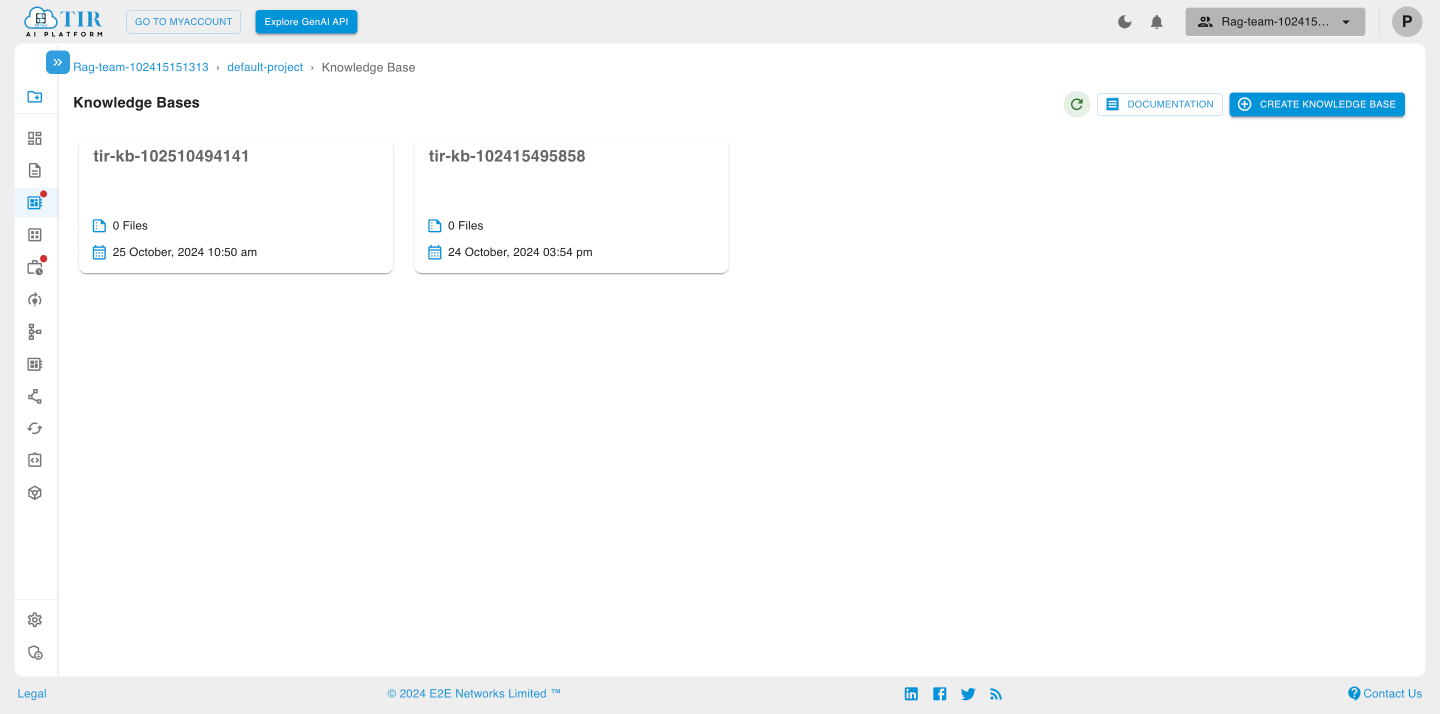
Knowledge Base List
You will see a list of Knowledge Bases as shown in the image below. Click on a specific Knowledge Base to upload documents or update other details.
Documents
After selecting a specific Knowledge Base, you will be redirected to the Document section. In this section, you can upload data or files by two ways either browser files or import from Tir dataset.
To upload files click on ‘Import Data’.
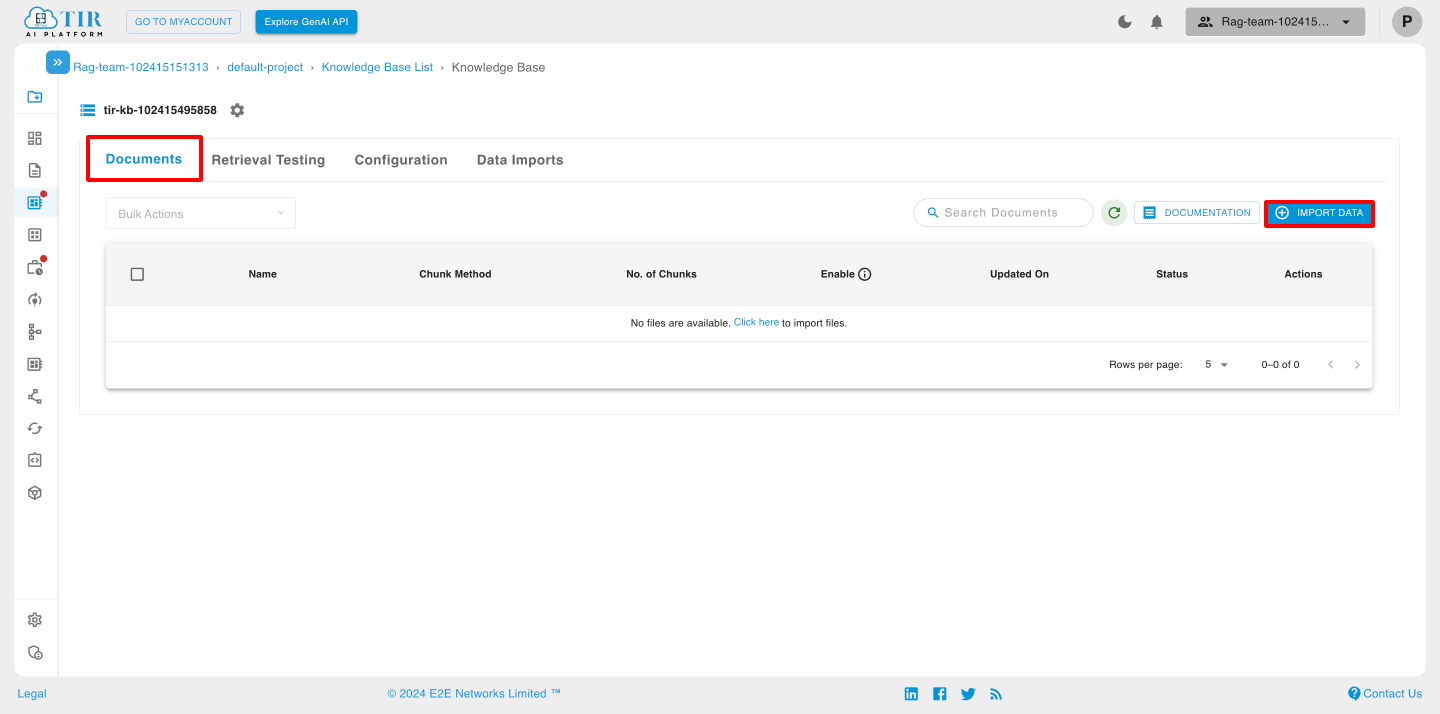
Browse Files
In this you have to click on Drop a file or click to upload to import data.
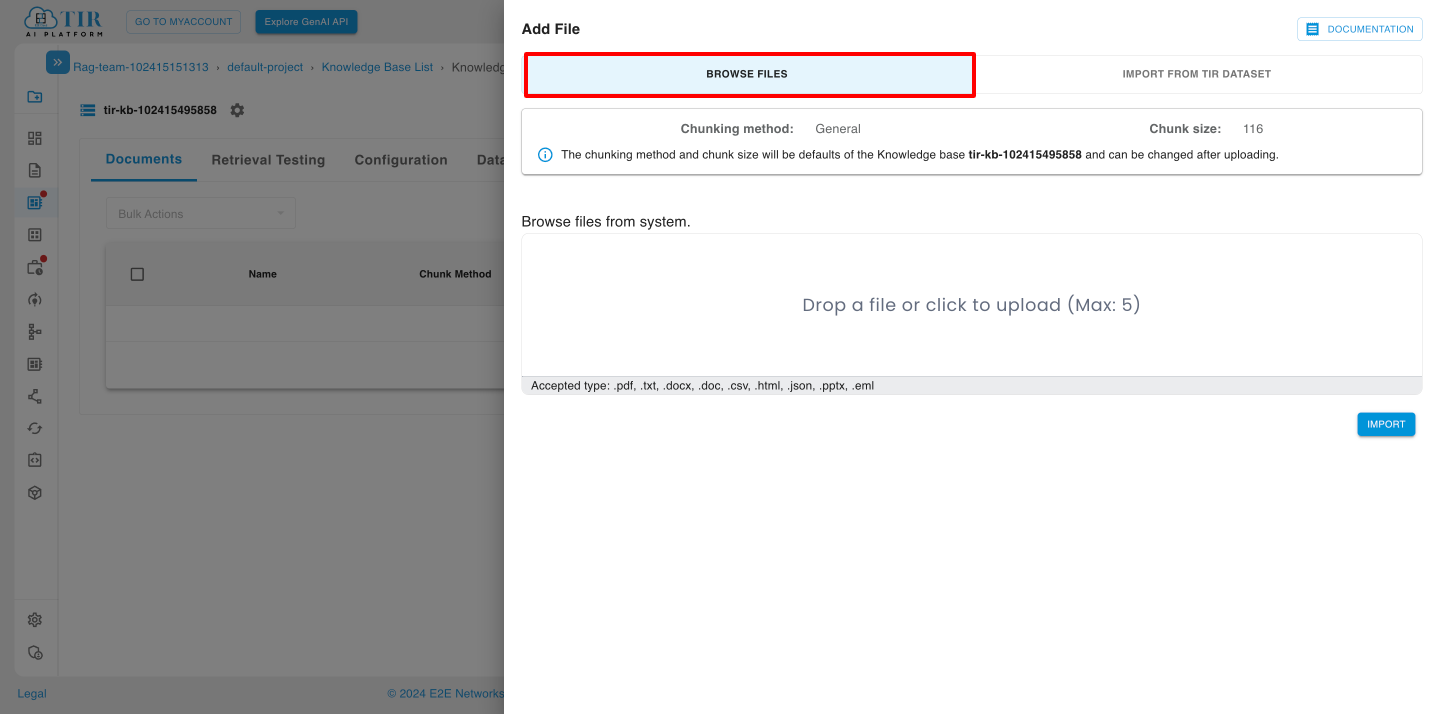
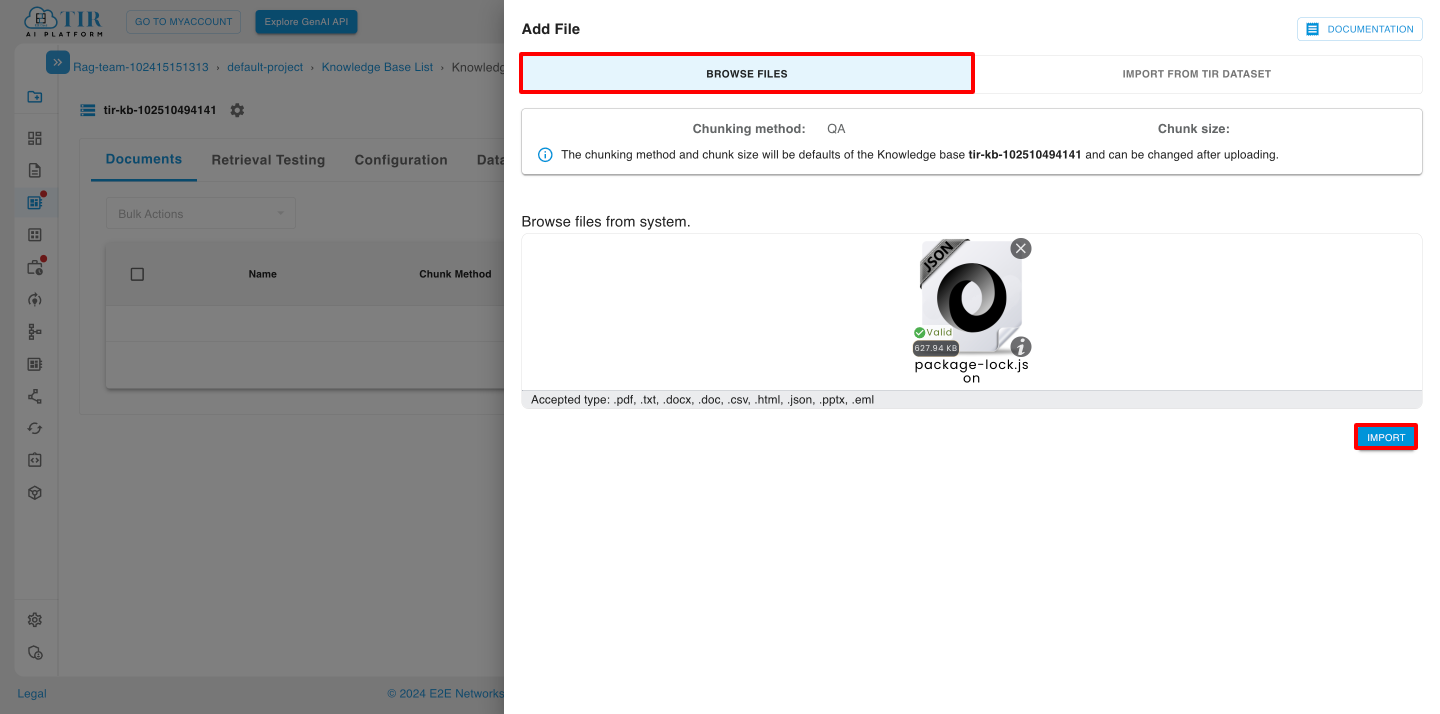
After selecting files, click on import button.
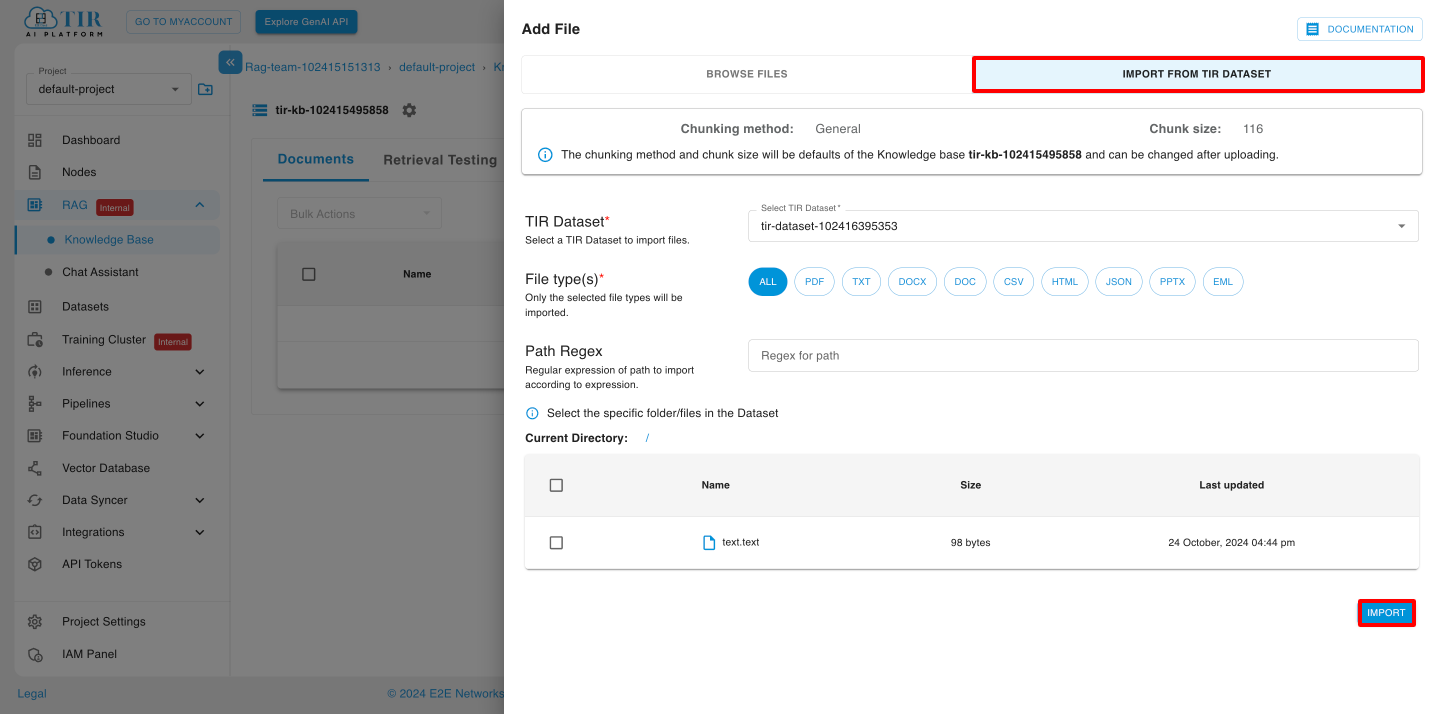
Import from Tir dataset
To select a dataset, click on the “Tir Dataset” dropdown. A list of datasets from your account will appear. Choose the desired dataset and specific file, then click the “Import” button.
Retrieval Testing
Retrieval testing in a knowledge base involves evaluating how effectively the system retrieves relevant information based on user queries. This process is crucial to ensure that the knowledge base meets user needs, provides accurate answers, and supports efficient information retrieval.
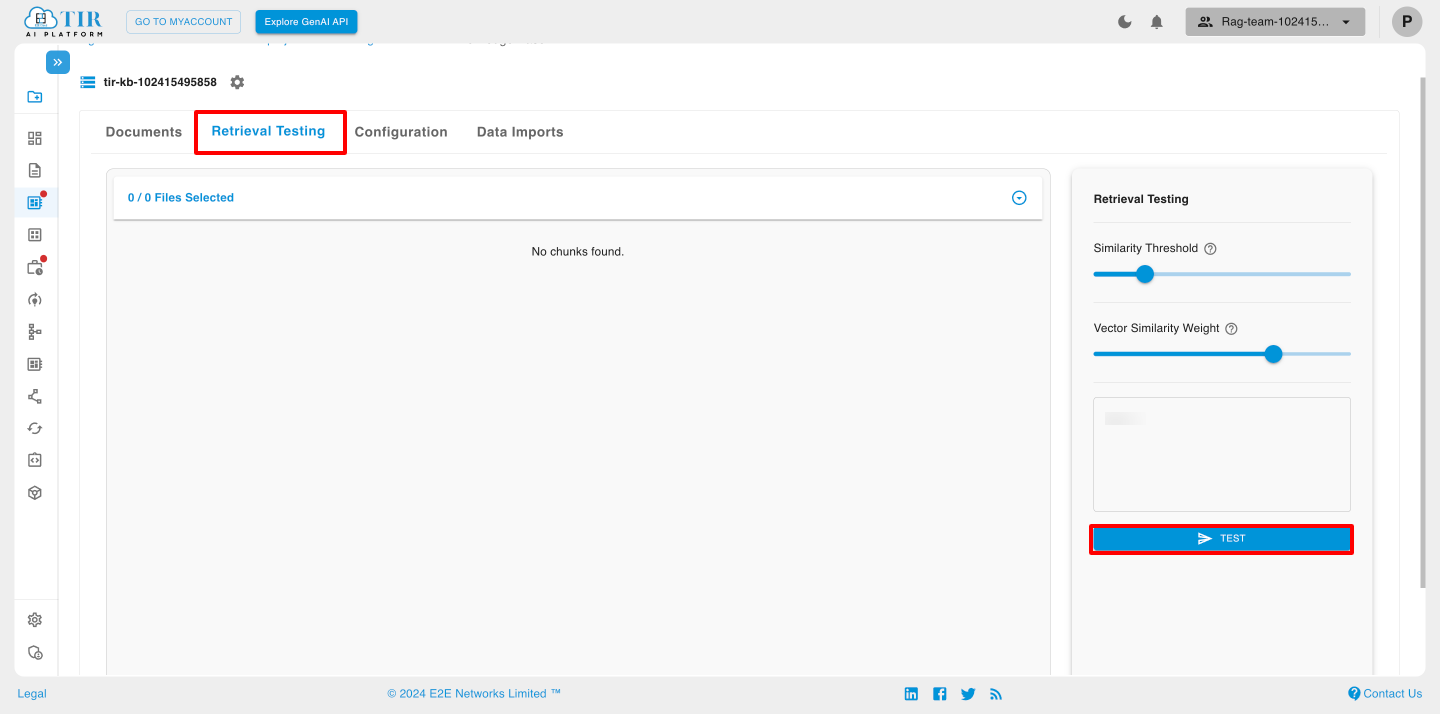
Key Components of Retrieval Testing
1. Test Queries:
Develop a set of diverse test queries that represent the types of questions users might ask.
Include various formats, such as keywords, natural language questions, and specific entity queries.
2. Expected Results:
For each test query, define the expected results based on the content of the knowledge base.
This helps in assessing the accuracy and relevance of the retrieval process.
3. Retrieval Mechanism:
Understand the underlying retrieval mechanism (e.g., keyword matching, semantic search, embeddings).
Ensure that the retrieval process aligns with the designed architecture of the knowledge base.
4. Performance Metrics:
Measure the effectiveness of retrieval using metrics such as:
Precision: The ratio of relevant results retrieved to the total results retrieved.
Recall: The ratio of relevant results retrieved to the total relevant results available.
F1 Score: The harmonic mean of precision and recall, providing a balance between the two.
Response Time: The time taken to retrieve and present results.
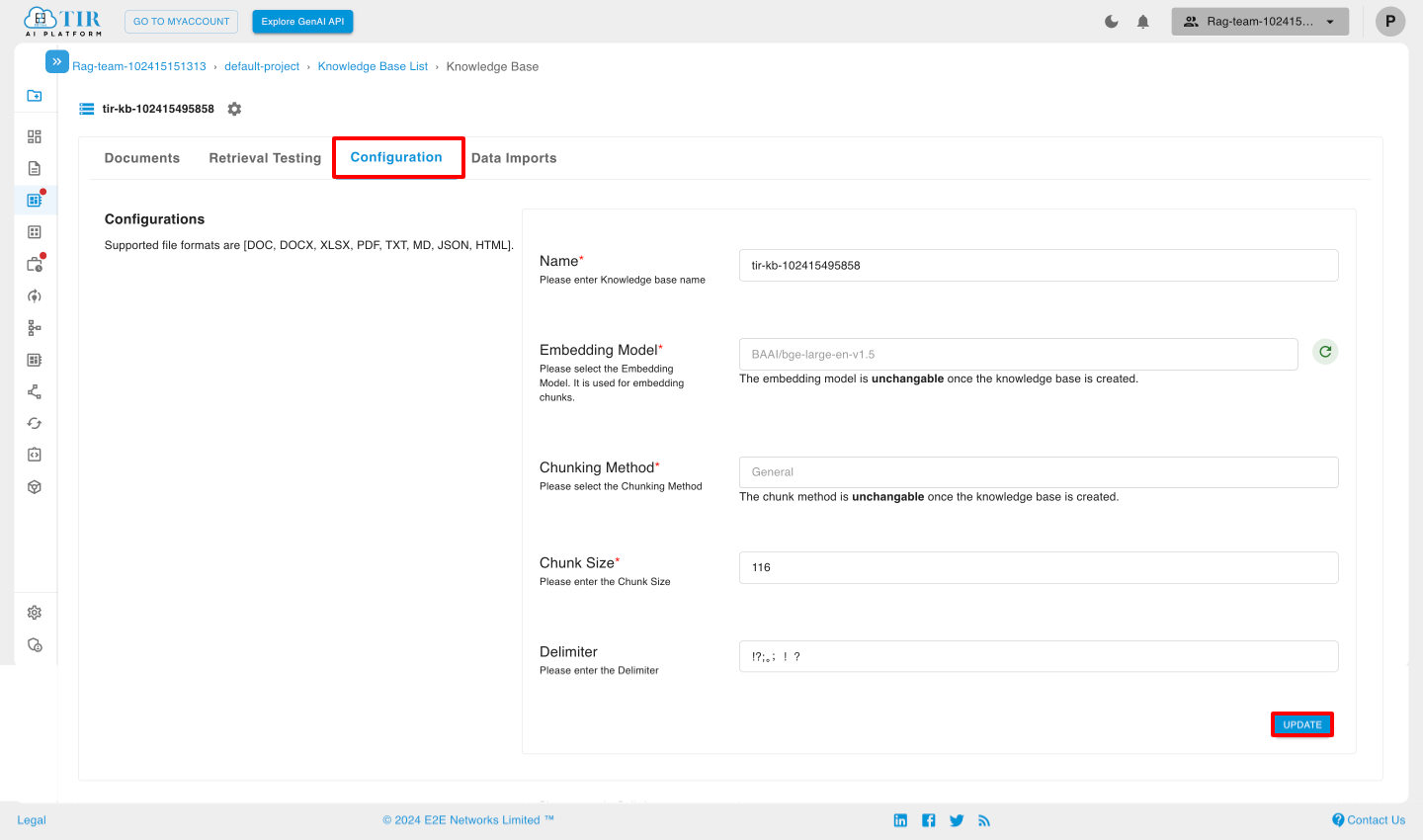
Configuration
In this section of the specific Knowledge Base, you can update the chunk size and delimiter.
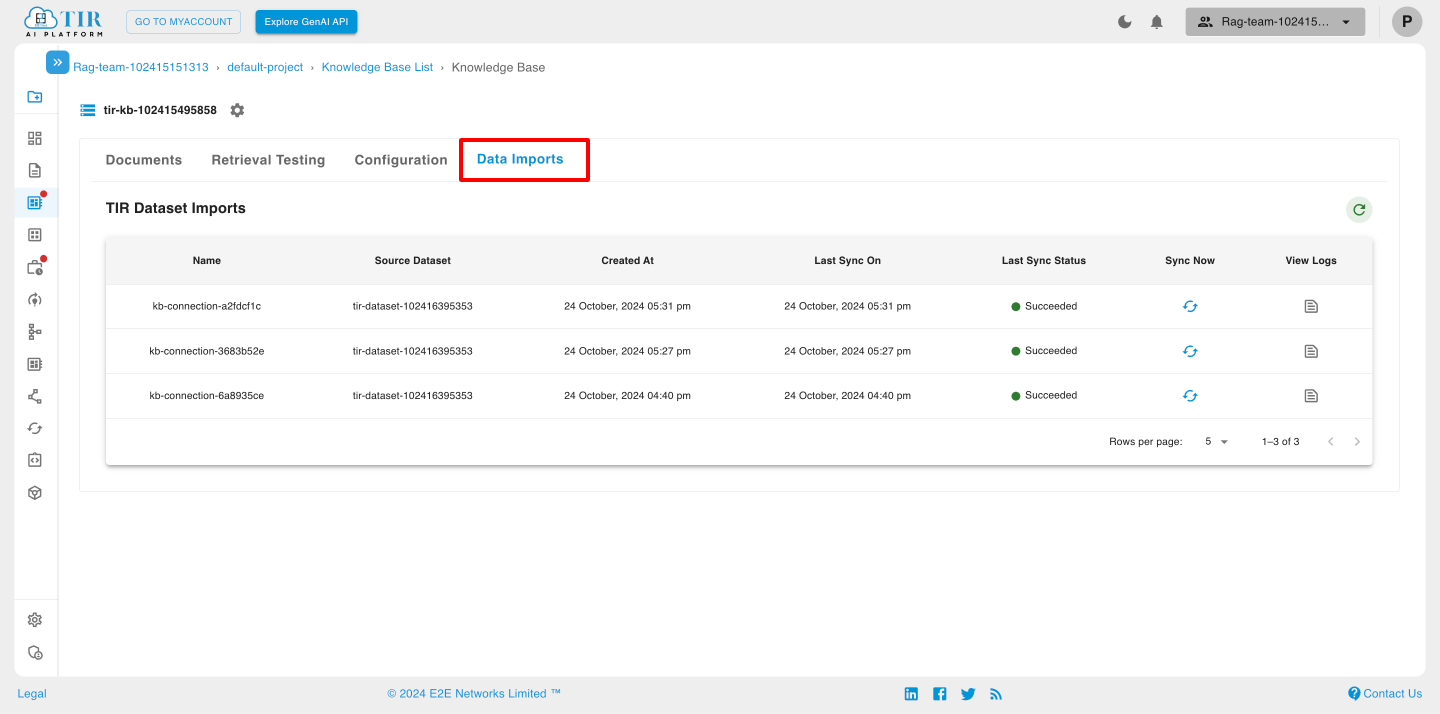
Data Imports
In this you can sync the data and view logs.