Apache Kafka
Introduction
Kafka is a distributed event streaming platform that is used for building real-time data pipelines and streaming applications. Kafka is designed to handle large volumes of data in a scalable and fault-tolerant manner, making it ideal for use cases such as real-time analytics, data ingestion, and event-driven architectures.
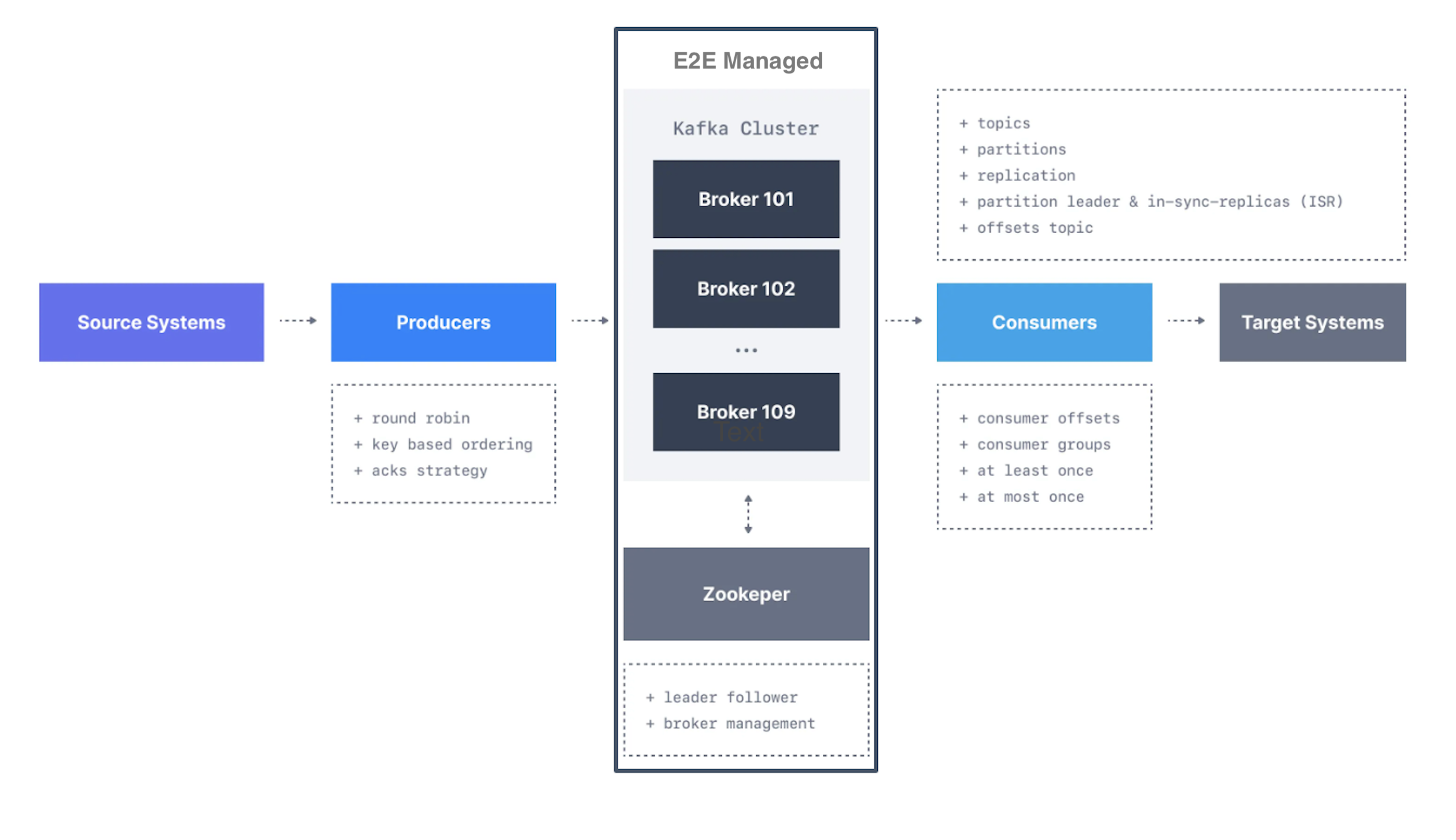
At its core, Kafka is a distributed publisher-subscriber model . Data is written to Kafka topics by producers and consumed from those topics by consumers. Kafka topics can be partitioned, enabling the parallel processing of data, and topics can be replicated across multiple brokers for fault tolerance.
Key Features:
Scalability : Kafka’s partitioned log model allows data to be distributed across multiple brokers (servers) , making it scalable beyond what would fit on a single brokers (servers).
Fast : Kafka decouples data streams so there is very low latency, making it extremely fast.
Durability : Partitions are distributed and replicated across many servers, and the data is all written to disk. This helps protect against server failure, making the data very fault-tolerant and durable.
Step-by-step guide to building a Python client application for Kafka.