Deploy Model Endpoint for Codellama-7b
In this tutorial, we will create a model endpoint for Codellama-7b model.
The tutorial will mainly focus on the following:
Model Endpoint creation for Codellama-7b using prebuilt container
Model Endpoint creation for Codellama-7b, with custom model weights
Model Endpoint creation for Codellama-7b using prebuilt container
When a model endpoint is created in TIR dashboard, in the background a model server is launched to serve the inference requests.
TIR platform supports a variety of model formats through pre-buit containers (e.g. pytorch, triton, llma, mpt etc.).
For the scope of this tutorial, we will use pre-built container (Codellama-7b) for the model endpoint but you may choose to create your own custom container by following this tutorial .
In most cases, the pre-built container would work for your use case. The advantage is - you won’t have to worry about building an API handler. API handler will be automatically created for you.
Steps to create inference endpoint for Codellama-7b model:
Step 1: Create a Model Endpoint
Go to TIR AI Platform
Choose a project
Go to Model Endpoints section
Create a new Endpoint
Choose Codellama-7b model card
Pick a suitable CPU/GPU plan of your choice & set the replicas & disk size(CPU plans might take more time)
If you wish to load your custom model weights (fine-tuned or not), select the appropriate model, i.e., the EOS bucket containing your weights. (See Creating Model Endpoint with custom model weights section below)
If not, you can skip the model details & proceed further
Complete the endpoint creation
Model creation might take few minutes you can always see logs in log section.
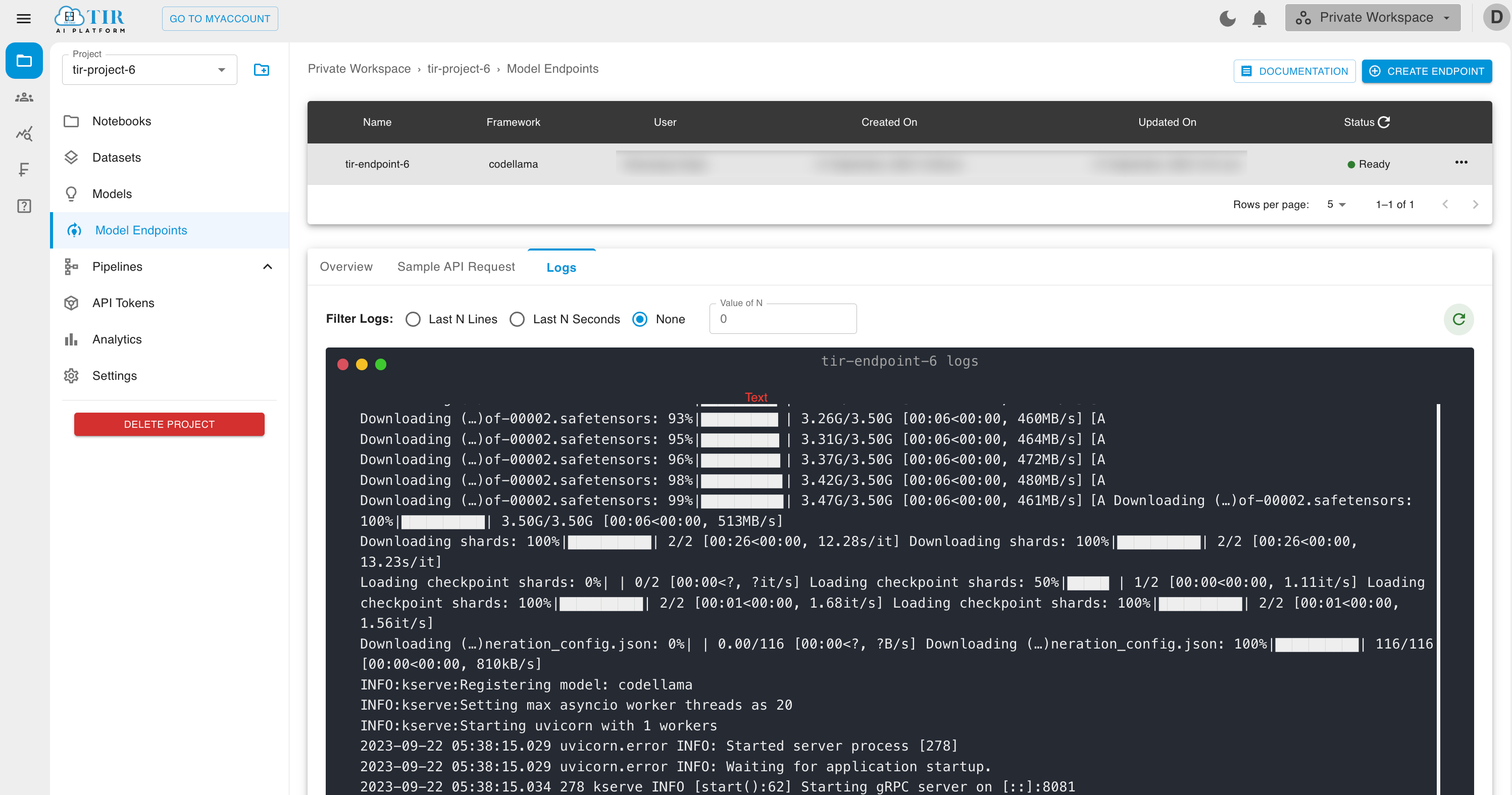
Step 2: Generate your API_TOKEN
The model endpoint API requires a valid auth token which you’ll need to perform further steps. So, let’s generate one.
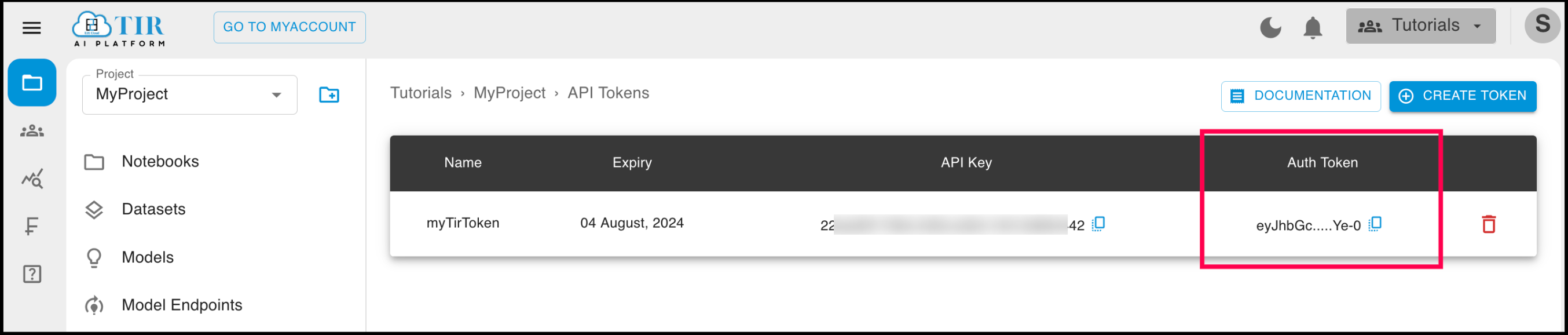
Go to API Tokens section under the project.
Create a new API Token by clicking on the Create Token button on the top right corner. You can also use an existing token, if already created.
Once created, you’ll be able to see the list of API Tokens containing the API Key and Auth Token. You will need this Auth Token in the next step.
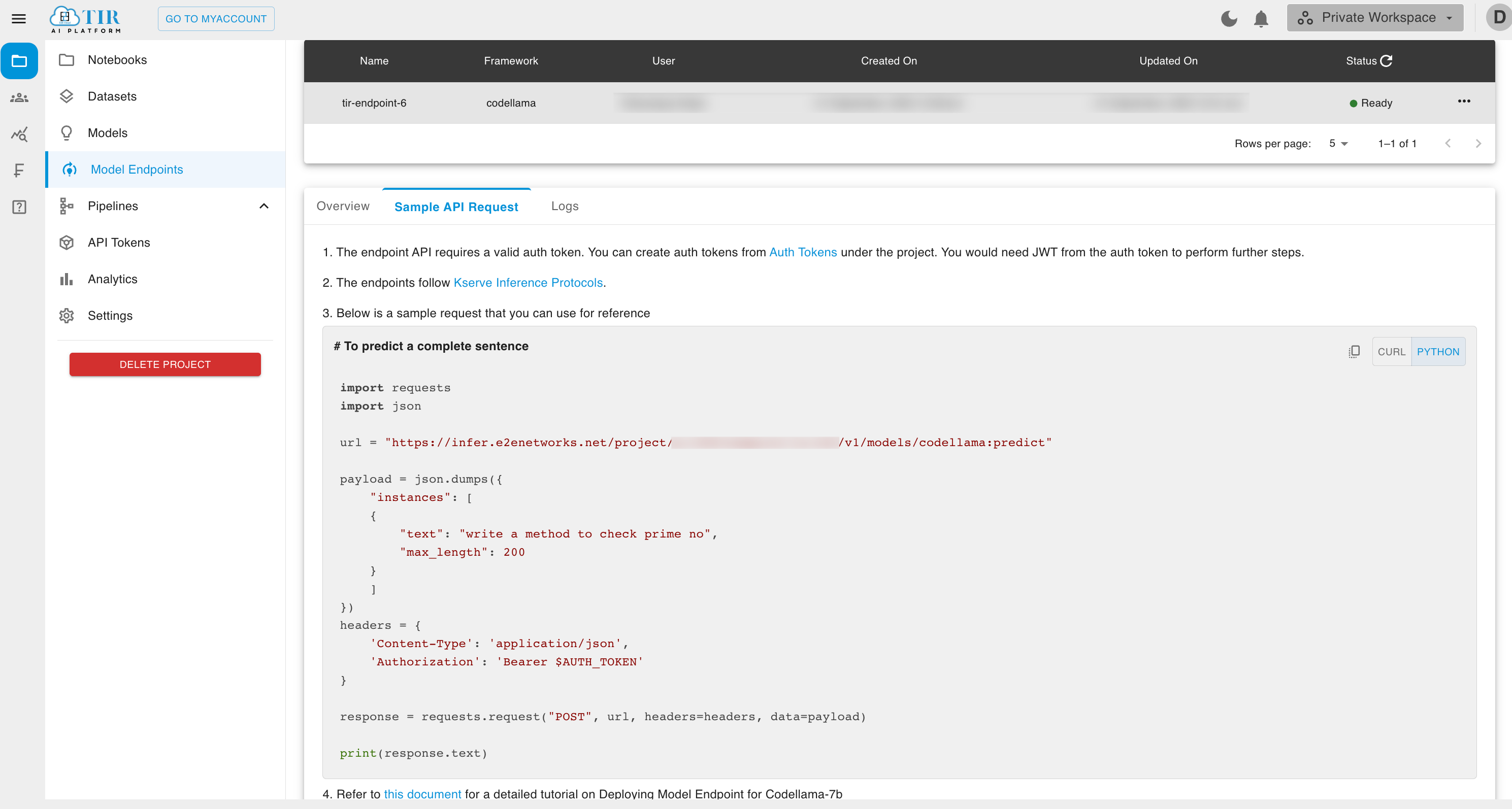
Step 3: Inferring Request
When your endpoint is ready, visit the Sample API request section to test your endpoint using curl.
Creating Model endpoint with custom model weights
To create Inference against Codellama-7b model with custom model weights, we will:
Download Codellama-7b model from huggingface
Upload the model to Model Bucket (EOS)
Create an inference endpoint (model endpoint) in TIR to serve API requests
Step 1: Define a model in TIR Dashboard
Before we proceed with downloading or fine-tuning (optional) the model weights, let us first define a model in TIR dashboard.
Go to TIR AI Platform
Choose a project
Go to Model section
Click on Create Model
Enter a model name of your choosing (e.g. tir-model-34)
Select Model Type as Custom
Click on CREATE
You will now see details of EOS (E2E Object Storage) bucket created for this model.
EOS Provides a S3 compatible API to upload or download content. We will be using MinIO CLI in this tutorial.
Copy the Setup Host command from Setup Minio CLI tab to a notepad or leave it in the clipboard. We will soon use it to setup MinIO CLI
Note
In case you forget to copy the setup host command for MinIO CLI, don’t worry. You can always go back to model details and get it again.
Step 2: Start a new Notebook
To work with the model weights, we will need to first download them to a local machine or a notebook instance.
In TIR Dashboard, Go to Notebooks
Launch a new Notebook with Transformers Image and a hardware plan (e.g. A10080). We recommend a GPU plan if you plan to test or fine-tune the model.
Click on the Notebook name or Launch Notebook option to start jupyter labs environment
In the jupyter labs, Click New Launcher and Select Terminal
Now, paste and run the command for setting up MinIO CLI Host from Step 1
If the command works, you will have mc cli ready for uploading our model
Step 3: Download the Codellama-7b model from notebook
Now, our EOS bucket will store the model weights. Let us download the weights from Hugging face.
Start a new notebook untitled.ipynb in jupyter labs
Run the following commands in download the model. The model will be downloaded by huggignface sdk in the $HOME/.cache folder
from transformers import AutoTokenizer import transformers import torch model = "codellama/CodeLlama-7b-hf" tokenizer = AutoTokenizer.from_pretrained(model) pipeline = transformers.pipeline( "text-generation", model=model, torch_dtype=torch.float16, device_map="auto", tokenizer=tokenizer)Note
If you face any issues running above code in the notebook cell, you may be missing required libraries. This may happen if you did not launch the notebook with Transformers image. In such situation, you can install the required libraries below:
Let us run a simple inference to test the model.
prompt = "def factorial(num: int):" sequences = pipeline(prompt, do_sample=True, top_k=10, temperature=0.1, top_p=0.95, num_return_sequences=1, eos_token_id=tokenizer.eos_token_id, max_length=200 )Note
All the supported parameters are listed in Supported Parameters
Step 4: Upload the model to Model Bucket (EOS)
Now that the model works as expected, you can fine-tune it with your own data or choose to serve the model as-is. This tutorial assumes you are uploading the model as-is to create inference endpoint. In case you fine-tune the model, you can follow similar steps to upload the model to EOS bucket.
# go to the directory that has the huggingface model code.
cd $HOME/.cache/huggingface/hub/models--codellama--CodeLlama-7b-hf/snapshots
# push the contents of the folder to EOS bucket.
# Go to TIR Dashboard >> Models >> Select your model >> Copy the cp command from Setup MinIO CLI tab.
# The copy command would look like this:
# mc cp -r <MODEL_NAME> codellama-7b/codellama-7b-hf
# here we replace <MODEL_NAME> with '*' to upload all contents of snapshots folder
mc cp -r * codellama-7b/codellama-7b-hf
Note
The model directory name may be a little different (we assume it is models–codellama–CodeLlama-7b-hf). In case, this command does not work, list the directories in the below path to identify the model directory
$HOME/.cache/huggingface/hub
Step 5: Create an endpoint for our model
With model weights uploaded to TIR Model’s EOS Bucket, what remains is to just launch the endpoint and serve API requests.
Head back to the section on A guide on Model Endpoint creation above and follow the steps to create the endpoint for your model.
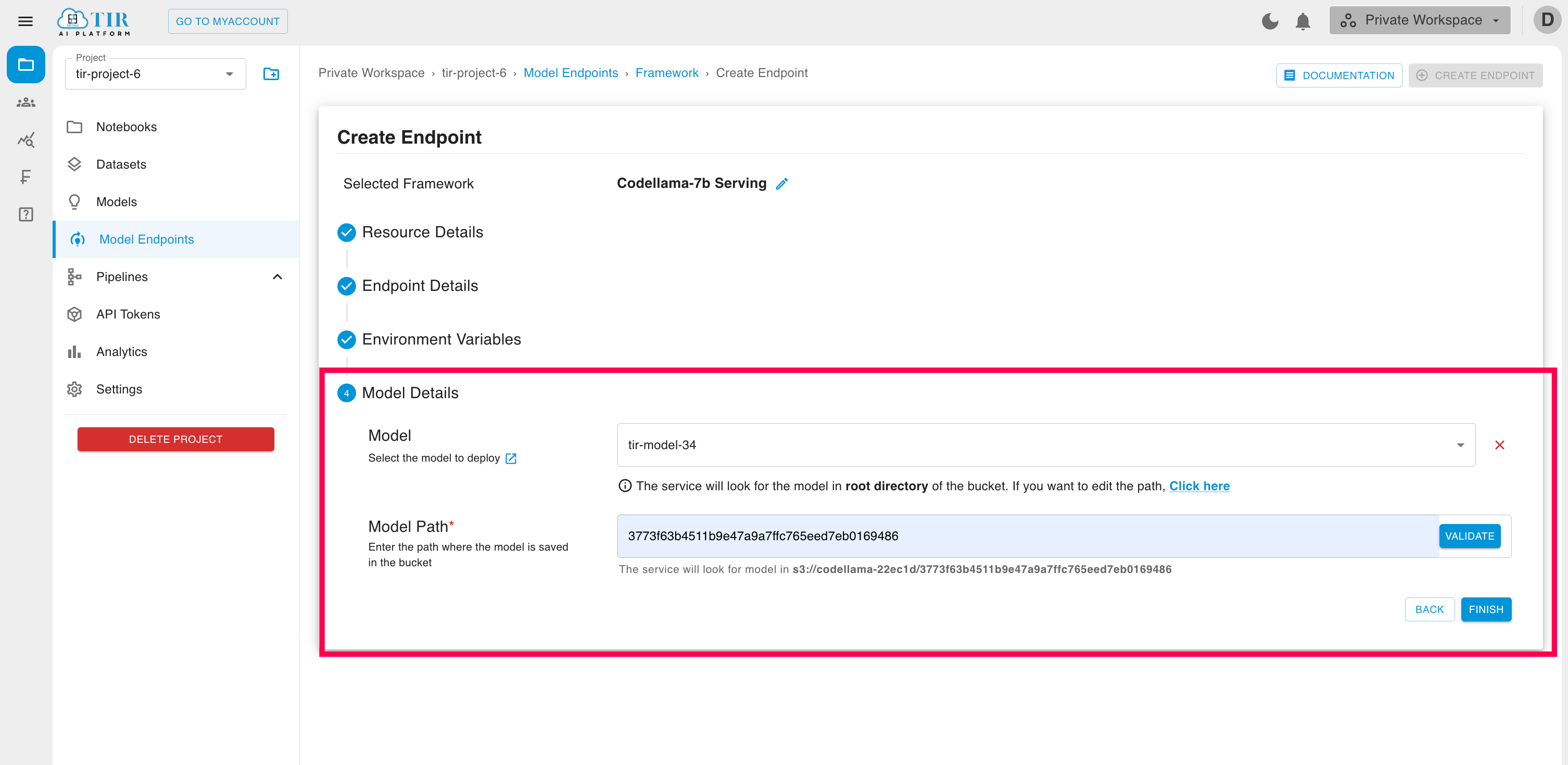
While creating the endpoint, make sure you select the appropriate model in the model details sub-section, i.e., the EOS bucket containing your model weights. If your model is not in the root directory of the bucket, make sure to specify the path where the model is saved in the bucket.
Follow the steps below to find the Model path in the bucket:
Go to MyAccount Object Storage
Find your Model bucket (in this case: codellama-22ec1d) & click on its Objects tab
If the model_index.json file is present in the list of objects, then your model is present in the root directory & you need not give any Model Path
Otherwise, navigate to the folder, and find the model_index.json file, copy its path and paste the same in the Model Path field
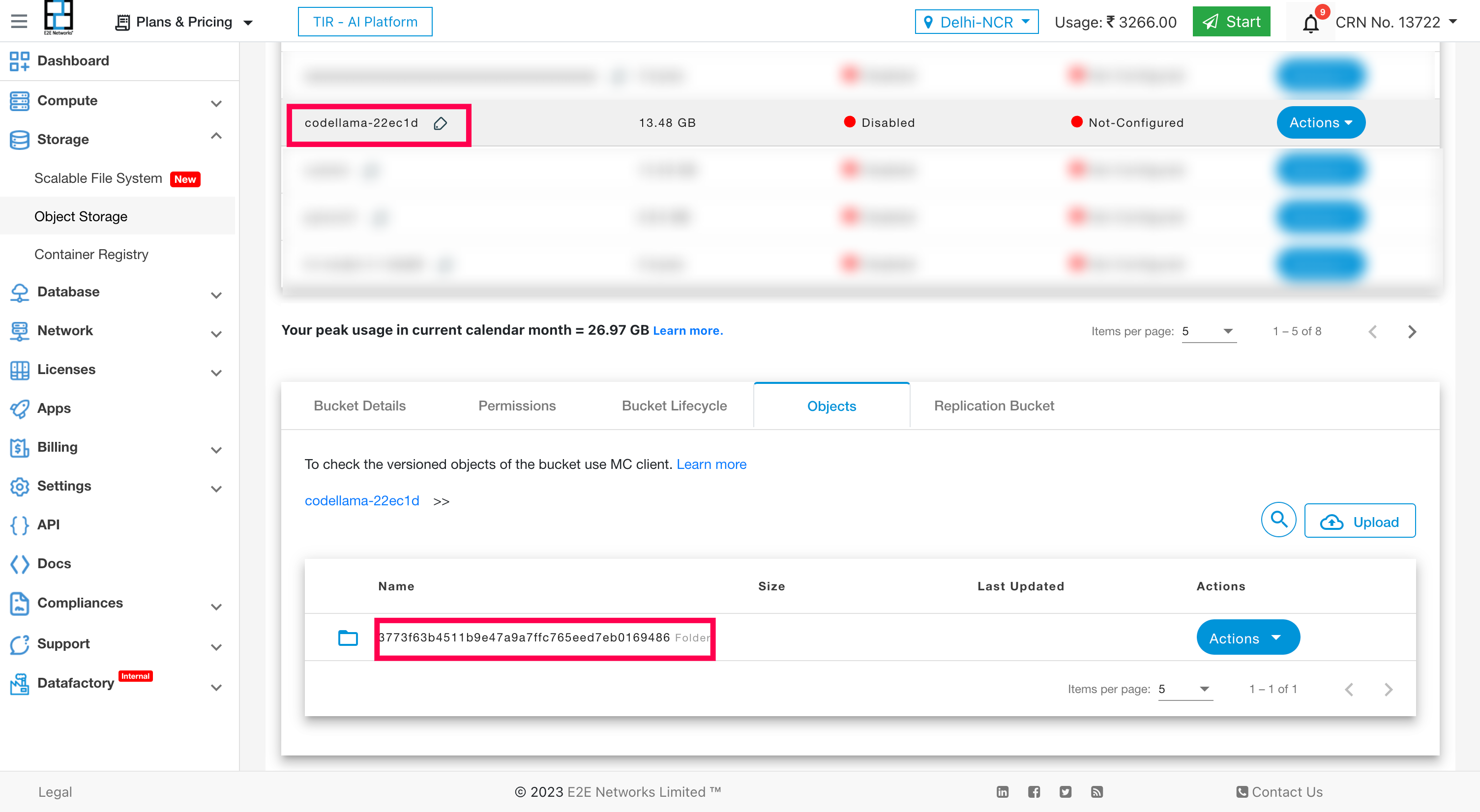
You can click on Validate button to validate the existence of the model at the given path
Step 6 Inferring Request
Head back to the section on A guide on Model Endpoint creation above and follow the steps 3 to infer the endpoint.
You can pass the parameters in your request body listed below to control your output while running inference mentioned in step 3 .
Supported Parameters
Parameters that control the length of the output
max_length (int, optional, defaults to 20) — The maximum length the generated tokens can have. Corresponds to the length of the input prompt + max_new_tokens. Its effect is overridden by max_new_tokens, if also set.
max_new_tokens (int, optional) — The maximum numbers of tokens to generate, ignoring the number of tokens in the prompt.
min_length (int, optional, defaults to 0) — The minimum length of the sequence to be generated. Corresponds to the length of the input prompt + min_new_tokens. Its effect is overridden by min_new_tokens, if also set.
min_new_tokens (int, optional) — The minimum numbers of tokens to generate, ignoring the number of tokens in the prompt.
early_stopping (bool or str, optional, defaults to False) — Controls the stopping condition for beam-based methods, like beam-search. It accepts the following values: True, where the generation stops as soon as there are num_beams complete candidates; False, where an heuristic is applied and the generation stops when is it very unlikely to find better candidates; “never”, where the beam search procedure only stops when there cannot be better candidates (canonical beam search algorithm).
max_time (float, optional) — The maximum amount of time you allow the computation to run for in seconds. generation will still finish the current pass after allocated time has been passed.
Parameters that control the generation strategy used
do_sample (bool, optional, defaults to False) — Whether or not to use sampling ; use greedy decoding otherwise.
num_beams (int, optional, defaults to 1) — Number of beams for beam search. 1 means no beam search.
num_beam_groups (int, optional, defaults to 1) — Number of groups to divide num_beams into in order to ensure diversity among different groups of beams. this paper for more details.
penalty_alpha (float, optional) — The values balance the model confidence and the degeneration penalty in contrastive search decoding.
use_cache (bool, optional, defaults to True) — Whether or not the model should use the past last key/values attentions (if applicable to the model) to speed up decoding.
Parameters for manipulation of the model output logits
temperature (float, optional, defaults to 1.0) — The value used to modulate the next token probabilities.
top_k (int, optional, defaults to 50) — The number of highest probability vocabulary tokens to keep for top-k-filtering.
top_p (float, optional, defaults to 1.0) — If set to float < 1, only the smallest set of most probable tokens with probabilities that add up to top_p or higher are kept for generation.
typical_p (float, optional, defaults to 1.0) — Local typicality measures how similar the conditional probability of predicting a target token next is to the expected conditional probability of predicting a random token next, given the partial text already generated. If set to float < 1, the smallest set of the most locally typical tokens with probabilities that add up to typical_p or higher are kept for generation. See this paper for more details.
epsilon_cutoff (float, optional, defaults to 0.0) — If set to float strictly between 0 and 1, only tokens with a conditional probability greater than epsilon_cutoff will be sampled. In the paper, suggested values range from 3e-4 to 9e-4, depending on the size of the model. See Truncation Sampling as Language Model Desmoothing for more details.
eta_cutoff (float, optional, defaults to 0.0) — Eta sampling is a hybrid of locally typical sampling and epsilon sampling. If set to float strictly between 0 and 1, a token is only considered if it is greater than either eta_cutoff or sqrt(eta_cutoff) * exp(-entropy(softmax(next_token_logits))). The latter term is intuitively the expected next token probability, scaled by sqrt(eta_cutoff). In the paper, suggested values range from 3e-4 to 2e-3, depending on the size of the model. See Truncation Sampling as Language Model Desmoothing for more details.
diversity_penalty (float, optional, defaults to 0.0) — This value is subtracted from a beam’s score if it generates a token same as any beam from other group at a particular time. Note that diversity_penalty is only effective if group beam search is enabled.
repetition_penalty (float, optional, defaults to 1.0) — The parameter for repetition penalty. 1.0 means no penalty. See this paper for more details.
encoder_repetition_penalty (float, optional, defaults to 1.0) — The paramater for encoder_repetition_penalty. An exponential penalty on sequences that are not in the original input. 1.0 means no penalty.
length_penalty (float, optional, defaults to 1.0) — Exponential penalty to the length that is used with beam-based generation. It is applied as an exponent to the sequence length, which in turn is used to divide the score of the sequence. Since the score is the log likelihood of the sequence (i.e. negative), length_penalty > 0.0 promotes longer sequences, while length_penalty < 0.0 encourages shorter sequences.
no_repeat_ngram_size (int, optional, defaults to 0) — If set to int > 0, all ngrams of that size can only occur once.
bad_words_ids (List[List[int]], optional) — List of list of token ids that are not allowed to be generated. Check NoBadWordsLogitsProcessor for further documentation and examples.
force_words_ids (List[List[int]] or List[List[List[int]]], optional) — List of token ids that must be generated. If given a List[List[int]], this is treated as a simple list of words that must be included, the opposite to bad_words_ids. If given List[List[List[int]]], this triggers a disjunctive constraint, where one can allow different forms of each word.
renormalize_logits (bool, optional, defaults to False) — Whether to renormalize the logits after applying all the logits processors or warpers (including the custom ones). It’s highly recommended to set this flag to True as the search algorithms suppose the score logits are normalized but some logit processors or warpers break the normalization.
constraints (List[Constraint], optional) — Custom constraints that can be added to the generation to ensure that the output will contain the use of certain tokens as defined by Constraint objects, in the most sensible way possible.
forced_bos_token_id (int, optional, defaults to model.config.forced_bos_token_id) — The id of the token to force as the first generated token after the decoder_start_token_id. Useful for multilingual models like mBART where the first generated token needs to be the target language token.
forced_eos_token_id (Union[int, List[int]], optional, defaults to model.config.forced_eos_token_id) — The id of the token to force as the last generated token when max_length is reached. Optionally, use a list to set multiple end-of-sequence tokens.
remove_invalid_values (bool, optional, defaults to model.config.remove_invalid_values) — Whether to remove possible nan and inf outputs of the model to prevent the generation method to crash. Note that using remove_invalid_values can slow down generation.
exponential_decay_length_penalty (tuple(int, float), optional) — This Tuple adds an exponentially increasing length penalty, after a certain amount of tokens have been generated. The tuple shall consist of: (start_index, decay_factor) where start_index indicates where penalty starts and decay_factor represents the factor of exponential decay
suppress_tokens (List[int], optional) — A list of tokens that will be suppressed at generation. The SupressTokens logit processor will set their log probs to -inf so that they are not sampled.
begin_suppress_tokens (List[int], optional) — A list of tokens that will be suppressed at the beginning of the generation. The SupressBeginTokens logit processor will set their log probs to -inf so that they are not sampled.
forced_decoder_ids (List[List[int]], optional) — A list of pairs of integers which indicates a mapping from generation indices to token indices that will be forced before sampling. For example, [[1, 123]] means the second generated token will always be a token of index 123.
sequence_bias (Dict[Tuple[int], float], optional)) — Dictionary that maps a sequence of tokens to its bias term. Positive biases increase the odds of the sequence being selected, while negative biases do the opposite. Check SequenceBiasLogitsProcessor for further documentation and examples.
guidance_scale (float, optional) — The guidance scale for classifier free guidance (CFG). CFG is enabled by setting guidance_scale > 1. Higher guidance scale encourages the model to generate samples that are more closely linked to the input prompt, usually at the expense of poorer quality.
low_memory (bool, optional) — Switch to sequential topk for contrastive search to reduce peak memory. Used with contrastive search.
Parameters that define the output variables of `generate`
num_return_sequences (int, optional, defaults to 1) — The number of independently computed returned sequences for each element in the batch.
output_attentions (bool, optional, defaults to False) — Whether or not to return the attentions tensors of all attention layers. See attentions under returned tensors for more details.
output_hidden_states (bool, optional, defaults to False) — Whether or not to return the hidden states of all layers. See hidden_states under returned tensors for more details.
output_scores (bool, optional, defaults to False) — Whether or not to return the prediction scores. See scores under returned tensors for more details.
return_dict_in_generate (bool, optional, defaults to False) — Whether or not to return a ModelOutput instead of a plain tuple.
Special tokens that can be used at generation time
pad_token_id (int, optional) — The id of the padding token.
bos_token_id (int, optional) — The id of the beginning-of-sequence token.
eos_token_id (Union[int, List[int]], optional) — The id of the end-of-sequence token. Optionally, use a list to set multiple end-of-sequence tokens.
Generation parameters exclusive to encoder-decoder models
encoder_no_repeat_ngram_size (int, optional, defaults to 0) — If set to int > 0, all ngrams of that size that occur in the encoder_input_ids cannot occur in the decoder_input_ids.
decoder_start_token_id (int, optional) — If an encoder-decoder model starts decoding with a different token than bos, the id of that token.