Deploy Model Endpoint for Stable Diffusion v2.1
In this tutorial, we will create a model endpoint against Stability AI’s Stable Diffusion v2.1 model.
The tutorial will mainly focus on the following:
A step-by-step guide on Model Endpoint creation & Image generation using Stable Diffusion v2.1
Brief description about the supported parameters for image generation
For the scope of this tutorial, we will use pre-built container (Stable-Diffusion v2.1) for the model endpoint but you may choose to create your own custom container by following this tutorial .
In most cases, the pre-built container would work for your use case. The advantage is - you won’t have to worry about building an API handler. API handler will be automatically created for you.
So let’s get started!
A guide on Model Endpoint creation & Image generation
Step 1: Create a Model Endpoint for Stable Diffusion v2.1 on TIR
Go to TIR AI Platform
Choose a project
Go to Model Endpoints section
Click on Create Endpoint button on the top-right corner
Choose Stable-Diffusion v2.1 model card in the Choose Framework section
Pick any suitable GPU plan of your choice. You can proceed with the default values for replicas, disk-size & endpoint details.
Add your environment variables, if any. Else, proceed further
Model Details: For now, we will skip the model details and continue with the default model weights.
If you wish to load your custom model weights (fine-tuned or not), select the appropriate model. (See Creating Model endpoint with custom model weights section below)
Complete the endpoint creation
Step 2: Generate your API TOKEN
The model endpoint API requires a valid auth token which you’ll need to perform further steps. So, let’s generate one.
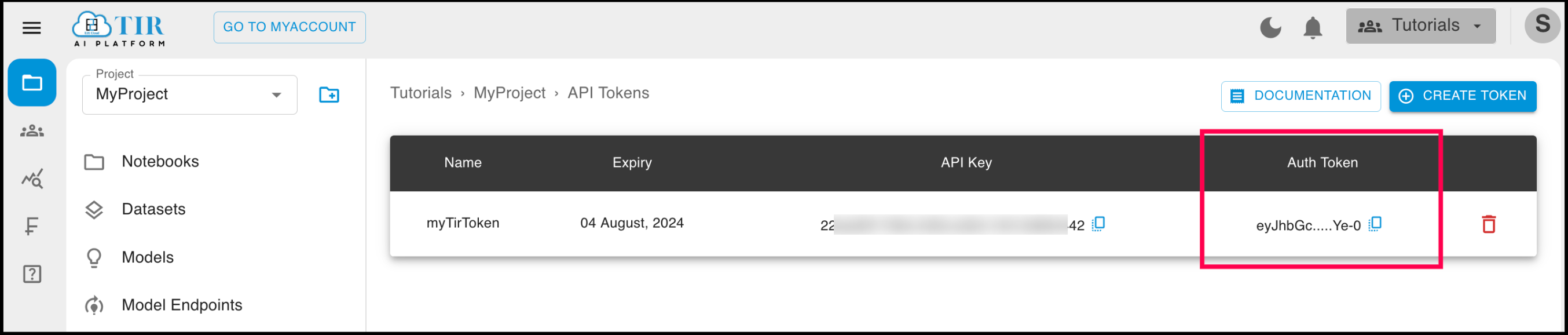
Go to API Tokens section under the project.
Create a new API Token by clicking on the Create Token button on the top right corner. You can also use an existing token, if already created.
Once created, you’ll be able to see the list of API Tokens containing the API Key and Auth Token. You will need this Auth Token in the next step.
Step 3: Generate Images using text Prompts
The final step is to send API requests to the created model endpoint & generate images using text prompts. We will use TIR Notebook to do the same.
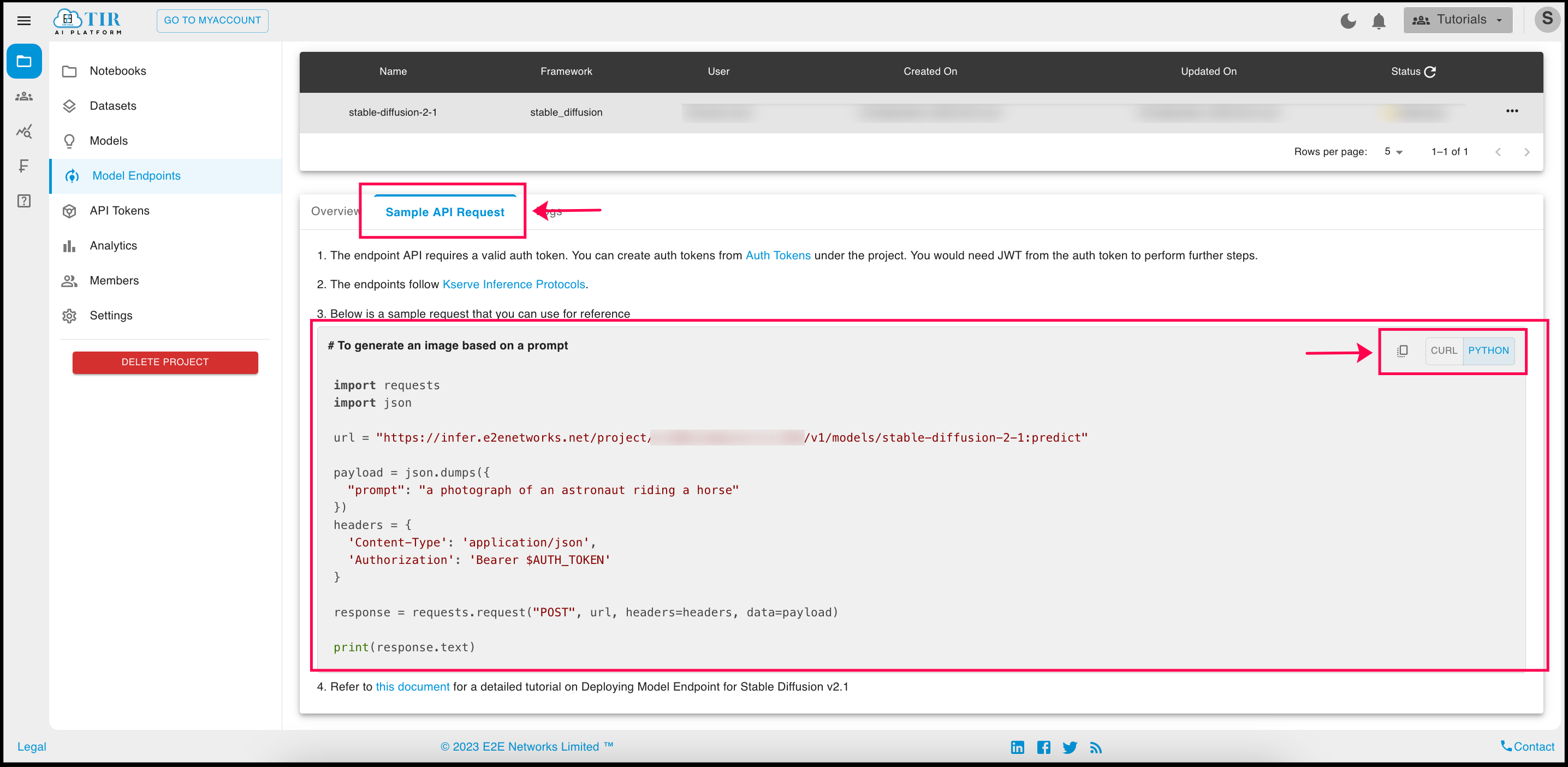
Once your model is Ready, visit the Sample API Request section of that model and copy the Python code
Launch a TIR Notebook with PyTorch or StableDiffusion Image with any basic machine plan. Once it is in Running state, launch it, and start a new notebook untitled.ipynb in the jupyter labs
Paste the Sample API Request code (for Python) in the notebook cell
Copy the Auth Token generated in Step-2 & use it in place of $AUTH_TOKEN in the Sample API Request
Execute the code & send request
You’ll get a list of tensors as output. This is because Stable Diffusion v2.1 model endpoint return the generated images as a list of PyTorch Tensors.
To view the generated images, copy the below code, paste it in the notebook cell and execute it. You’ll be able to view the generated images.
import torch import torchvision.transforms as transforms def display_images(tensor_image_data_list): '''convert PyTorch Tensors to PIL Image''' for tensor_data in tensor_image_data_list: tensor_image = torch.tensor(tensor_data.get("data")) # initialise the tensor pil_img = transforms.ToPILImage()(tensor_image) # convert to PIL Image pil_img.show() # to save the generated_images, uncomment the line below # image.save(tensor_data.get("name")) if response.status_code == 200: display_images(response.json().get("predictions"))
That’s it! Your Stable Diffusion model endpoint is up & running!
You can also try providing different prompts & see the generated images. Besides prompt, the model also supports various other parameters for image generation. See the Supported parameters for image generation section below.
Creating Model endpoint with custom model weights
To create Inference against Stable Diffusion v2.1 model with custom model weights, we will:
Download Stable-Diffusion-2-1 (by Stability AI) model from huggingface
Upload the model to Model Bucket (EOS)
Create an inference endpoint (model endpoint) in TIR to serve API requests
Step 1.1: Define a model in TIR Dashboard
Before we proceed with downloading or fine-tuning (optional) the model weights, let us first define a model in TIR dashboard.
Go to TIR AI Platform
Choose a project
Go to Model section
Click on Create Model
Enter a model name of your choosing (e.g. stable-diffusion)
Select Model Type as Custom
Click on CREATE
You will now see details of EOS (E2E Object Storage) bucket created for this model.
EOS Provides a S3 compatible API to upload or download content. We will be using MinIO CLI in this tutorial.
Copy the Setup Host command from Setup Minio CLI tab to a notepad or leave it in the clipboard. We will soon use it to setup MinIO CLI
Note
In case you forget to copy the setup host command for MinIO CLI, don’t worry. You can always go back to model details and get it again.
Step 1.2: Start a new Notebook
To work with the model weights, we will need to first download them to a local machine or a notebook instance.
In TIR Dashboard, Go to Notebooks
Launch a new Notebook with Diffusers Image and a hardware plan (e.g. A10080). We recommand a GPU plan if you plan to test or fine-tune the model.
Click on the Notebook name or Launch Notebook option to start jupyter labs environment
In the jupyter labs, Click New Launcher and Select Terminal
Now, paste and run the command for setting up MinIO CLI Host from Step 1
If the command works, you will have mc cli ready for uploading our model
Step 1.3: Download the Stable-Diffusion v2.1 (by Stability AI) model from notebook
Now, our EOS bucket will store the model weights. Let us download the weights from Hugging face.
Start a new notebook untitled.ipynb in jupyter labs
Run the below commands. The model will be downloaded by huggingface sdk in the $HOME/.cache folder
import torch from diffusers import StableDiffusionPipeline, DPMSolverMultistepScheduler model_id = "stabilityai/stable-diffusion-2-1" pipe = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16) pipe.scheduler = DPMSolverMultistepScheduler.from_config(pipe.scheduler.config) torch_device = "cuda" if torch.cuda.is_available() else "cpu" pipe = pipe.to(torch_device)Note
If you face any issues running above code in the notebook cell, you may be missing required libraries. This may happen if you did not launch the notebook with Diffusers image. In such situation, you can install the required libraries below:
pip install diffusers transformers accelerate scipy safetensorsLet us run a simple inference to test the model.
prompt = "a photograph of an astronaut riding a horse" image = pipe(prompt).images[0] image.show()
Step 2: Upload the model to Model Bucket (EOS)
Now that the model works as expected, you can fine-tune it with your own data or choose to serve the model as-is. This tutorial assumes you are uploading the model as-is to create inference endpoint. In case you fine-tune the model, you can follow similar steps to upload the model to EOS bucket.
# go to the directory that has the huggingface model code.
cd $HOME/.cache/huggingface/hub/models--stabilityai--stable-diffusion-2-1/snapshots
# push the contents of the folder to EOS bucket.
# Go to TIR Dashboard >> Models >> Select your model >> Copy the cp command from **Setup MinIO CLI** tab.
# The copy command would look like this:
# mc cp -r <MODEL_NAME> stable-diffusion/stable-diffusion-854588
# here we replace <MODEL_NAME> with '*' to upload all contents of snapshots folder
mc cp -r * stable-diffusion/stable-diffusion-854588
Note
The model directory name may be a little different (we assume it is models–stabilityai–stable-diffusion-2-1). In case, this command does not work, list the directories in the below path to identify the model directory
$HOME/.cache/huggingface/hub
Step 3: Create an endpoint for our model
With model weights uploaded to TIR Model’s EOS Bucket, what remains is to just launch the endpoint and serve API requests.
Head back to the section on A guide on Model Endpoint creation & Image generation above and follow the steps to create the endpoint for your model.
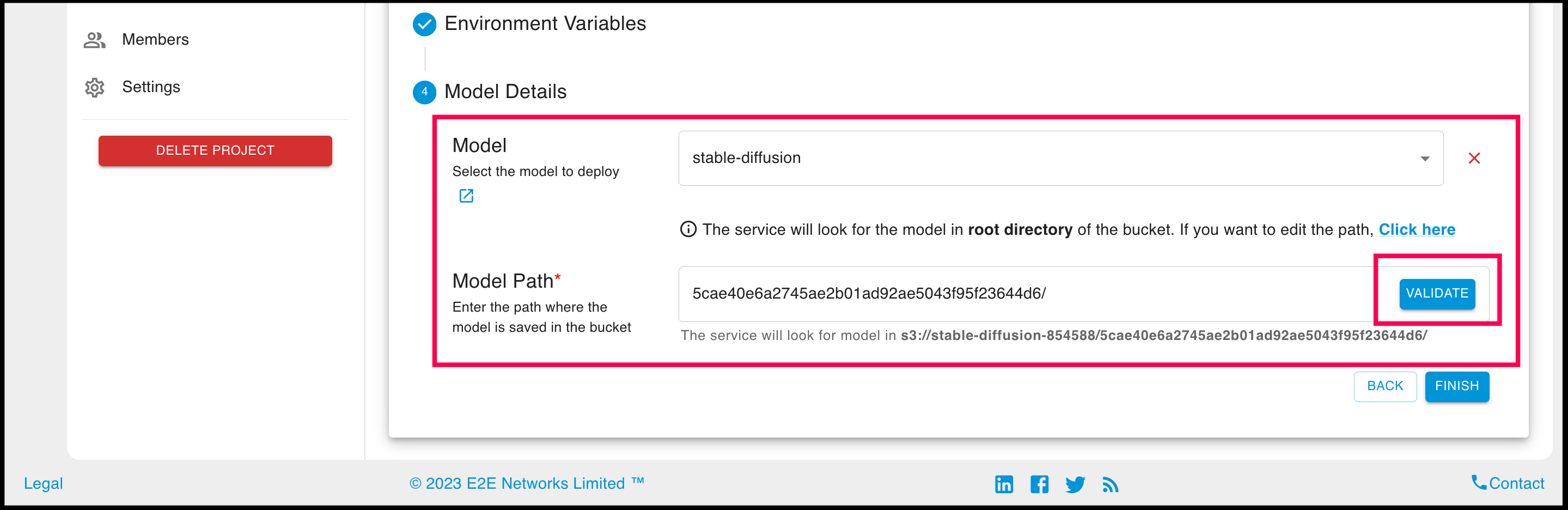
While creating the endpoint, make sure you select the appropriate model in the model details sub-section, i.e., the EOS bucket containing your model weights. If your model is not in the root directory of the bucket, make sure to specify the path where the model is saved in the bucket.
Follow the steps below to find the Model path in the bucket:
Go to MyAccount Object Storage
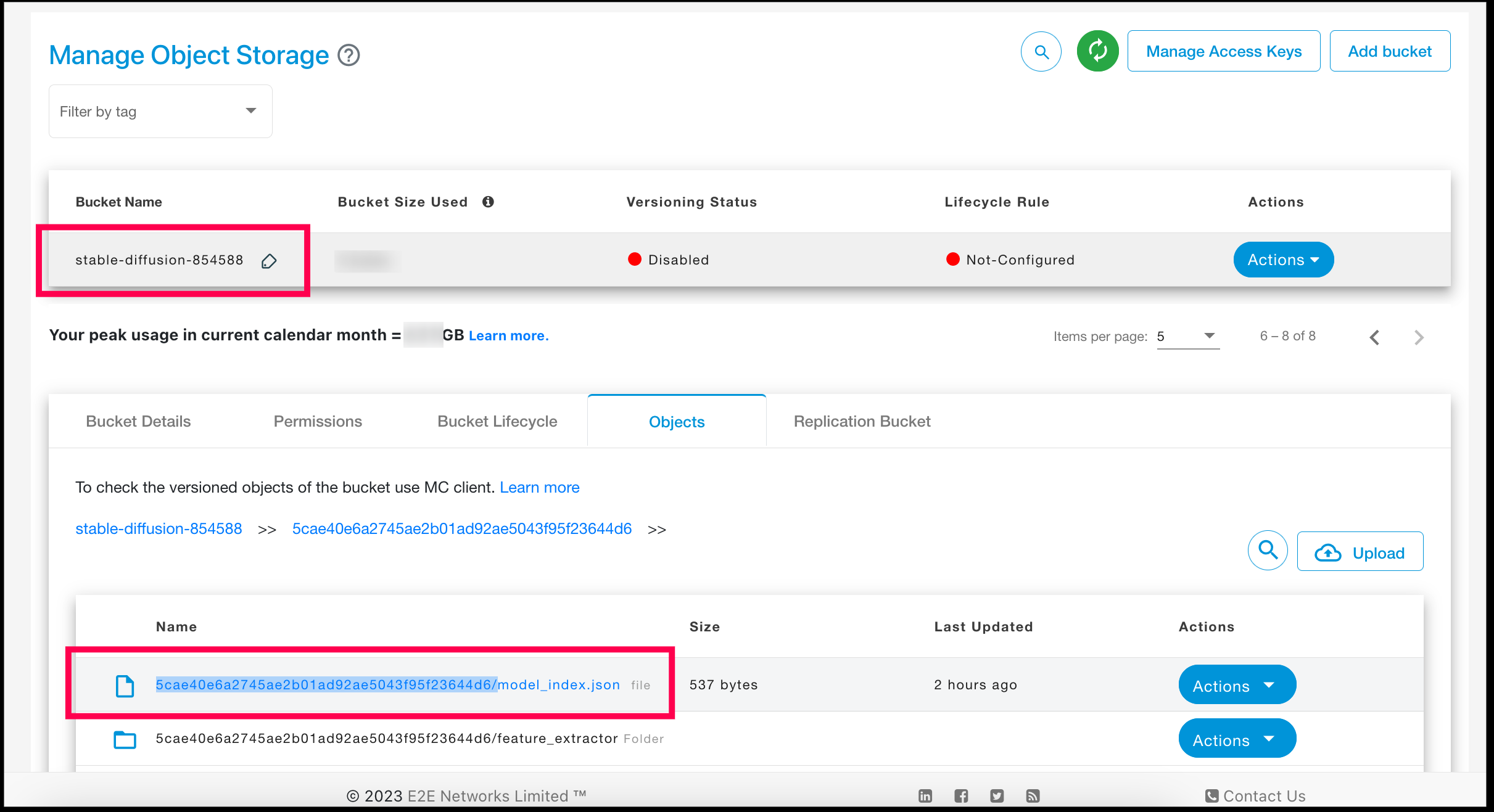
Find your Model bucket (in this case: stable-diffusion-854588) & click on its Objects tab
If the model_index.json file is present in the list of objects, then your model is present in the root directory & you need not give any Model Path
Otherwise, navigate to the folder, and find the model_index.json file, copy its path and paste the same in the Model Path field
You can click on Validate button to validate the existance of the model at the given path
Supported parameters for image generation
In addition to the prompt input, the model supports some other optional parameters that you can pass in request payload to generate images. Below is a brief description about the supported parameters:
prompt (str or List[str], required) — The prompt or prompts to guide image generation.
Sample Payload:
# to give a single prompt
payload_1 = {
"prompt": "a photo of an astronaut riding a horse",
# can also be passed as a list: ["a photo of an astronaut riding a horse"]
}
# to give multiple prompts
payload_2 = {
"prompt": [
"a photo of an astronaut riding a horse",
"a photo of cat playing football"
],
}
height/width (int, optional, defaults to 768) — The height/width in pixels of the generated image/images.
Sample Payload:
# heigth & width
# To choose a good image size, enter height & width in multiples of 8
payload = {
"prompt": "a photo of an astronaut riding a horse",
"height": 512, # defaults to 768
"width": 1024, # defaults to 768
}
num_images_per_prompt (int, optional, defaults to 1) — The number of images to generate per prompt.
Sample Payload:
# num_images_per_prompt
payload = {
"prompt": [
"a photo of an astronaut riding a horse",
"a photo of cat playing football"
],
"num_images_per_prompt": 2 # generates a total of 4 images, 2 for each prompt
}
generator (List[int], optional) — A random seed to make generation deterministic. Every time you use the same seed you’ll have the same image result.
Sample Payload:
# generator
# generator must be a list of integers.
payload_1 = {
"prompt": "a photo of an astronaut riding a horse",
"generator": [1024]
}
# if specified, you must pass a generator value for each of the prompts so that
# length of the generator list equals the total number of prompts.
payload_2 = {
"prompt": [
"a photo of an astronaut riding a horse",
"a photo of cat playing football"
],
"generator": [1024, 700]
}
# you'll see that payload_1 & payload_2 generates the same image for the prompt "a photo of an astronaut riding a horse" because of the same generator seed given
num_inference_steps (int, optional, defaults to 50) — The number of denoising steps. More denoising steps usually lead to a higher quality image at the expense of slower inference.
Sample Payload:
# num_inference_steps
# try generating the images for the three payloads, and see the difference between them.
# we will pass the same prompt and generator_seed to generate the same image for our comparison
prompt_str = "a photo of an astronaut riding a horse"
generator_seed = 2000
payload_1 = {
"prompt": prompt_str,
"generator": [generator_seed],
"num_inference_steps": 20
}
payload_2 = {
"prompt": prompt_str,
"generator": [generator_seed],
"num_inference_steps": 50 # default value
}
payload_3 = {
"prompt": prompt_str,
"generator": [generator_seed],
"num_inference_steps": 80
}
negative_prompt (str or List[str], optional) — The prompt or prompts to guide what to not include in image generation. If not defined, you need to pass negative_prompt_embeds instead. Ignored when not using guidance (guidance_scale < 1).
Sample Payload:
# negative_prompt
# let's generate the same image, but add a negative prompt for the horse's body colour
payload = {
"prompt": "a photo of an astronaut riding a horse",
"generator": [2000],
"negative_prompt": "brown coloured horse"
}
guidance_scale (float, optional, defaults to 7.5) — A higher guidance scale value encourages the model to generate images closely linked to the text prompt at the expense of lower image quality. Guidance scale is enabled when guidance_scale > 1.
Sample Payload:
# guidance_scale
# try generating the images for the three payloads, and see the difference between them.
# we will pass the same prompt and generator_seed to generate the same image for our comparison
prompt_str = "a photo of an astronaut riding a horse"
generator_seed = 2000
payload_1 = {
"prompt": prompt_str,
"generator": [generator_seed],
"guidance_scale": 3
}
payload_2 = {
"prompt": prompt_str,
"generator": [generator_seed],
"guidance_scale": 7.5 # default value
}
payload_3 = {
"prompt": prompt_str,
"generator": [generator_seed],
"guidance_scale": 11
}
guidance_rescale (float, optional, defaults to 0.7) — Guidance rescale factor from Common Diffusion Noise Schedules and Sample Steps are Flawed. Guidance rescale factor should fix overexposure when using zero terminal SNR.
Sample Payload:
# guidance_rescale
# try generating the images for the three payloads, and see the difference between them.
# we will pass the same prompt and generator_seed to generate the same image for our comparison
prompt_str = "a photo of an astronaut riding a horse"
generator_seed = 2000
payload_1 = {
"prompt": prompt_str,
"generator": [generator_seed],
"guidance_rescale": 0.3
}
payload_2 = {
"prompt": prompt_str,
"generator": [generator_seed],
"guidance_rescale": 0.7 # default value
}
payload_3 = {
"prompt": prompt_str,
"generator": [generator_seed],
"guidance_rescale": 1.1
}