Deploy Inference for Gemma
In this tutorial, we will create a model endpoint for Gemma model. Currently, we provide 4 Variants: 2B, 2B-it, 7B, and 7B-it. In this tutorial, we will deploy the model endpoint for 2B-it variant. The same step will work for other variants.
The tutorial will mainly focus on the following:
Model Endpoint creation for Gemma 2B-IT using prebuilt container
When a model endpoint is created in TIR dashboard, in the background a model server is launched to serve the inference requests.
TIR platform supports a variety of model formats through pre-buit containers (e.g. pytorch, triton, llma, mpt etc.).
For the scope of this tutorial, we will use pre-built container (Gemma 2B-IT) for the model endpoint but you may choose to create your own custom container by following this tutorial .
In most cases, the pre-built container would work for your use case. The advantage is you won’t have to worry about building an API handler. API handler will be automatically created for you.
Steps to create inference endpoint for Gemma 2B-IT model:
Step 1: Create a Model Endpoint
Go to TIR AI Platform
Choose a project
- Go to Model Endpoints section
- Create a new Endpoint
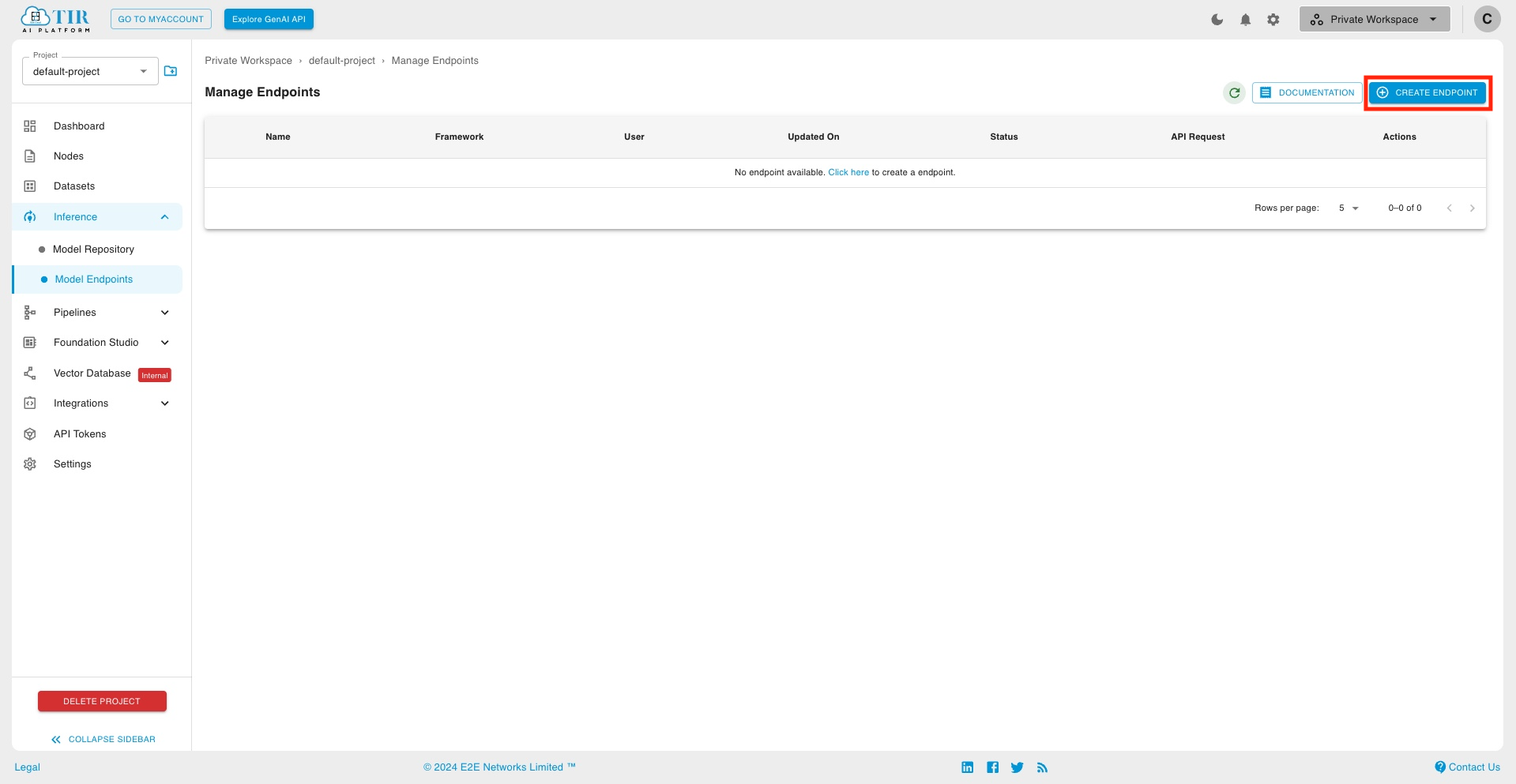
- Choose Gemma 2B-IT model card

Pick a suitable GPU plan of your choice & set the replicas
- Setting Environment Variables
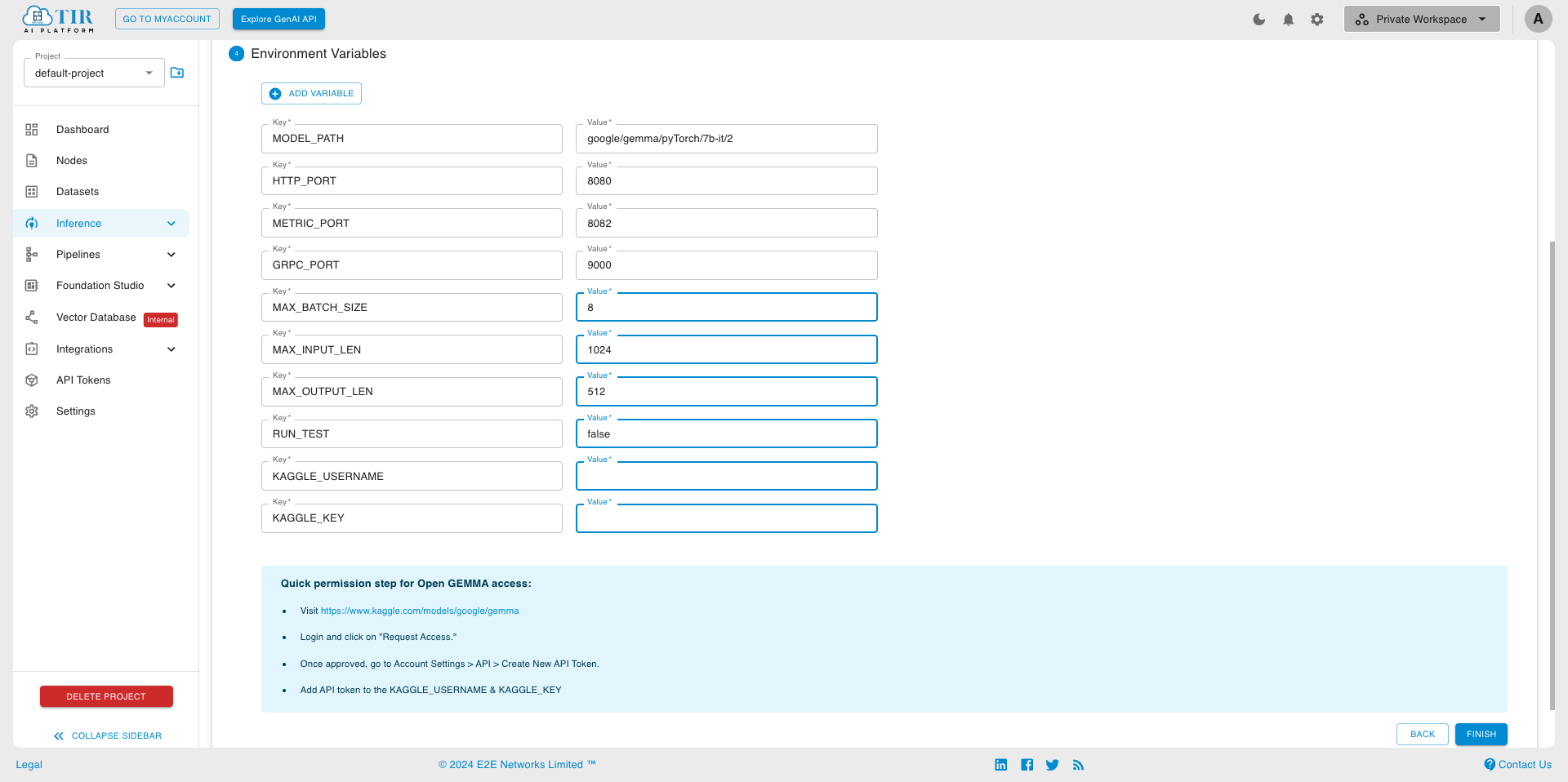
- Compulsory Environment Variables
Note: Gemma is a Gated Model; you will need permission to access it. The model checkpoint will be downloaded from Kaggle. Follow these steps to get access to the model
Login and click on “Request Access.”
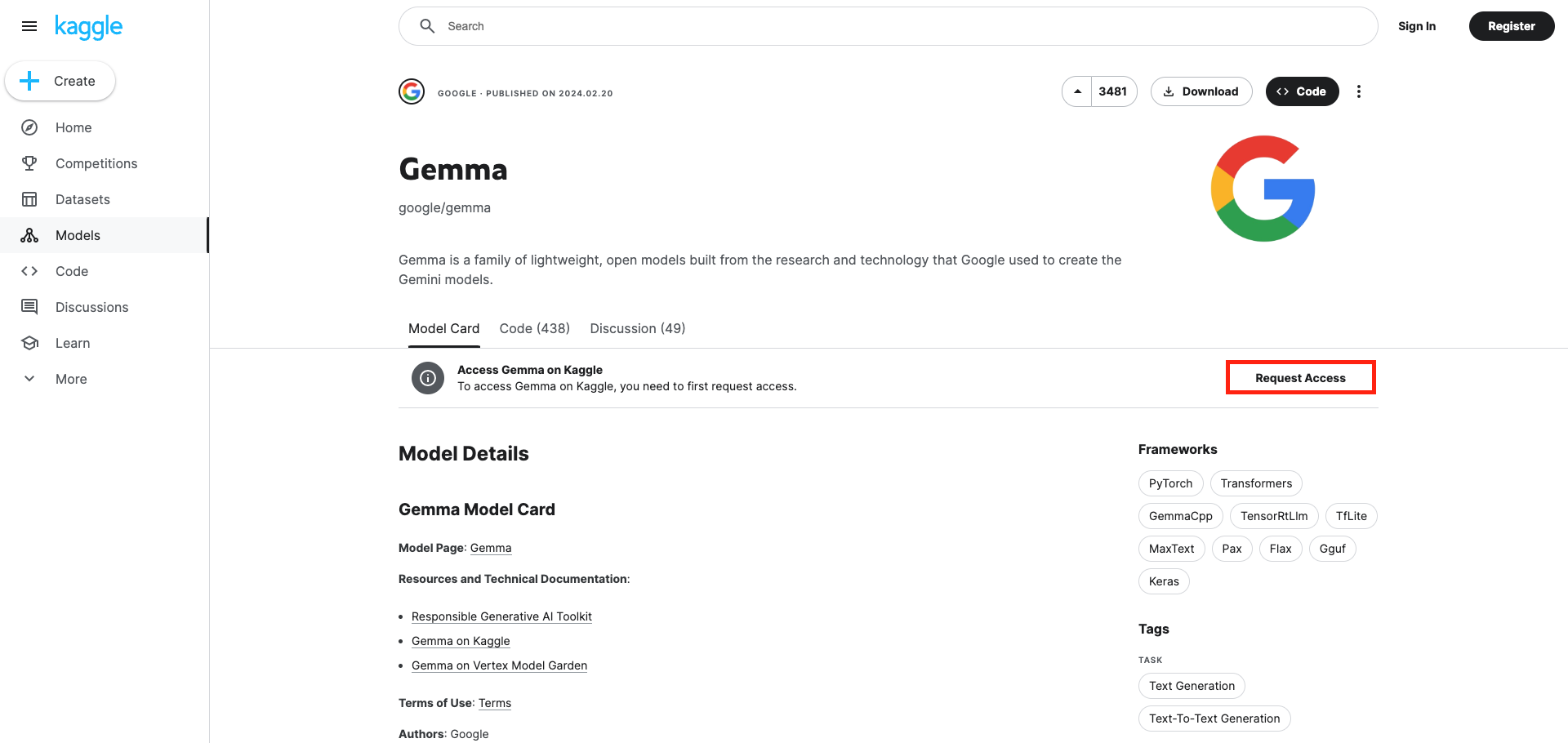
Go to Account Settings > API > Create New API Token once approved.
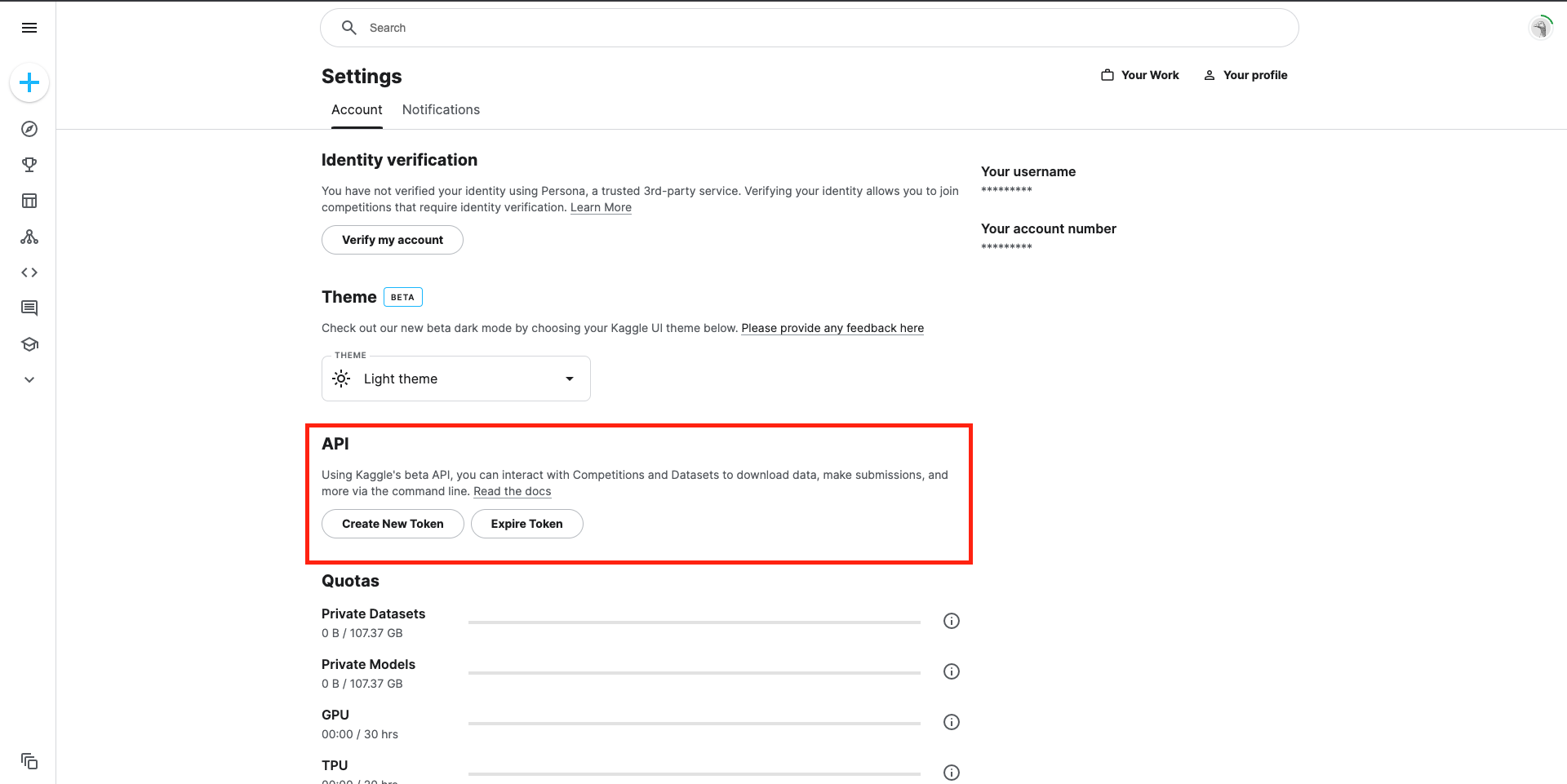
Copy API token key
KAGGLE_KEY: Paste the API token key
KAGGLE_USERNAME: Add kaggle username using which you requested access to Gemma in the previous step
Advanced Environment Variables: We do not recommend modifying these values for general use cases. The value of these parameters largely depends on the GPU you use. These parameters will be used to the server model using the TensorRT-LLM.
MAX_BATCH_SIZE: Denotes the maximum number of input sequences that the model can handle concurrently in a single batch during inference. Smaller values for this parameter mean that fewer input sequences are processed simultaneously. While smaller batch sizes may reduce memory usage and allow for more efficient processing, they may also result in lower throughput and less parallelism, particularly on hardware optimized for larger batch sizes.
MAX_INPUT_LEN: Specifies the maximum length of input sequences that the model can accept during inference. For language models, smaller values for this parameter limit the number of tokens (words or subwords) in the input text that the model can process at once. Limiting the input length can help control memory usage and computation complexity, but it may also lead to information loss if important context is truncated.
MAX_OUTPUT_LEN: Represents the maximum length of output sequences generated by the model. Smaller values for this parameter restrict the length of generated text, potentially preventing overly verbose or irrelevant output. However, overly small values may limit the model’s ability to produce coherent and meaningful responses, particularly for tasks like text generation or completion where longer outputs may be necessary to convey complete thoughts or responses.
Complete the endpoint creation
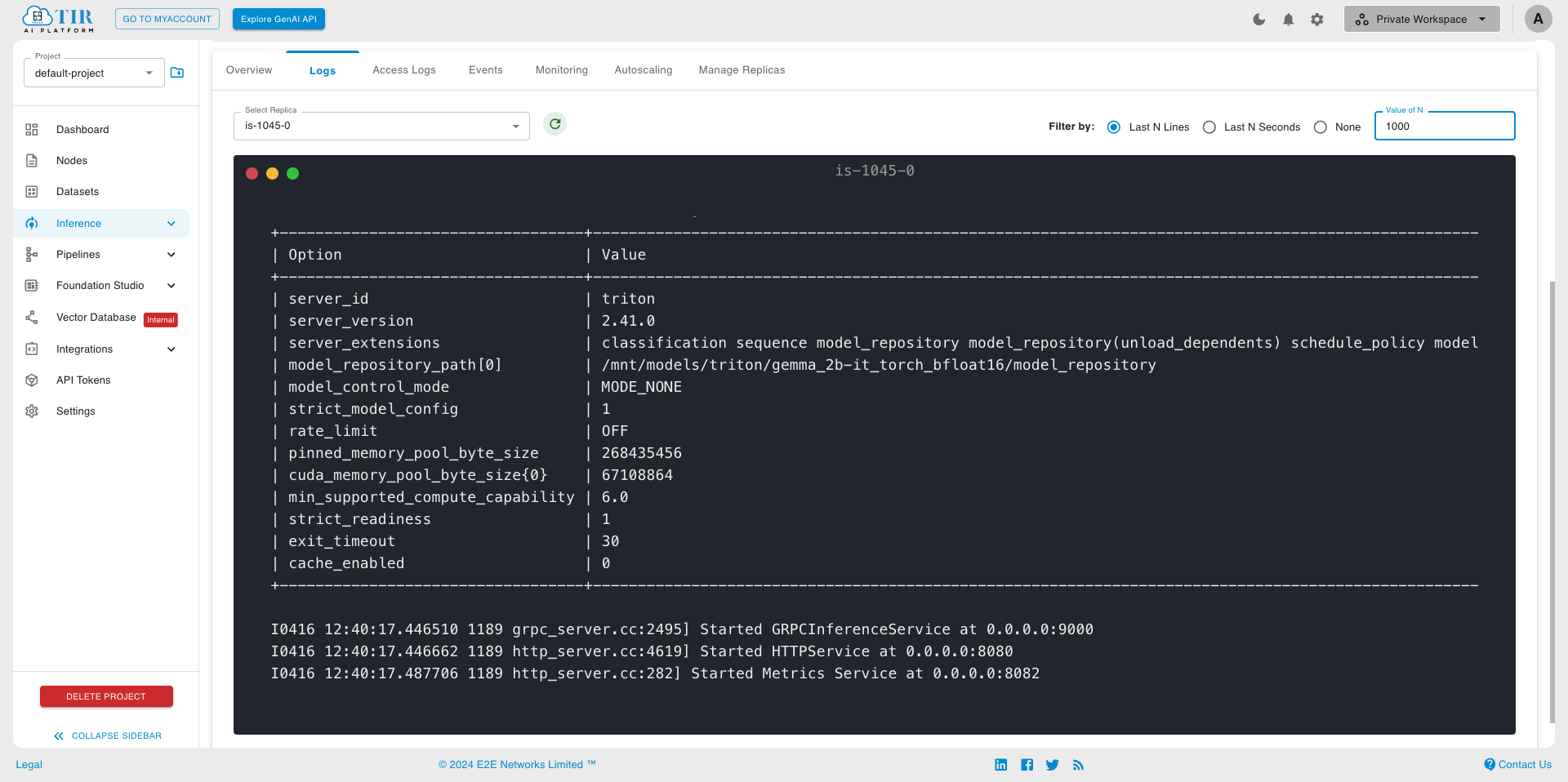
Model creation might take few minutes. Check logs for updates. Once the inference server starts, the log will resemble the image provided below.
Step 2: Generate your API_TOKEN
The model endpoint API requires a valid auth token which you’ll need to perform further steps. So, let’s generate one.
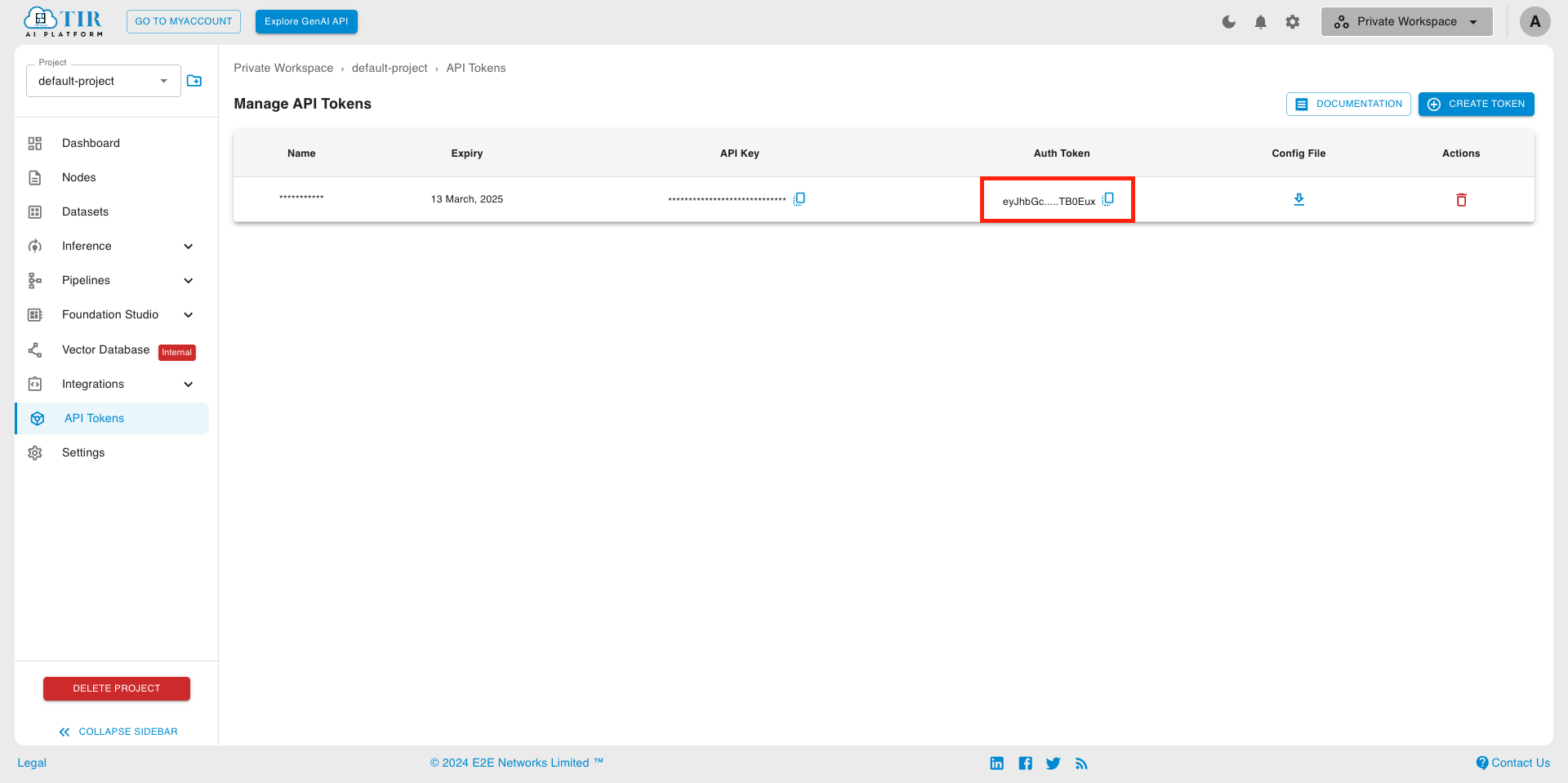
Go to API Tokens section under the project.
Create a new API Token by clicking on the Create Token button on the top right corner. You can also use an existing token, if already created.
Once created, you’ll be able to see the list of API Tokens containing the API Key and Auth Token. You will need this Auth Token in the next step.
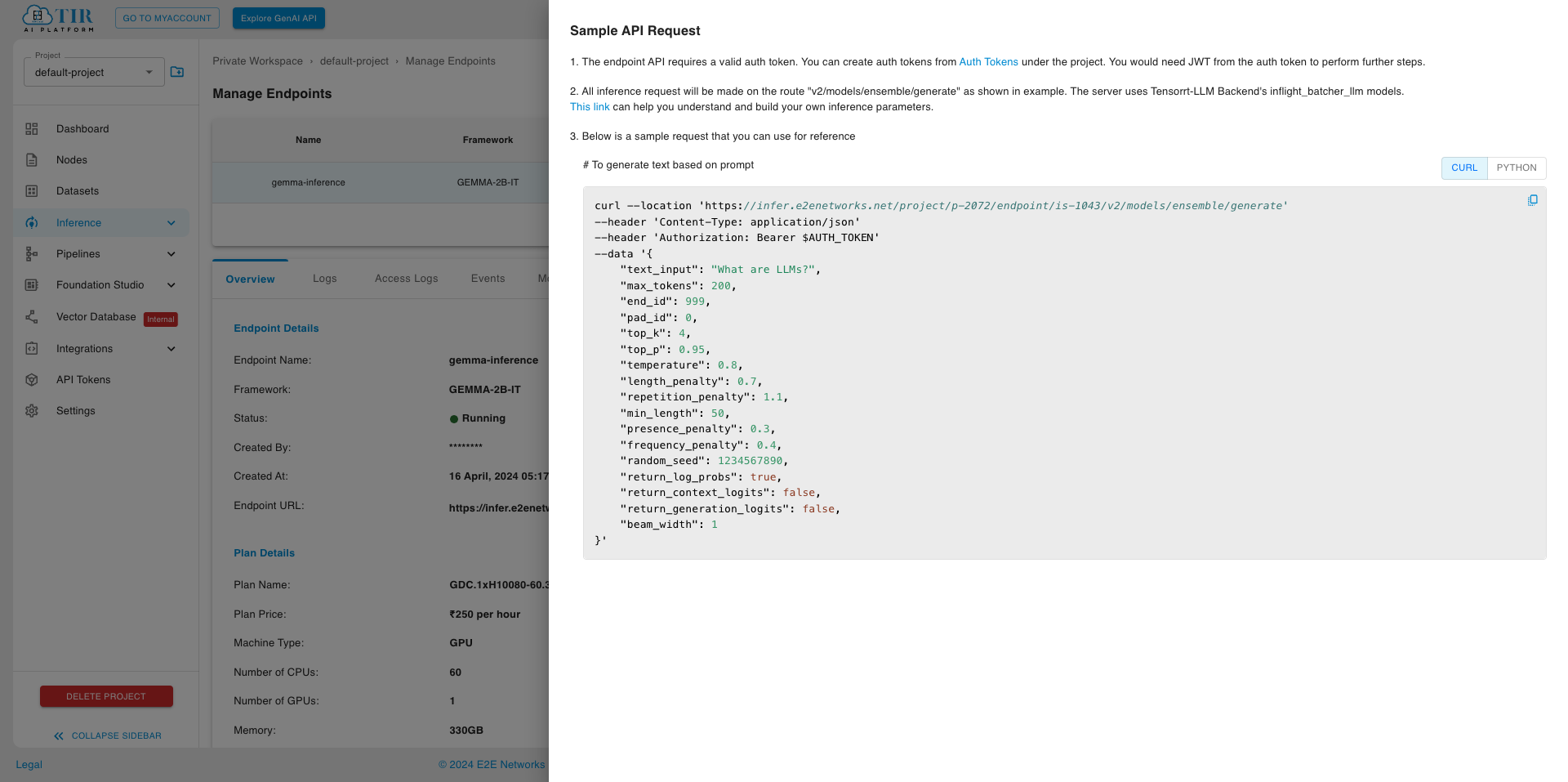
Step 3: Inferring Request
When your endpoint is ready, visit the Sample API request section to test your endpoint using curl.
Supported Parameters
Field |
Description |
Shape |
Data Type |
|---|---|---|---|
text_input |
Input text to be used as a prompt for text generation. |
[-1] |
TYPE_STRING |
max_tokens |
The maximum number of tokens to generate in the output text. |
[-1] |
TYPE_INT32 |
bad_words |
A list of words or phrases that should not appear in the generated text. |
[-1] |
TYPE_STRING |
stop_words |
A list of words that are considered stop words and are excluded from the generation. |
[-1] |
TYPE_STRING |
end_id |
The token ID marking the end of a sequence. |
[1] |
TYPE_INT32 |
pad_id |
The token ID used for padding sequences. |
[1] |
TYPE_INT32 |
top_k |
The number of highest probability vocabulary tokens to consider for generation. |
[1] |
TYPE_INT32 |
top_p |
Nucleus sampling parameter, limiting the cumulative probability of tokens. |
[1] |
TYPE_FP32 |
temperature |
Controls the randomness of token selection during generation. |
[1] |
TYPE_FP32 |
length_penalty |
Penalty applied to the length of the generated text. |
[1] |
TYPE_FP32 |
repetition_penalty |
Penalty applied to repeated sequences in the generated text. |
[1] |
TYPE_FP32 |
min_length |
The minimum number of tokens in the generated text. |
[1] |
TYPE_INT32 |
presence_penalty |
Penalty applied based on the presence of specific tokens in the generated text. |
[1] |
TYPE_FP32 |
frequency_penalty |
Penalty applied based on the frequency of tokens in the generated text. |
[1] |
TYPE_FP32 |
random_seed |
Seed for controlling the randomness of generation. |
[1] |
TYPE_UINT64 |
return_log_probs |
Whether to return log probabilities for each token. |
[1] |
TYPE_BOOL |
return_context_logits |
Whether to return logits for each token in the context. |
[1] |
TYPE_BOOL |
return_generation_logits |
Whether to return logits for each token in the generated text. |
[1] |
TYPE_BOOL |
prompt_embedding_table |
Table of embeddings for words in the prompt. |
[-1, -1] |
TYPE_FP16 |
prompt_vocab_size |
Size of the vocabulary for prompt embeddings. |
[1] |
TYPE_INT32 |
embedding_bias_words |
Words to bias the word embeddings. |
[-1] |
TYPE_STRING |
embedding_bias_weights |
Weights for the biasing of word embeddings. |
[-1] |
TYPE_FP32 |
cum_log_probs |
Cumulative log probabilities of generated tokens. |
[-1] |
TYPE_FP32 |
output_log_probs |
Log probabilities of each token in the generated text. |
[-1, -1] |
TYPE_FP32 |
context_logits |
Logits for each token in the context. |
[-1, -1] |
TYPE_FP32 |
generation_logits |
Logits for each token in the generated text. |
[-1, -1, -1] |
TYPE_FP32 |