NVIDIA A30
NVIDIA A30 Tensor Core GPU is the most versatile mainstream compute GPU for AI inference and enterprise workloads. TF32 and FP64 Tensor Cores with Multi-instance GPU (MIG) combine with fast memory bandwidth in a low-power envelope. Built for inference at scale, it can retrain AI models to fine-tune them, and accelerate HPC applications, delivering maximum value for mainstream enterprises.
Reference:- https://www.nvidia.com/en-in/data-center/products/a30-gpu/
NVIDIA A30 Architectural Innovations
Third-Generation NVIDIA Tensor Core: Performance and Versatility
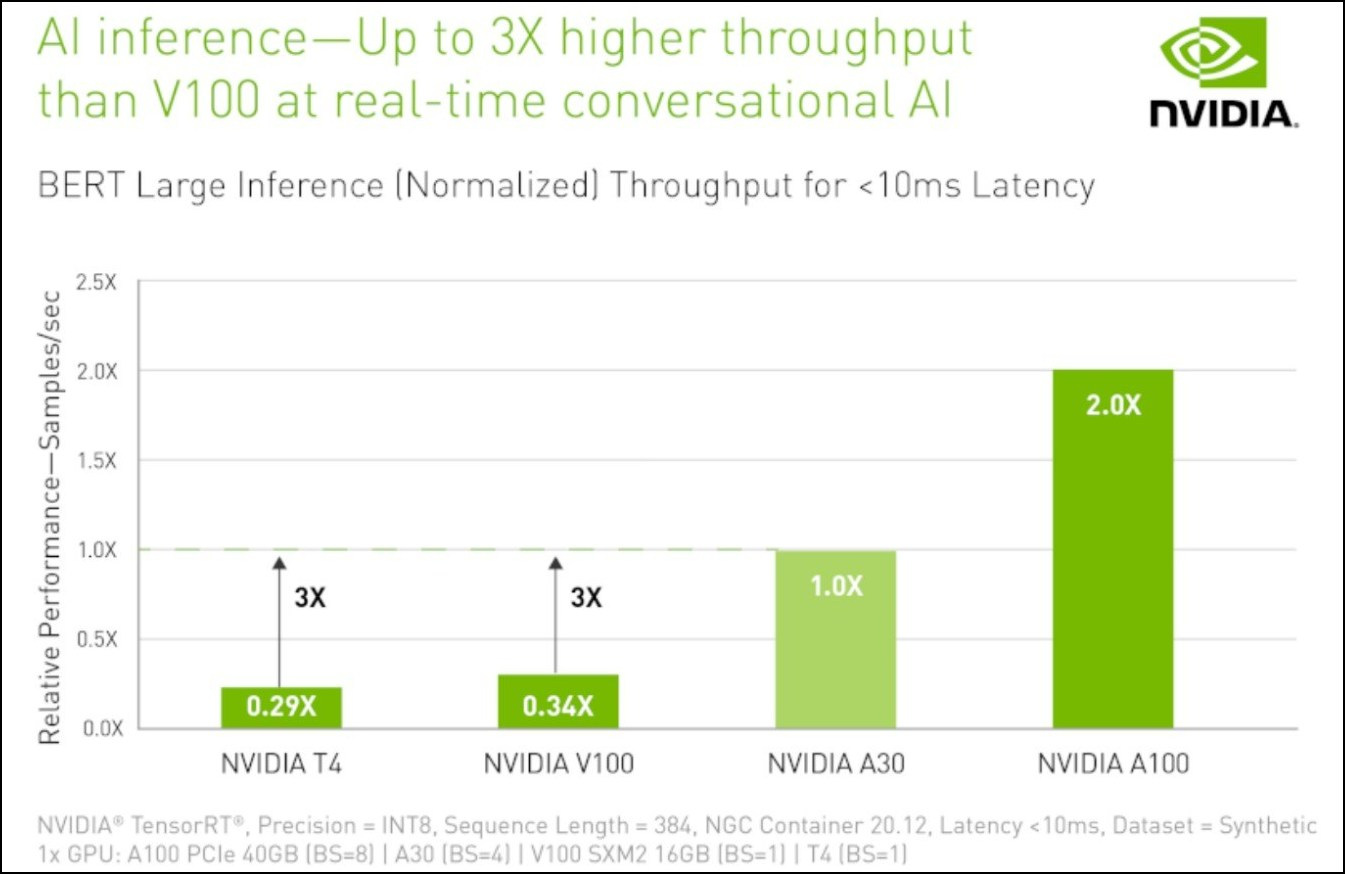
Compared to the NVIDIA T4 Tensor Core GPU, the third-generation Tensor Cores on NVIDIA A30 deliver over 20X more AI training throughput using TF32 without any code changes and over 5X more inference performance. In addition, A30 adds BFLOAT16 to support a full range of AI precisions. NDA CONFIDENTIAL 3 For HPC, Tensor Cores also add 10.3 teraFLOPS of FP64 performance, a nearly 30 percent increase over the prior NVIDIA V100 Tensor Core GPU.
TF32: Higher Performance for AI Training, Zero Code Changes
As AI networks and datasets continue to expand exponentially, their computing appetite is similarly growing. Mixed-precision math has brought huge performance speedups, but they’ve historically required minor code changes. A30 supports a new precision, TF32, which works just like FP32 while providing 11X higher floating operations per second (FLOPS) over the prior-generation V100 for AI without requiring any code changes. It’s also the default in major AI frameworks as well as containers on NGC™. And NVIDIA’s automatic mixed precision (AMP) feature enables a further 2X boost to performance with just one additional line of code using FP16 precision. A30 Tensor Cores also include support for BFLOAT16, INT8, and INT4 precision, making A30 an incredibly versatile accelerator for both AI training and inference.
Double-Precision Tensor Cores: The Biggest Milestone Since FP64 for HPC
A30 brings the power of Tensor Cores to HPC, providing the biggest milestone since the introduction of double-precision GPU computing for HPC. The third generation of Tensor Cores in A30 enables matrix operations in full, IEEE-compliant, FP64 precision. Through enhancements in NVIDIA CUDA-X™ math libraries, a range of HPC applications that need double-precision math can now see boosts of up to 30 percent in performance and efficiency compared to prior generations of GPUs.
** Multi-Instance GPU: Multiple Accelerators in One GPU**
Every AI and HPC application can benefit from acceleration, but not every application needs the performance of a full A30 GPU. With Multi-Instance GPU (MIG), each A30 can be partitioned into as many as four GPU instances, fully isolated at the hardware level with their own high-bandwidth memory, cache, and compute cores. Now, developers can access breakthrough acceleration for all their applications, big and small, and get guaranteed quality of service. And IT administrators can offer right-sized GPU acceleration for optimal utilization and expand access to every user and application. MIG NDA CONFIDENTIAL 4 works on NVIDIA AI Enterprise with VMware vSphere and NVIDIA Virtual Compute Server (vCS) with hypervisors such as Red Hat RHEL/RHV.
PCIe Gen 4: Double the Bandwidth and NVLINK Between GPU pairs
A30 supports PCIe Gen 4, which doubles the bandwidth of PCIe Gen 3 from 15.75 gigabytes per second (GB/sec) to 31.5 GB/sec, improving data transfer speeds from CPU memory for data-intensive tasks and datasets. For additional communication bandwidth, A30 supports NVIDIA® NVLink® between pairs of GPUs, which provides data transfer rates up to 200GB/sec.
- 24GB of GPU Memory
A30 features 24GB of HBM2 memory with 933GB/s of memory bandwidth, delivering 1.5X more memory and 3X more bandwidth than T4 to accelerate AI, data science, engineering simulation, and other GPU memory-intensive workloads.
Structural Sparsity: 2X Higher Performance for AI
Modern AI networks are big, having millions and in some cases billions of parameters. Not all of these parameters are needed for accurate predictions, and some can be converted to zeros to make the models “sparse” without compromising accuracy. Tensor Cores in A30 can provide up to 2X higher performance for sparse models. While the sparsity feature more readily benefits AI inference, it can also improve the performance of model training.
References and further readings:- 1. NVIDIA A30 GPU Accelerator - Product brief 2. A30 Tensor Core GPU for AI Inference | NVIDIA-A30 3. NVIDIA A30 | Datasheet
NVIDIA A30 USE CASES
Deep Learning Inference
A30 leverages groundbreaking features to optimize inference workloads. It accelerates a full range of precisions, from FP64 to TF32 and INT4. Supporting up to four MIGs per GPU, A30 lets multiple networks operate simultaneously in secure hardware partitions with guaranteed quality of service (QoS). And structural sparsity support delivers up to 2X more performance on top of A30’s other inference performance gain
High-Performance Computing
NVIDIA A30 features FP64 NVIDIA Ampere architecture Tensor Cores that deliver the biggest leap in HPC performance since the introduction of GPUs. Combined with 24 gigabytes (GB) of GPU memory with a bandwidth of 933 gigabytes per second (GB/s), researchers can rapidly solve double-precision calculations. HPC applications can also leverage TF32 to achieve higher throughput for single-precision, dense matrix-multiply operations.
High-Performance Data Analytics
Data scientists need to be able to analyze, visualize, and turn massive datasets into insights. But scale-out solutions are often bogged down by datasets scattered across multiple servers.
Accelerated servers with A30 provide the needed compute power—along with large HBM2 memory, 933GB/sec of memory bandwidth, and scalability with NVLink—to tackle these workloads. Combined with NVIDIA InfiniBand, NVIDIA Magnum IO and the RAPIDS™ suite of open-source libraries, including the RAPIDS Accelerator for Apache Spark, the NVIDIA data center platform accelerates these huge workloads at unprecedented levels of performance and efficiency.
A30 GPUs On E2E Cloud
Now that you’ve already started to think of ways how you could utilize Ampere A30 GPUs, why not go with the best-suited cloud-based GPUs to maximize the performance and minimize the total cost of ownership?
Here’s why you should consider using E2E Networks’ A30 GPU Cloud:
All the GPU servers of E2E networks run in Indian datacenters, hence reducing latency.
Powerful hardware deployed along with cutting-edge engineering that renders increased reliability.
Uptime SLAs so that you worry less and do more
Inexpensive pricing plans designed according to the needs of customers.
These features not only make E2E GPU Cloud services stand out from others in the market but it also helps you to stay ahead of your competition by outperforming them.
Get started, pick and choose your best GPU plan